
Every CTO knows this story. The release passes every automated test, the staging sign-off is green, and confidence is high. Yet hours after deployment, dashboards flare red. Performance tanks, customer-facing features break, or worse, critical data goes missing. The culprit, more often than not, is a database change such as migration, schema modification, or index update that behaved perfectly in pre-production but exposed hidden problems in production.
This isn’t a rare edge case. It’s a systemic issue in modern software delivery. Even organizations with mature CI/CD pipelines often admit that databases are the last major blind spot in their release process. In 2024, Agoda Engineering shared a detailed account of how this problem manifested at a massive scale in their own operations. They struggled with shared QA databases, massive datasets too big to refresh quickly, and the high cost of rolling back changes once issues were discovered.
Their solution was to build an internal Ceph-backed database snapshot system, effectively a homegrown database branching platform, so that developers and QA engineers could spin up isolated, production-like database copies on demand. The impact was immediate: fewer environment conflicts, faster testing, and safer releases. But building and maintaining such a system required a major ongoing investment in infrastructure and engineering resources.
Vela exists because most companies don’t have the luxury of building a system like Agoda’s from scratch. The business problem is universal, but the homegrown solution is out of reach for all but the largest, most resource-rich organizations. Further to that, Ceph might not be the best storage solution to use, as it’s generally complex to manage and has high latency.
The Last Great Unknown in CI/CD: Your Data
For application code, testing is easy. Developers spin up a clean environment, run their unit tests, and merge with confidence. With CI/CD, this happens automatically in seconds. But databases don’t play by the same rules.
Most teams still work with a shared testing database on dedicated staging environments. Developers create branches of their code, but when it comes to the database, they’re often forced to use the same tables. This leads to messy collisions: one person’s schema change can break another’s test, or the data doesn’t look like what the test expects. Rolling back is painful and time-consuming.
Another problem is scale. For smaller datasets, it’s possible to spin up a new database or use a Docker container. But once your production database grows into the hundreds of gigabytes or terabytes, it becomes nearly impossible to copy and reload that data for every test. Staging refreshes take too long, so they happen rarely. The result? Most tests run on outdated or incomplete data, and real issues only show up late in the cycle—or worse, in production.
Agoda described this exact pain. Their developers and QA engineers were stuck sharing databases, tests failed unpredictably, and rolling back schema changes was slow. By introducing database branching with Ceph snapshots, they finally gave every engineer their own isolated, production-like environment in minutes. It eliminated environment conflicts and gave them confidence that tests were meaningful, not just synthetic exercises.
Why Database Bugs Hide Until It’s Too Late

Even high-performing engineering organizations struggle to catch database bugs early. One reason is that many teams still test against outdated datasets. If refreshing your staging environment takes hours or even days, data will inevitably be stale by the time testing begins. Migrations that pass in QA can still fail in production simply because they weren’t tested against the most current data shape and volume.
Another factor is the reliance on synthetic or “production-like” datasets. While these can be useful for certain tests, they can’t replicate the full complexity of a live production database. Subtle issues in referential integrity, indexing strategies, or query optimizer behavior often go undetected until they cause real harm. And when compliance or security policies limit access to live data, fewer engineers can perform realistic tests, further reducing the likelihood of catching issues early.
This isn’t just Agoda’s problem. In our recent survey of over 200 engineers on Reddit we confirmed that this is reality for many organizations. The majority (57%) reported that they still rely on dedicated staging environments to test database changes. Others use manual dump/restore of production data or even test directly on production systems. Only a handful (just five respondents) said they were using database branching or cloning tools today. In other words, most teams are stuck with staging environments that are slow to refresh, fragile to maintain, and rarely representative of their production environment. It’s no surprise, then, that many issues only surface late in the release cycle or once code is already live.

Agoda’s workaround with database cloning addressed these pain points head-on. By snapshotting production databases, anonymizing sensitive fields, and allowing developers to branch their own isolated copy, they created a workflow where schema changes could be validated on truly representative data before merging to main. This was transformative for quality, but it came at the cost of building and operating a bespoke storage and orchestration layer.
The Business Cost of Late Discovery
When database issues are discovered only after deployment, the cost multiplies rapidly. There is an immediate operational impact, like downtime, degraded performance, and emergency rollbacks. These issues consume valuable engineering time. There is also a strategic cost: teams lose confidence in their CI/CD pipelines and become more cautious, slowing down releases in an attempt to reduce risk. Over time, this erodes the very agility that modern software delivery practices are meant to enable. The same principle applies in areas like B2B lead generation, where relying on incomplete or outdated data often leads to wasted effort and missed opportunities.
