Write-Ahead Log (WAL)
Terms related to simplyblock
A Write-Ahead Log (WAL) is a core component of many data systems designed to ensure durability. Before any changes are applied to the main database or storage engine, they’re first written to a persistent log. This guarantees that even if a crash happens during the write process, the system can recover by replaying the log. WAL is simple in concept but critical in practice for preserving data integrity.
How WAL Works in Real Systems
When a system receives a write operation, it first appends the data to the WAL. This is done using fast, sequential disk I/O. Only after this log entry is confirmed does the system apply the change to the main data files. If something fails in between, the system can recover the change by replaying the WAL entries.
This mechanism is used in databases like PostgreSQL, which treats WAL as the single source of truth for crash recovery. In containerized infrastructure like Kubernetes, WAL also protects stateful sets and persistent workloads during pod restarts or node failures.
🚀 Handle WAL-Heavy Workloads Without Storage Bottlenecks
Let your stateful apps run faster with NVMe storage designed for consistency, replication, and high-throughput writes.
👉 Use Simplyblock for Transactional Storage Backends →
Why WAL Matters in Stateful Workloads
WAL plays a vital role in maintaining consistency for systems that can’t afford data loss—especially those running databases, queues, or journaling file systems. It’s also foundational in Kubernetes storage environments, where durability across distributed nodes is non-negotiable.
Because it logs operations before applying them, WAL makes it safe to delay heavy writes, batch updates, or defer compaction. This improves performance without compromising consistency, a crucial balance for applications that must stay responsive under load.
Real-World Systems That Use WAL
You’ll find WAL embedded in nearly every modern data platform. Here are several examples:
- PostgreSQL – Central to crash recovery and streaming replication
- MySQL (InnoDB) – Uses redo logs for fault tolerance
- Kafka – Ensures message durability before acknowledgment
- RocksDB / LevelDB – Log batch writes for recoverability
- Etcd – Logs every state mutation in Kubernetes control planes
- SQLite (WAL mode) – Improves write concurrency
- ext4 and XFS – File systems using journaling (WAL by another name)
- Kubernetes StatefulSets – Depend on WAL within application containers
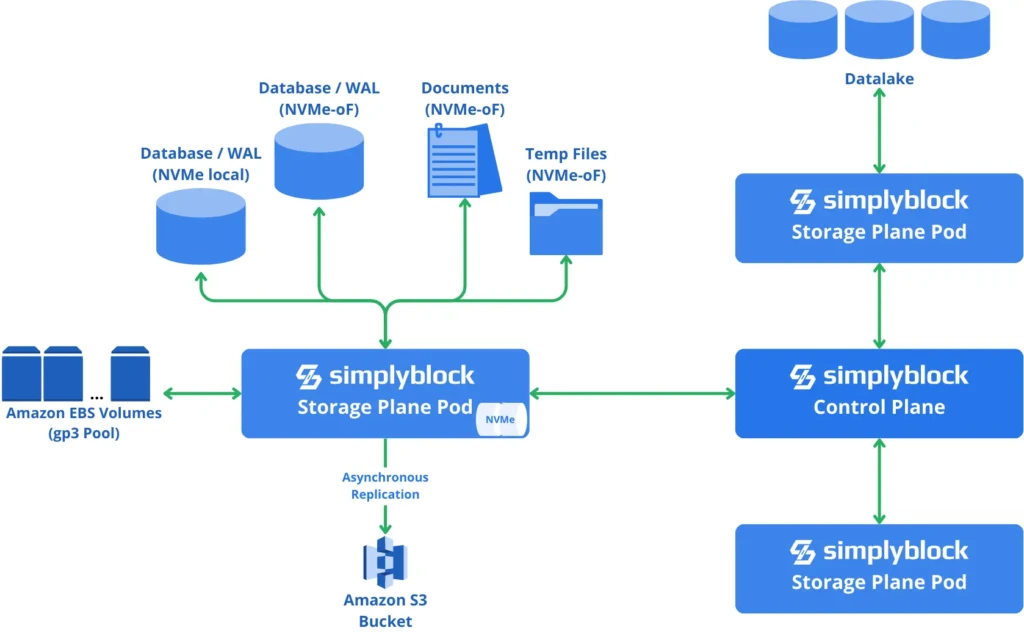
Performance Limits of WAL-Based Storage
WAL systems can bottleneck under pressure. Because every write must hit the log before acknowledgment, the speed of your underlying disk determines how fast your system feels. On slow block storage, write latency rises quickly under sustained load.
