
Earlier this week, I commented on a Linkedin post that stirred quite a debate:
“PostgreSQL should not be run on Kubernetes in production for critical data workloads.”
That statement got people talking. Some agreed immediately, citing their struggles with k8s. Others pushed back, pointing out that there are Kubernetes Operators, such as CNPG, that make it very easy to run Postgres on Kubernetes. In some way, they are both right.
Kubernetes has become the de facto substrate for running distributed, scalable, and multi-tenant Postgres. It’s how modern “serverless” databases achieve elasticity and isolation. Yet, for most teams, managing Postgres on Kubernetes themselves introduces more pain than it’s worth. It demands operational depth that few organizations possess, especially when uptime, data integrity, and performance are on the line.
That tension between Kubernetes as a brilliant orchestration platform and Postgres as a stability-loving database is what inspired this piece. It’s also the reason why we’re launching Vela.
Why Kubernetes Took Over the Database World
To understand why Kubernetes became so popular for database workloads, we have to start with what it gets right. Kubernetes enables dynamic scheduling, declarative infrastructure, and automated scaling. It lets you treat environments as code, spin up test clusters in minutes, and isolate workloads across tenants. These capabilities are gold for distributed systems.
For Postgres specifically, Kubernetes enables something most cloud databases need: elasticity. The ability to scale compute and storage independently, spin up ephemeral environments, and manage multiple Postgres clusters consistently is essential for a DBaaS model. That’s why nearly every modern Postgres DBaaS, from Neon to Aiven to EDB, relies on Kubernetes to run and orchestrate database instances.
The model works beautifully in theory. In practice, though, it comes with a price: complexity. Databases are stateful, and Kubernetes was designed first for stateless workloads. That mismatch introduces several layers of abstraction and each layer is a potential point of failure.
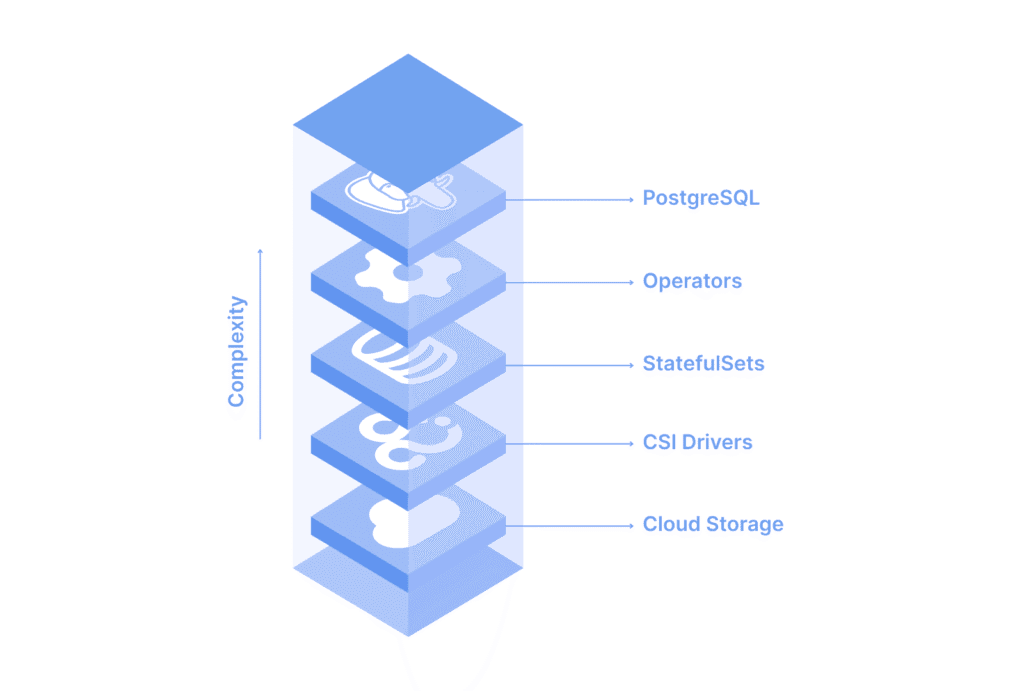
A Tower of Abstractions
Running Postgres on Kubernetes involves stacking components that each do one small job. You have StatefulSets and Operators to manage database lifecycles, Persistent Volumes and CSI drivers to handle storage, and sidecar containers for monitoring and backups. Between Postgres and the underlying operating system sits a labyrinth of controllers, manifests, and configurations.
Every one of those layers increases flexibility. But also complexity. And when something goes wrong, finding the root cause requires navigating through this entire stack. If replication lags behind, is it Postgres itself? Is it the storage class? Is it the CSI driver? Or is it the way pods are being rescheduled? Each layer adds uncertainty.
When Kubernetes Creates More Problems Than It Solves
Running Postgres in Kubernetes is possible. But running it well, in production, at scale—that’s another story.
Let’s say you build your own Postgres operator stack. You’re now managing Persistent Volume Claims, network throughput between pods, pod eviction and rescheduling rules, data replication strategies, and versioned StatefulSets. You’re monitoring multiple storage backends while ensuring your backups and failovers work seamlessly across all of them.
