
Table Of Contents
- The Database Dilemma: Managed Services or Self-Managed?
- The Power of Self-Managed Kubernetes Databases
- Where are the Savings Coming from when using Kubernetes for your Database Management?
- Breaking down the Numbers: a Cost Comparison between PostgreSQL on RDS vs EKS
- Total Estimated Annual Benefit of Self-Hosting
- Beyond the Dollar Signs: the Real Value Proposition
- Is the Database on Kubernetes for Everyone?
- Bonus: Simplyblock
- Conclusion: the True Cost Revealed
Databases can make up a significant portion of the costs for a variety of businesses and enterprises, and in particular for SaaS, Fintech, or E-commerce & Retail verticals. Choosing the right database management solution can make or break your business margins. But have you ever wondered about the true cost of your database management? Is your current solution really as cost-effective as you think? Let’s dive deep into the world of database management and uncover the hidden expenses that might be eating away at your bottom line.
The Database Dilemma: Managed Services or Self-Managed?
The first crucial decision comes when choosing the operating model for your databases: should you opt for managed services like AWS RDS or take the reins yourself with a self-managed solution on Kubernetes? It’s not just about the upfront costs – there’s a whole iceberg of expenses lurking beneath the surface.
The Allure of Managed Services
At first glance, managed services like AWS RDS seem to be a no-brainer. They promise hassle-free management, automatic updates, and round-the-clock support. But is it really as rosy as it seems?
The Visible Costs
- Subscription Fees : You’re paying for the convenience, and it doesn’t come cheap.
- Storage Costs : Every gigabyte counts, and it adds up quickly.
- Data Transfer Fees : Moving data in and out? Be prepared to open your wallet.
The Hidden Expenses
- Overprovisioning : Are you paying for more than you are actually using?
- Personnel costs : Using RDS and assuming that you don’t need to understand databases anymore? Surprise! You still need team that will need to configure the database and set it up for your requirements.
- Performance Limitations : When you hit a ceiling, scaling up can be costly.
- Vendor Lock-in : Switching providers? That’ll cost you in time and money.
- Data Migration : Moving data between services can cost a fortune.
- Backup and Storage : Those “convenient” backups? They’re not free. In addition, AWS RDS does not let you plug in other storage solution than AWS-native EBS volumes, which can get quite expensive if your database is IO-intensive

The Power of Self-Managed Kubernetes Databases
On the flip side, managing your databases on Kubernetes might seem daunting at first. But let’s break it down and see where you could be saving big.
Initial Investment
- Learning Curve : Yes, there’s an upfront cost in time and training. You need to have on your team engineers that are comfortable with Kubernetes or Amazon EKS.
- Setup and Configuration : Getting things right takes effort, but it pays off.
Long-term Savings
- Flexibility : Scale up or down as needed, without overpaying.
- Multi-Cloud Freedom : Avoid vendor lock-in and negotiate better rates.
- Resource Optimization : Use your hardware efficiently across workloads.
- Resource Sharing : Kubernetes lets you efficiently allocate resources.
- Open-Source Tools : Leverage free, powerful tools for monitoring and management.
- Customization : Tailor your setup to your exact needs, no compromise.
Where are the Savings Coming from when using Kubernetes for your Database Management?
In a self-managed Kubernetes environment, you have greater control over resource allocation, leading to improved utilization and efficiency. Here’s why:
a) Dynamic Resource Allocation : Kubernetes allows for fine-grained control over CPU and memory allocation. You can set resource limits and requests at the pod level, ensuring databases only use what they need. Example: During off-peak hours, you can automatically scale down resources, whereas in managed services, you often pay for fixed resources 24/7.
b) Bin Packing : Kubernetes scheduler efficiently packs containers onto nodes, maximizing resource usage. This means you can run more workloads on the same hardware, reducing overall infrastructure costs. Example: You might be able to run both your database and application containers on the same node, optimizing server usage.
c) Avoid Overprovisioning : With managed services, you often need to provision for peak load at all times. In Kubernetes, you can use Horizontal Pod Autoscaling to add resources only when needed. Example: During a traffic spike, you can automatically add more database replicas, then scale down when the spike ends.
d) Resource Quotas : Kubernetes allows setting resource quotas at the namespace level, preventing any single team or application from monopolizing cluster resources. This leads to more efficient resource sharing across your organization.
