
TL;DR: Mock databases are great for quick unit tests, but they fail to catch the real-world issues from production environments. For reliable database testing, you need database clones that mirror your production schema, data patterns, and performance semantics. With production-grade database clones for QA and staging, you ensure that bugs are caught early, performance is realistic, and QA confidence stays high.
We’ve been there. All of us. Including me. The build is tested and signed off. QA is confident in the release. It goes live… and two hours later, the production logs look like a horror movie script.
Not because QA did a bad job. Not because our developers were careless. Not because the release was deployed incorrectly. Nine out of ten times, the real problem was the environment in which we tested. While typical QA and staging environments are modelled after production (sometimes slightly scaled down), their databases are mostly not. Meaning, they contain data far from the reality of production, in terms of data size and often also semantics. Oftentimes, created from a fixed set of mock data.
When to Use Mock Databases?
Don’t get me wrong, mocks are great if used correctly. A mocked database is essentially a fake database engine or in-memory data structure designed to mimic the interface of a real database. For certain types of tests, this approach makes perfect sense.
For example, if you’re testing a function that formats a query result into JSON, you don’t need a full-blown production-grade Postgres instance running. You just need a predictable response object. Mocks are lightning-fast, have zero setup cost, and are isolated by default. They allow developers to run tests on laptops, in CI pipelines, and in environments where provisioning a real database would be overkill.
In many teams, mocks are the foundation of unit testing. They help ensure that business logic works in isolation, free from the unpredictability of real data. They also save money. Maintaining multiple large-scale database instances for every developer or QA run can be expensive. Therefore, using mocks for basic tests helps keep the infrastructure lean and efficient.
The Illusion of Safety: Where Mocks Fail
Mocks aren’t a silver bullet, though, and fail in more situations than you might imagine at first glance.
Schema Drift
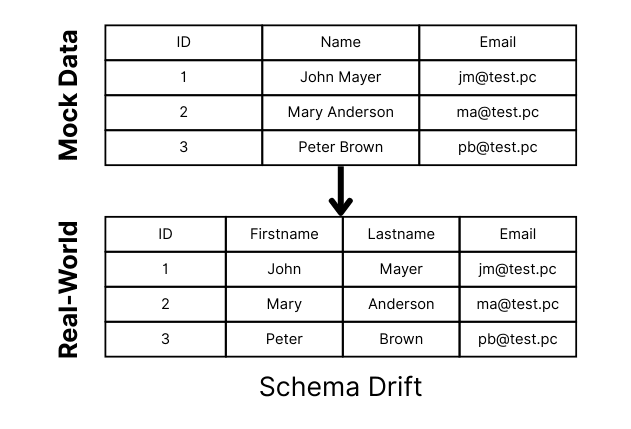
In most teams, the mock database’s schema is defined separately from the actual production database schema. Over time, the two inevitably diverge. A column gets renamed in production, but the mock still uses the old name. A new constraint is added, but the mock doesn’t enforce it. This means that tests can pass happily on the mock while failing immediately in production. Schema drift is probably the most obvious one. A problem we’ve all seen before.
Data Shape Mismatch
Then there is the so-called data shape mismatch. Real production data is messy. It contains nulls in fields you assumed would always have values. It has foreign key relationships that break because of incomplete deletes. It has strings with unexpected encodings, dates in odd formats, and records that violate assumptions you didn’t even realize you had. Mock data is usually neat, tidy, and fits the “happy world” path. It’s rarely designed to reflect the edge cases that production data throws at your code, unless you fell flat before and added data for this specific edge case.
Performance Blindness
Another issue is performance testing. Any change to ORM object models, SQL queries, indexes, and whatnot can cause behavior changes in the query planner and your execution plan. Mocks don’t simulate query execution plans, index usage, or I/O latency. Your code might pass every functional test against a mock, but grind to a halt when a query hits a table with millions of rows and no proper index. That’s the kind of problem that only emerges when running against a real, populated database.
Integration Gaps
Since mocks aren’t real databases, they don’t run database-level features like triggers, implicit casts, stored procedures, or data sharding. These features are often deeply intertwined with application logic and implement crucial business rules. Not testing the interaction between those elements and your application code opens a whole class of potential issues, only to be seen in production.
Security and Access Control
Finally, mocks rarely simulate security and access control rules. If your production database uses role-based access, column or row-level security, or data partitioning, you can’t fully validate that behavior against a mock. This is a breeding ground for permission-related bugs, which can range from frustrating to catastrophic.