This gets worse if WAL files aren’t compacted or archived properly—they’ll grow indefinitely and consume valuable disk space. Systems like PostgreSQL rely heavily on proper WAL tuning to prevent storage bloat and avoid slow recovery times. In such cases, leveraging low-latency NVMe storage or optimized caching becomes necessary.
WAL vs Direct Disk Writes
| Feature | Write-Ahead Log (WAL) | Direct Disk Writes |
|---|---|---|
| Durability | High | Medium |
| Recovery Speed | Fast | Slower |
| Crash Safety | Built-in | May require manual recovery |
| Write Pattern | Sequential | Random |
| Ideal Use Case | Databases, logs, queues | Stateless workloads |
| System Load | Predictable | More variable |
How Simplyblock Enhances WAL Performance
Write-ahead logs rely on the assumption that your storage can keep up. That’s where Simplyblock comes in. With NVMe-over-TCP and SPDK-backed volumes, Simplyblock delivers sub-millisecond write latency, even under pressure. This means your PostgreSQL or MySQL instance won’t stall while waiting for the WAL to flush.
Beyond speed, Simplyblock brings in cost-efficiency. Through thin provisioning, WAL volumes only consume capacity as they’re used, not based on maximum size. Teams can also take instant, zero-copy snapshots of their WAL-heavy volumes, which is perfect for database branching or backups.
If you’re managing persistent workloads across availability zones, Simplyblock’s disaggregated storage architecture ensures your WAL can scale without breaking the system. It’s storage built for workloads where failure is not an option.
Common WAL Issues in Production
Even in well-designed systems, WAL introduces challenges. Latency during commits is common on slower disks or general-purpose cloud volumes. If archiving isn’t tuned right, logs can grow uncontrollably and lead to disk exhaustion. This becomes a bigger problem in multi-tenant clusters or during peak usage.
There’s also operational risk—like crash loops caused by partial WAL replays during pod restarts, or lagging replicas during failover. Observability is another weak spot. Most teams don’t track WAL-specific metrics until recovery gets slow.
Modern infrastructure teams are solving these problems by pairing WAL-intensive systems with fast storage platforms like Simplyblock. You get durability, performance, and observability—without the traditional operational cost. Platforms built for database performance optimization now consider WAL performance a core metric.
Questions and Answers
Write-Ahead Logs (WALs) require rapid, sequential writes to ensure durability and consistency. Any delay in I/O impacts database transaction speed. Platforms like Simplyblock NVMe-over-TCP are ideal, as they minimize write latency and ensure fast fsync operations.
WAL logs every operation before it’s committed to the main database. This guarantees data recovery after a crash and preserves ACID properties. It’s widely used in systems like PostgreSQL, MySQL, and distributed stores like etcd.
Absolutely. WAL workloads involve small, frequent writes. NVMe’s high throughput and low tail latency—especially via software-defined storage—make it perfect for write-heavy systems like databases or Kafka brokers.
Use persistent volumes backed by fast SSD or NVMe, isolate WAL writes on separate volumes, and avoid network-attached storage with high latency. Kubernetes-native CSI solutions with NVMe-over-TCP improve WAL performance significantly.
WAL is a form of journaling optimized for transactional systems. It logs intent first, then executes, whereas traditional journaling logs filesystem changes. For databases, WAL provides more control and rollback capability.