
Table Of Contents
- What is a DPU
- Why DPUs matter for storage performance and CPU efficiency
- Offload and Acceleration with DPUs
- What tasks can be offloaded to DPUs?
- SPDK and Arm: why it pairs well with DPU architectures
- Why DPUs matter specifically for NVMe/TCP storage
- DPUs, GPUs and high-performance AI workloads
- How to decide if DPU helps your storage stack
- DPU and IPU cards you can use today
- How simplyblock fits into DPU and IPU deployments
- Final takeaways
- FAQs
Data centers changed faster than most storage stacks. NVMe SSDs became standard. Ethernet became faster and cheaper. Kubernetes became the default platform for new infrastructure.
At the same time, host CPUs became the dumping ground for “everything else.” Your CPU runs application threads. It also runs the network stack and storage path. It often runs security functions too. This extra work is not free, and it shows up as wasted cores and noisy tail latency.
That is why DPUs matter for storage teams. A DPU can move data-path work off the host. It can also enforce isolation between infrastructure and workloads. In software-defined storage, that changes how you design and scale.
This post explains what DPUs are, and why they matter for storage. It connects DPUs to SPDK, Arm-based execution, acceleration, and offload. It also frames where DPUs fit in simplyblock deployments.
What is a DPU
A DPU, or Data Processing Unit, is a specialized processor built for data-centric tasks. Those tasks typically include networking, storage requests, and security processing. The goal is to offload this work from the CPU.
In practice, a DPU is usually three things in one device. It has a high-performance NIC. It has dedicated compute cores. It has accelerators for infrastructure functions.
A DPU usually includes meaningful on-board compute, often with a full Linux environment. Most modern DPUs include Arm cores. Those cores run a real OS and user-space services. That makes the device useful beyond fixed-function offloads. You can move parts of your storage data path onto the DPU. You can also isolate infrastructure from application tenants.
Many vendors describe the same category with different names. Intel uses the term IPU, or Infrastructure Processing Unit. Nvidia uses the term DPU, or Data Processing Unit. As an example, Intel positions the IPU as a way to provide virtualized network and storage functionality with lower host overhead.
The label matters less than the architecture. You want a device that can run infrastructure code close to the wire. You also want it to operate independently from the host. The common theme is simple. DPUs move “platform work” away from the host CPU. That is exactly where storage pain often sits today.
Why DPUs matter for storage performance and CPU efficiency
Storage performance used to be constrained by disks. However, NVMe drives got extremely fast. Networks got extremely fast too. NVMe devices can deliver massive parallelism and NVMe-oF protocol can extend that performance across the network. As a result, modern software-defined block storage is often limited by software overhead, not media speed.
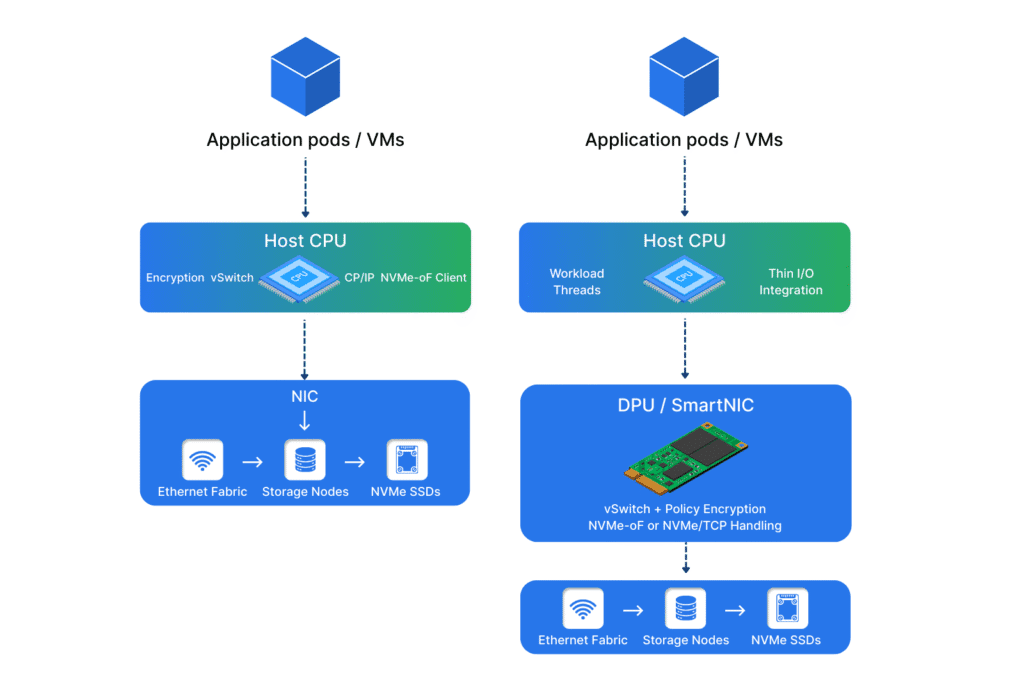
In a typical NVMe/TCP setup, the host runs the network stack. It also runs the NVMe-oF client path. It may run encryption and policy too. In Kubernetes, it also runs kubelet and other node agents. Those pieces compete for the same CPU cycles. It results in the host CPU still doing too much “data plumbing.”