Agoda’s post-mortem analysis revealed a clear truth: without fast, safe database branching for every meaningful change, they were constantly gambling with their release quality. Even though their eventual solution was successful, it required a sustained and specialized effort to maintain. Most companies simply cannot justify that level of investment, leaving them exposed to the same risks.
This is where Vela’s proposition becomes most powerful. Instead of diverting resources into building a custom snapshotting platform, organizations can adopt a fully managed solution that offers the same capabilities: instant database cloning, compliance-ready anonymization, and seamless CI/CD integration. All, right out of the box.
The Vela Approach: Instant Database Branching Without the Heavy Lifting
Vela was designed to deliver the kind of database branching capability that Agoda built in-house, but without the infrastructure burden. At its core is a high-performance simplyblock storage layer that allows for copy-on-write database clones to be created in seconds, not hours. This means that developers, QA engineers, and CI/CD pipelines can all work with isolated, production-scale environments without interfering with one another.
The process is straightforward: branch from your production database, automatically anonymize sensitive data for compliance, and hand off the clone to your test pipeline or development workflow. Because Vela operates at the storage layer, these clones are incredibly space-efficient and fast to create, making it practical to generate dozens or even hundreds in parallel. The result is that realistic database testing can happen earlier, more often, and with greater coverage—reducing the chances of issues slipping into production.
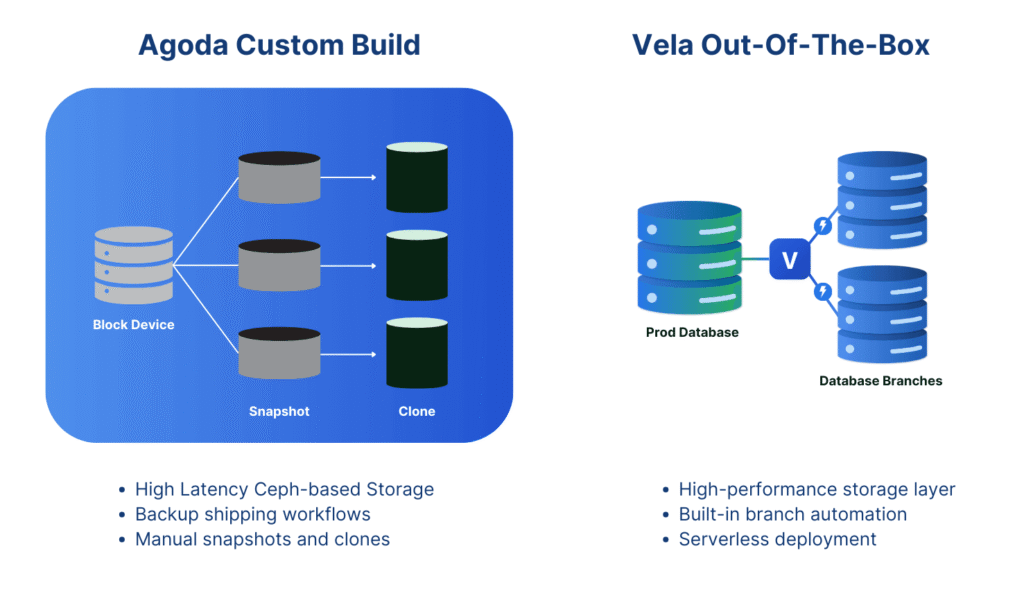
Where Agoda had to maintain a Ceph cluster, custom backup shipping, and Kubernetes integration, Vela provides all of this in a portable, serverless package. Vela uses clones and not snapshots. There’s no need for deep storage expertise, no heavy ops overhead, and no long lead time before you start seeing the benefits. It’s database cloning as a service, optimized for enterprises that need both speed and governance.
From Risk Management to Release Confidence
The future of database operations is not about avoiding mistakes entirely. It’s about catching them so early that they never affect your customers. Database branching is the enabler for that future. It makes realistic, production-scale database testing as routine as running unit tests, giving teams the confidence to ship faster without increasing risk.
Agoda’s journey proved that the approach works. Vela makes it accessible to every organization, without requiring them to become storage platform engineers. For CTOs, the value proposition is clear: fewer production incidents, faster release cycles, higher developer productivity, and lower operational costs.
If your team is still testing database changes on stale or synthetic datasets, you’re running blind. With Vela, you can bring production reality into every branch, every pull request, and every test, and stop gambling with your releases. Database branching will soon be as common as feature branching. Teams that adopt it early will release faster, with fewer mistakes. Vela makes that shift possible today.