Self-managed Kubernetes databases can also significantly reduce data transfer costs compared to managed services. Here’s how:
a) Co-location of Services : In Kubernetes, you can deploy your databases and application services in the same cluster. This reduces or eliminates data transfer between zones or regions, which is often charged in managed services. Example: If your app and database are in the same Kubernetes cluster, inter-service communication doesn’t incur data transfer fees.
b) Efficient Data Replication : Kubernetes allows for more control over how and when data is replicated. You can optimize replication strategies to reduce unnecessary data movement. Example: You might replicate data during off-peak hours or use differential backups to minimize data transfer.
c) Avoid Provider Lock-in : Managed services often charge for data egress, especially when moving to another provider. With self-managed databases, you have the flexibility to choose the most cost-effective data transfer methods. Example: You could use direct connectivity options or content delivery networks to reduce data transfer costs between regions or clouds.
d) Optimized Backup Strategies : Self-managed solutions allow for more control over backup processes. You can implement incremental backups or use deduplication techniques to reduce the amount of data transferred for backups. Example: Instead of full daily backups (common in managed services), you might do weekly full backups with daily incrementals, significantly reducing data transfer.
e) Multi-Cloud Flexibility : Self-managed Kubernetes databases allow you to strategically place data closer to where it’s consumed. This can reduce long-distance data transfer costs, which are often higher. Example: You could have a primary database in one cloud and read replicas in another, optimizing for both performance and cost.
By leveraging these strategies in a self-managed Kubernetes environment, organizations can significantly optimize their resource usage and reduce data transfer costs, leading to substantial savings compared to typical managed database services.

Breaking down the Numbers: a Cost Comparison between PostgreSQL on RDS vs EKS
Let’s get down to brass tacks. How do the costs really stack up? We’ve crunched the numbers for a small Postgres database between using managed RDS service and hosting on Kubernetes. For Kubernetes we are using EC2 instances with local NVMe disks that are managed on EKS and simplyblock as storage orchestration layer.
Scenario: 3TB Postgres Database with High Availability (3 nodes) and Single AZ Deployment
Managed Service (AWS RDS) using three Db.m4.2xlarge on Demand with Gp3 Volumes
Available resources
Costs
Available vCPU: 8 Available Memory: 32 GiB Available Storage: 3TB Available IOPS: 20,000 per volume Storage latency: 1-2 milliseconds
Monthly Total Cost: $2511,18
3-Year Total: $2511,18 * 36 months = $90,402
Editorial: See the pricing calculator for Amazon RDS for PostgreSQL
Self-Managed on Kubernetes (EKS) using three i3en.xlarge Instances on Demand
Available resources
Costs
Available vCPU: 12 Available Memory: 96 GiB Available
Storage: 3.75TB (7.5TB raw storage with assumed 50% data protection overhead for simplyblock) Available IOPS: 200,000 per volume (10x more than with RDS) Storage latency: below 200 microseconds (local NVMe disk orchestrated by simplyblock)
Monthly instance cost: $989.88 Monthly storage orchestration cost (e.g. Simplyblock): $90 (3TB x $30/TB)
Monthly EKS cost: $219 ($73 per cluster x 3)
Monthly Total Cost: $1298.88
3-Year Total: $1298.88 x 36 months = $46,759 Base Savings : $90,402 – $46,759 = $43,643 (48% over 3 years)
That’s a whopping 48% saving over three years! But wait, there’s more to consider. We have made some simplistic assumptions to estimate additional benefits of self-hosting to showcase the real potential of savings. While the actual efficiencies may vary from company to company, it should at least give a good understanding of where the hidden benefits might lie.
Additional Benefits of Self-Hosting (Estimated Annual Savings)
- Resource optimization/sharing : Assumption: 20% better resource utilization (assuming existing Kubernetes clusters) Estimated Annual Saving: 20% x 989.88 x 12= $2,375
- Reduced Data Transfer Costs : Assumption: 50% reduction in data transfer fees Estimated Annual Saving: $2,000
- Flexible Scaling : Avoid over-provisioning during non-peak times Estimated Annual Saving: $3,000
- Multi-Cloud Strategy : Ability to negotiate better rates across providers Estimated Annual Saving: $5,000
- Open-Source Tools : Reduced licensing costs for management tools Estimated Annual Saving: $4,000
Disaster Recovery Insights
- RTO (Recovery Time Objective) Improvement : Self-managed: Potential for 40% faster recovery Estimated value: $10,000 per hour of downtime prevented
- RPO (Recovery Point Objective) Enhancement : Self-managed: Achieve near-zero data loss Estimated annual value: $20,000 in potential data loss prevention
Total Estimated Annual Benefit of Self-Hosting
Self-hosting pays off. Here is the summary of benefits: Base Savings: $8,400/year Additional Benefits: $15,920/year Disaster Recovery Improvement: $30,000/year (conservative estimate)
Total Estimated Annual Additional Benefit: $54,695
Total Estimated Additional Benefits over 3 Years: $164,085
Note: These figures are estimates and can vary based on specific use cases, implementation efficiency, and negotiated rates with cloud providers.