That plumbing includes TCP or RDMA processing, storage protocol work, encryption, and virtual switching. It also includes kernel crossings and memory copies. Those costs show up as higher p99 latency and higher CPU burn. In Kubernetes, that jitter becomes more visible. Nodes are shared by many pods. Background tasks fight for CPU time. Network and storage work gets interrupted by unrelated bursts.
A DPU changes that balance by running data-path services outside the host, which reduces CPU contention and improves isolation.
Offload and Acceleration with DPUs
People often use “offload” and “acceleration” as synonyms. They are related, but they are not identical.
Offload means the host stops doing the work. The DPU does it instead. The win is usually immediate CPU savings.
Acceleration means the work finishes faster. This can happen through hardware engines. It can also happen through better placement and fewer software layers.
In storage, you often want both. You want fewer host cycles per I/O. You also want fewer microbursts and less jitter in the data path.
A good DPU strategy often delivers both. You offload protocol work and security work. You also accelerate packet steering and data movement. The combined effect improves throughput and stabilizes p99.
What tasks can be offloaded to DPUs?
DPU offload can be broad or narrow. Some environments use it mainly for network virtualization. Others push storage protocol handling onto the DPU. Many start with security offload and expand later.
Here are common storage-adjacent functions that teams offload to DPU-class hardware.
- Packet steering, virtual switching, and policy enforcement near the NIC.
- Crypto work, including IPsec and TLS termination, for storage and service traffic.
- Storage protocol processing, such as NVMe-oF initiator or target components.
- Data-path services that benefit from isolation, such as multi-tenant rate limiting.
These are not theoretical use cases. NVIDIA describes BlueField DPUs as Arm-based programmable CPUs plus a ConnectX NIC and infrastructure accelerators. NVIDIA explicitly calls out offloading software-defined storage from the host CPU.
SPDK and Arm: why it pairs well with DPU architectures
SPDK and DPUs
SPDK, the Storage Performance Development Kit, is a core building block in modern SDS designs. SPDK provides tools and libraries for writing high-performance, scalable, user-mode storage applications.
SPDK aims to reduce overhead in the hot path. It moves drivers into userspace and often uses polling instead of interrupts. This approach avoids kernel context switches and interrupt handling overhead.
That design aligns with DPU thinking. A DPU is a place to run data-path code close to the network. If you already have a user-space storage stack, you can sometimes place more of it on the DPU. You can also keep the host CPU focused on workloads.
You do not need a DPU to benefit from SPDK, though. Many SDS products, including simplyblock, already use SPDK on x86 servers. The point is that DPUs expand your placement options. You can put more of the data path closer to the NIC.
Arm cores and DPUs
Arm cores are common in DPUs for practical reasons. They deliver good performance per watt. They also support rich software stacks. That combination matters for storage because offload is not one feature. Offload becomes a platform.
With Arm cores, you can run control agents on the DPU. You can run data-path services too. You can also run security services and telemetry. That reduces host load and reduces interference with workloads.
From a storage perspective, Arm matters for two reasons. First, you can run Linux services on the DPU, not just firmware. Second, you can run real software stacks in isolation from the host.
That isolation is valuable for enterprise data storage. It reduces the blast radius of workload spikes. It also supports multi-tenant controls that are harder on shared host CPUs.
Why DPUs matter specifically for NVMe/TCP storage
NVMe/TCP is popular because it runs on standard Ethernet. It allows remotely attached NVMe semantics without requiring specialized fabrics. Simplyblock emphasizes NVMe/TCP as a modern successor to iSCSI in many environments.
However, TCP processing still consumes CPU. At high IOPS and high bandwidth, that overhead becomes visible. This is where DPUs can help in NVMe/TCP storage designs.
A DPU helps because it can offload parts of TCP processing. It can also enforce policy and security inline. That reduces host overhead and stabilizes latency. This matters most when you push high IOPS per node.
It can also host infrastructure services that would otherwise compete with workloads. This is especially relevant in Kubernetes clusters with many tenants and unpredictable traffic.
Kubernetes storage creates many parallel clients. It also creates bursty traffic patterns. Those patterns amplify contention on shared nodes. That is why Kubernetes storage often needs extra isolation.