Even small configuration errors can create cascading problems. For example, an aggressive eviction policy might restart a pod during high load. That pod might lose its volume mount, forcing Postgres into crash recovery. At that moment, your team isn’t debugging SQL. They’re debugging YAML.
Kubernetes operators like CPNG or Zalando Operator make this process easier, but they don’t remove the underlying complexity. They add another abstraction layer. One more moving part that can fail. The deeper you go, the more you find yourself managing infrastructure, not data.
Databases thrive on stability. Kubernetes thrives on abstraction. Together, they can work but it takes a black-belt-level engineering effort to make them coexist smoothly.
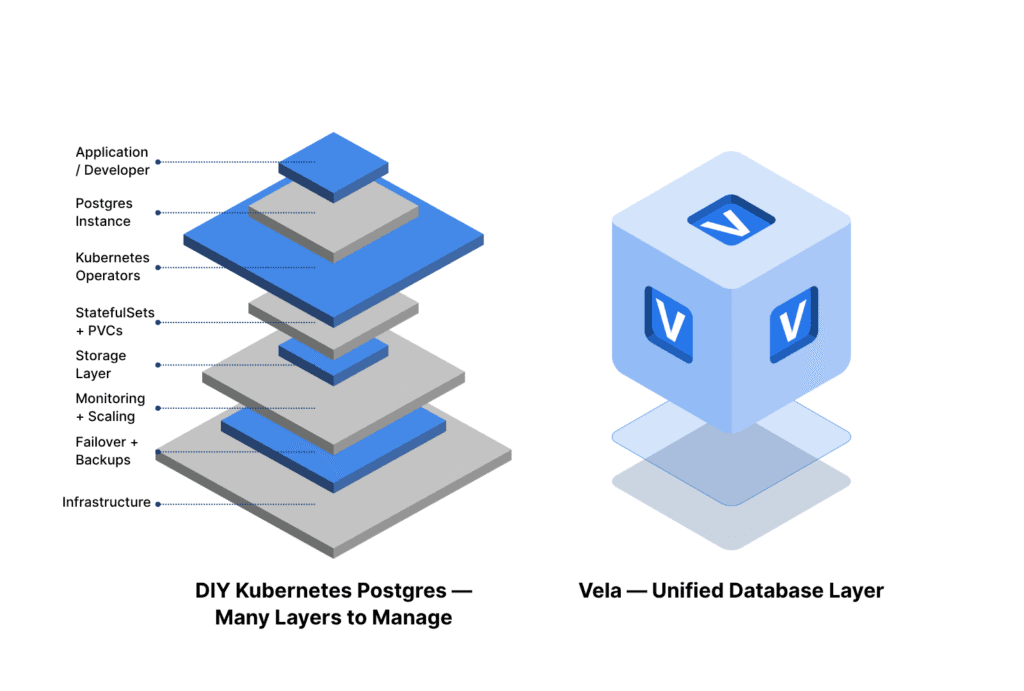
Vela’s Approach: Power of Kubernetes, Without the Pain
At Vela, we took a different approach. We recognize that Kubernetes is an incredible orchestration layer for distributed systems, but we also believe no developer or data team should ever have to touch it to run Postgres at scale.
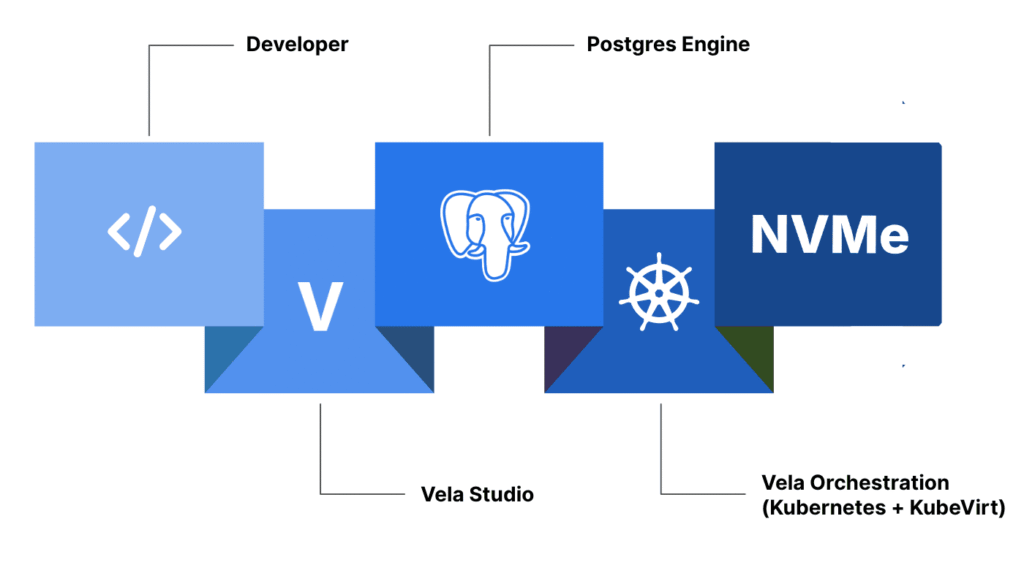
Vela runs on Kubernetes under the hood, but you never interact with it directly. Instead, you work with a unified platform that integrates Postgres, storage, orchestration, and compute management into a single experience. We bundle Kubernetes, operators, and the underlying infrastructure into an invisible layer that “just works.”