Beyond the Dollar Signs: the Real Value Proposition
Money talks, but it’s not the only factor in play. Let’s look at the broader picture.
Performance and Scalability
With self-managed Kubernetes databases, you’re in the driver’s seat. Need to scale up for a traffic spike? Done. Want to optimize for a specific workload? You’ve got the power.
Security and Compliance
Think managed services have the upper hand in security? Think again. With self-managed solutions, you have granular control over your security measures. Plus, you’re not sharing infrastructure with unknown entities.
Innovation and Agility
In the fast-paced tech world, agility is king. Self-managed solutions on Kubernetes allow you to adopt cutting-edge technologies and practices without waiting for your provider to catch up.
Is the Database on Kubernetes for Everyone?
Definitely not. While self-managed databases on Kubernetes offer significant benefits in terms of cost savings, flexibility, and control, they’re not a one-size-fits-all solution. Here’s why:
- Expertise: Managing databases on Kubernetes demands a high level of expertise in both database administration and Kubernetes orchestration. Not all organizations have this skill set readily available. Self-management means taking on responsibilities like security patching, performance tuning, and disaster recovery planning. For smaller teams or those with limited DevOps resources, this can be overwhelming.
- Scale of operations : For simple applications with predictable, low-to-moderate database requirements, the advanced features and flexibility of Kubernetes might be overkill. Managed services could be more cost-effective in these scenarios. Same applies for very small operations or startups in early stages – the cost benefits of self-managed databases on Kubernetes might not outweigh the added complexity and resource requirements.
While database management on Kubernetes offers compelling advantages, organizations must carefully assess their specific needs, resources, and constraints before making the switch. For many, especially larger enterprises or those with complex, dynamic database requirements, the benefits can be substantial. However, others might find that managed services better suit their current needs and capabilities.
Bonus: Simplyblock
There is one more bonus benefit that you get when running your databases in Kubernetes – you can add simplyblock as your storage orchestration layer behind a single CSI driver that will automatically and intelligently serve storage service of your choice. Do you need fast NVMe cache for some hot transactional data with random IO but don’t want to keep it hot forever? We’ve got you covered!
Simplyblock is an innovative cloud-native storage product, which runs on AWS, as well as other major cloud platforms. Simplyblock virtualizes, optimizes, and orchestrates existing cloud storage services (such as Amazon EBS or Amazon S3) behind a NVMe storage interface and a Kubernetes CSI driver. As such, it provides storage for compute instances (VMs) and containers. We have optimized for IO-heavy database workloads, including OLTP relational databases, graph databases, non-relational document databases, analytical databases, fast key-value stores, vector databases, and similar solutions.
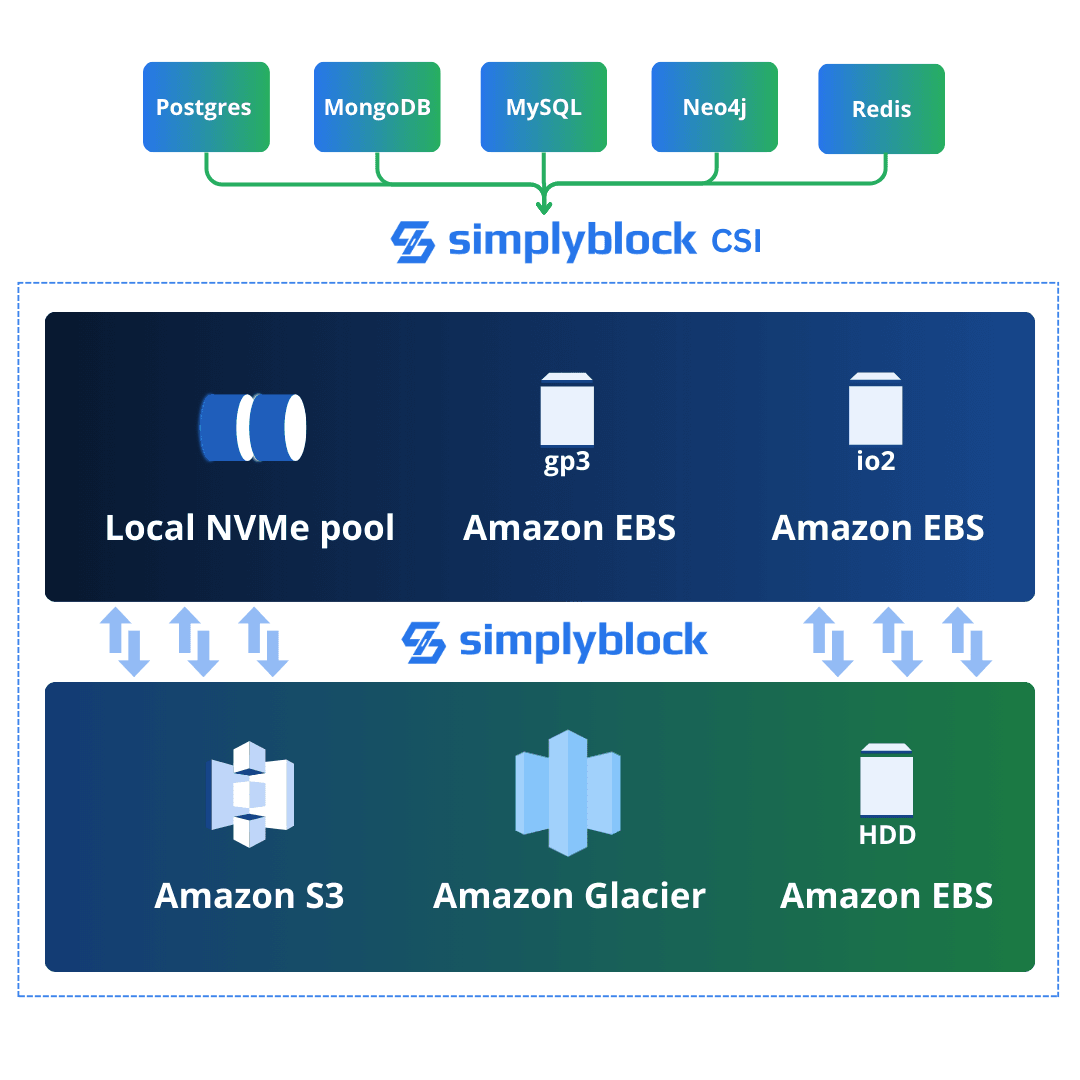