DPUs fit this “adaptive” mindset. In hyper-converged setups, DPUs can reduce host overhead on storage-heavy nodes. In disaggregated setups, DPUs can reduce protocol and policy cost on compute nodes.
This is particularly helpful for multi-tenant platforms. The more tenants share nodes, the more you need strong isolation. A DPU can create a clear boundary between infrastructure and workloads.
DPUs, GPUs and high-performance AI workloads
AI infrastructure pushes storage differently than classic enterprise workloads. Training jobs stream large datasets. Feature pipelines read and write continuously. GPU nodes are expensive, and their CPU cycles matter.
If your host CPU spends time on infrastructure plumbing, you waste expensive compute. If your tail latency is noisy, you introduce stalls that can starve GPUs.
DPUs help by moving infrastructure work off the host. They also help keep the data path stable under pressure. This is one reason DPUs are discussed in modern AI data center designs.
How to decide if DPU helps your storage stack
DPUs are not mandatory for every SDS deployment. They potentially add some cost and operational surface area. They also add real headroom when the CPU becomes the bottleneck.
You can usually predict ROI with three measurements. You measure host CPU per I/O. You measure p95 and p99 latency under contention. You measure throughput at the same workload mix.
Here is a simple evaluation checklist that works well for block storage teams.
- You see high host CPU during storage peaks, while workload CPU remains stable.
- You see p99 latency spikes during node pressure events or multi-tenant bursts.
- You run NVMe/TCP storage at high IOPS, and TCP overhead becomes visible.
- You need stronger isolation between infrastructure services and tenant workloads.
If you hit two of these, a DPU pilot is usually worthwhile. You should run the pilot with one workload class. You should also include operational metrics in the result.
DPU and IPU cards you can use today
Many teams want something concrete to evaluate. These are widely available DPU and IPU-class platforms. I am listing sources that include product pages or briefs.
- NVIDIA BlueField-3 DPU (up to 400Gb/s, infrastructure offload focus)
- AMD Pensando DPUs (Giglio and Elba families, P4 programmable, dual 200Gb/s class)
- Intel IPU E2100 and E2200
If you evaluate these cards, you should recognize a pattern. The silicon differs, but the goal is consistent. You move infrastructure work off the host. You also gain a programmable enforcement point at the edge.
How simplyblock fits into DPU and IPU deployments
Simplyblock is designed to run on DPUs and IPUs can place its full data plane as a storage pod on the IPU or DPU. It can also provide out-of-the-box RDMA or RoCEv2 offload and the TCP stack offload.
In the extreme, you can theoretically run an entire simplyblock storage cluster on DPUs, using the DPU cores for the control and data services and using attached NVMe for capacity. Whether you do that in practice depends on scale, DPU resources, and operational preference, but the point is that the DPU is a viable host for the full SDS stack, not only a helper card.
Being built around software-defined storage and open protocols, it makes hardware choices more flexible over time. It also makes acceleration options easier to adopt.
That matters for DPUs because offload strategies evolve. Some teams start with host-based NVMe/TCP and add DPUs later. Others design DPU usage from day one. A standard-based SDS approach makes those shifts easier.
You can use transport offloads when they help. You can keep storage services in software where you need flexibility. You can also mix hyperconverged and disaggregated tiers in one cluster.
For infrastructure teams, this approach reduces lock-in risk. It also keeps performance close to metal.
Final takeaways
DPUs matter because storage stacks increasingly compete with workloads for CPU. DPUs also matter because Kubernetes and AI make performance variance more visible. SPDK matters because it reduces software overhead and keeps data paths efficient. Arm matters because DPUs run real infrastructure services on dedicated cores.
If you are building software-defined storage for Kubernetes, DPUs give you a new lever. You can offload transport and security first. You can then decide how far you want to push storage services onto the DPU. The right choice depends on your workloads, your density targets, and your tolerance for operational complexity.
FAQs
DPUs do not replace SDS. They change where SDS components can run. You still need a strong control plane, data services, and observability.
SPDK does not require a DPU. SPDK is a user-space toolkit for building high-performance storage software. DPUs simply provide another place to run infrastructure code.
DPUs are not limited to RDMA. They can help with NVMe/TCP too, because TCP still costs CPU. They can also help with security and isolation in both cases.
Yes. DPUs can isolate the storage and networking data path from noisy pods on the host. This often reduces p99 latency spikes and improves consistency for shared clusters.
Not always. Many teams start by using DPUs for transport, security, and policy offload while keeping the storage services on the host. Deeper integration can come later if the operational model fits.
DPUs tend to help most when host CPU is a bottleneck, when tail latency is unstable, or when you run high IOPS NVMe/TCP or NVMe-oF at scale. They are also useful when you need stronger isolation in multi-tenant Kubernetes environments.