From the outside, Vela behaves like a next-generation Postgres BaaS. Inside, it’s a tightly engineered system optimized for performance, reliability, and scale.
Every Vela environment comes with:
- Managed Postgres instances powered by high-performance NVMe storage
- Instant copy-on-write cloning for branches and tests
- Automated scaling and failover
- Git-like workflows for database branching and merging
- Built-in monitoring, RBAC, and high availability
Because Vela uses Kubernetes and KubeVirt internally, you still get the benefits of orchestration, elasticity, and fault tolerance. But you never have to manage a StatefulSet, write a YAML manifest, or configure a Persistent Volume Claim. That entire operational burden disappears.
Why This Matters for AI Workloads
AI teams face unique challenges when it comes to databases. Their data workloads are not static. They rather involve a blend of transactional, analytical, and vector operations. Model training, feature extraction, embedding generation, and real-time inference all depend on a database that can scale dynamically, handle high I/O throughput, and replicate environments instantly.
Traditional Postgres deployments make this difficult. You either overprovision infrastructure to handle peak workloads or waste hours cloning and refreshing staging data. Kubernetes can help. But again, managing those clusters adds friction and slows iteration.
Vela changes this. It was designed specifically for AI builders who need branchable, cloneable, and high-performance Postgres environments. With Vela, you can spin up an isolated database branch from production in seconds. You can run experiments, train models, or test vector search queries without touching the original dataset. When you’re done, you can merge or discard those changes. Just like working with Git branches.
This workflow is ideal for machine learning pipelines. Each model version gets its own environment. Each branch contains the exact data snapshot needed for training or evaluation. The result is faster iteration, safer testing, and fully reproducible experiments. Without Kubernetes expertise or DBA overhead.
Built for Simplicity, Engineered for Scale
Vela combines managed Postgres with distributed NVMe storage (powered by simplyblock) and an intelligent orchestration layer. This architecture delivers the elasticity of Kubernetes with the predictability and performance of bare metal.
Postgres on Vela runs directly on NVMe-backed nodes, delivering millions of IOPS and sub-millisecond latency. That means you can run transactional and analytical workloads side by side without performance cliffs. And because compute and storage scale independently, you can right-size each environment for its purpose. For example: large instances for production, small ones for staging or training.
Vela’s copy-on-write technology also reduces waste. Instead of duplicating entire datasets for staging or testing, Vela creates thin clones that share base data. You only pay for the differences. Our experience tells us that it typically cuts infrastructure footprint from six full-size environments to just about two.
Using Vela you can expect to see up to a 80% reduction in total cost and up to 85% drop in platform engineering time. While these improvements seem unbelievably good, the engineers working closely with Kubernetes should easily understand how it comes together. What used to require a dedicated SRE, Senior Platform Engineer, or DBA now happens automatically through the Vela Studio interface.
The Hidden Benefit: Stability and Predictability
While performance and cost are major wins, the biggest advantage of removing Kubernetes complexity is stability. Databases need predictable behavior. They should not depend on external orchestration layers that can misfire under load or after an upgrade.
By making Kubernetes invisible, Vela restores that predictability. You get automated scaling and failover powered by Kubernetes, but the system shields you from its volatility. Everything feels like a single, coherent platform. Not like a patchwork of containers, manifests, and operators.
AI Builders, This Is Your Database Platform
If you are building AI-driven products, your database is more than just a storage layer. It’s the foundation of your training data, feature pipelines, and vector search. You need a system that lets you move fast without sacrificing reliability.
Vela is that system. It gives you:
- A Postgres database platform that runs anywhere you do: AWS, GCP, Azure, or on-prem.
- “More than a Postgres” set of features: full backend around PostgreSQL, including auth, RLS, real-time or edge functions
- Instant cloning and branching for fast iteration.
- High-performance distributed NVMe storage for demanding workloads.
- The full power of Kubernetes without ever needing to touch it.
You get a Postgres BaaS designed for AI builders who care about speed, cost, and simplicity.
The Takeaway
Kubernetes revolutionized how we orchestrate compute. But for databases, it often adds more operational weight than value. Unless it’s managed by a system or operator that hides its complexity.
That’s exactly what Vela does. It keeps the benefits of Kubernetes (elasticity, isolation, automation) but removes every manual step that makes it hard to use. The result is a Postgres platform that’s faster, leaner, and far simpler to operate.
For teams building AI applications, that simplicity is everything. Less time spent managing infrastructure means more time iterating on data, models, and insights.
So, should you run Postgres on Kubernetes? Kubernetes can run Postgres beautifully, as long as you don’t have to manage it yourself. That’s exactly what Vela takes care of.
👉 Try the Vela | Calculate Your Savings | Book a Demo | Contribute