This optimization has been built from the ground up to orchestrate a wide range of database storage needs, such as reliable and fast (high write-IOPS) storage for write-ahead logs and support for ultra-low latency, as well as high IOPS for random read operations. Simplyblock is highly configurable to optimally serve the different database query engines.
Some of the key benefits of using simplyblock alongside your stateful Kubernetes workloads are:
- Cost Reduction, Margin Increase: Thin provisioning, compression, deduplication of hot-standby nodes, and storage virtualization with multiple tenants increases storage usage while enabling gradual storage increase.
- Easy Scalability of Storage: Single node databases require highly scalable storage (IOPS, throughput, capacity) since data cannot be distributed to scale. Simplyblock pools either Amazon EBS volumes or local instance storage from EC2 virtual machines and provides a scalable and cost effective storage solution for single node databases.
- Enables Database Branching Features: Using instant snapshots and clones, databases can be quickly branched out through database branching and provided to customers. Due to copy-on-write, the storage usage doesn’t increase unless the data is changed on either the primary or branch. Customers could be charged for “additional storage” though.
- Enhances Security: Using an S3-based streaming of a recovery journal, the database can be quickly recovered from full AZ and even region outages. It also provides protection against typical ransomware attacks where data gets encrypted by enabling Point-in-Time-Recovery down to a few hundred milliseconds granularity.

Conclusion: the True Cost Revealed
When it comes to database management, the true cost goes far beyond the monthly bill. By choosing a self-managed Kubernetes solution, you’re not just saving money – you’re investing in flexibility, performance, and future-readiness. The savings and benefits will be always use-case and company-specific but the general conclusion shall remain unchanged. While operating databases in Kubernetes is not for everyone, for those who have the privilege of such choice, it should be a no-brainer kind of decision.
While there is a learning curve, modern tools and platforms like simplyblock significantly simplify the process, often making it more straightforward than dealing with the limitations of managed services. The knowledge acquired in the process can be though re-utilized across different cloud deployments in different clouds.
Kubernetes offers robust features for high availability, including automatic failover and load balancing. With proper configuration, you can achieve even higher availability than many managed services offer, meeting any possible SLA out there. You are in full control of the SLAs.
While migration requires careful planning, tools and services exist to streamline the process. Many companies find that the long-term benefits far outweigh the short-term effort of migration.
Simplyblock provides automated, space-efficient backup solutions that integrate seamlessly with Kubernetes. Our point-in-time recovery feature allows you to restore your database to any specific moment, offering protection against data loss and ransomware attacks.
Yes, simplyblock supports a wide range of database types including relational databases like PostgreSQL and MySQL, as well as NoSQL databases like MongoDB and Cassandra. Check out our “Supported Technologies” page for a full list of supported databases and their specific features.