QA Confidence Problem
Missing insight due to these testing gaps leads to a false sense of confidence. Your QA teams see green builds and believe the code is ready for production, and they should. That’s what tests are for. The problem is that the “tests” didn’t reflect real-world conditions.
One of the most famous sayings in software engineering is “it works on my machine.” The QA version must be that “but it worked on staging.” It reflects the fact that staging isn’t anything like production. In practice, this means bugs are caught too late in the software lifecycle or, worse, they slip into production.
The Trust Gap
The impact isn’t just technical. It’s psychological. When your QA teams know that their environment doesn’t mirror production, they lose trust in their own processes. If we can’t catch these bugs before release, what’s the point altogether?
This trust gap is dangerous because it leads to one of two equally bad outcomes:
- Teams skip tests altogether because they believe they’re ineffective.
- Teams pile on even more mock-based tests, doubling down on a flawed foundation.
However, neither of these paths leads to higher quality, faster, or safer releases.
Production-Grade Databases Are Different
If you want QA confidence back, you need to test with the same kind of database you run in production.
That means more than just making sure that database schemas match, or running against an actual database (like a real PostgreSQL). It also means that the data inside this database needs to match a production database to a high degree. Something often called “production-grade.”
You don’t have to copy raw production data (and you shouldn’t for privacy reasons). Still, you can use anonymized snapshots that keep the identical distributions, null patterns, and edge cases that make production data unpredictable.
Using such a production-grade database is great for tests, especially in staging environments when software gets closer to production. But it also means that you’ll be able to see real performance characteristics. A query that will take 200ms on the production database should provide similar results on a production-grade database clone, ensuring that you can test query optimizations and hot paths in your application with confidence.
Last but not least, it means having full feature parity. Triggers, stored procs, constraints, and role-based security. All of them are now part of your testing environment, so bugs can’t hide behind missing features.
When your QA database is truly production-grade, “green means green.”
QA Databases for Shifting Left
Here’s where things get exciting: I’m a developer at heart. I don’t want to wait until QA or staging to benefit from a production-grade database. In my time actively developing large application systems, I would’ve loved the opportunity to use these systems early. Not only for performance and simple change testing, but especially for finding out how to reproduce production issues. The type of issue only happening in production and only to certain customers.
Now imagine, with the right tooling, developers could spin up their own isolated database branches, an exact copy of the production’s schema and structure, but loaded with safe-but-realistic data. And it would only take seconds. Integrated into typical developer tools such as Testcontainers.

This changes everything. You can:
- Find bugs earlier: If a developer’s branch fails against real constraints or data patterns, they fix it before QA even sees it.
- Reproduce production issues instantly: Instead of guessing what the data looked like, you can branch from the exact point in time (with sensitive fields masked) and debug locally.
- Run tests in parallel: Every developer, every QA engineer, every CI pipeline run can have its own fresh, isolated, production-grade DB. No stepping on each other’s toes.
The earlier you catch a bug, the cheaper it is to fix. Bringing production-grade databases closer to the developer’s keyboard is one of the highest efficiency moves you can make.
Vela: Push Your Deployment Confidence
This is exactly why we build Vela.
Vela lets you branch a production-grade PostgreSQL database clones instantly. You get the exact schema, extensions, indexes, and constraints from production. But not just the schema, but also actual or anonymized data.
For QA, this means your staging environment matches production, eliminating the risk of surprises lurking after release. As a developer, it means you can test against the real thing before you even open a pull request.
Because branches are isolated, safe, and disposable, you can spin them up for CI/CD runs, parallel QA testing, or local debugging without worrying about breaking someone else’s environment. And because they’re created in seconds, they fit naturally into any workflow.
The result? You keep mocks for what they’re good at, but use production-grade databases for the tests that matter. Developers find bugs before staging, QA confidence comes back, and production incidents drop.
Test Reality, Not Illusions
Mocks aren’t evil. They’re just overused. They’re fantastic for testing business logic in isolation, but they will never simulate the messy, unpredictable, performance-sensitive reality of a real database.
If your QA process leans too heavily on mocks, you’re testing an illusion. And illusions make for fragile confidence.
By introducing production-grade database clones with Vela, you can bridge the gap and make your tests reflect reality. And when QA says “we’re good to ship,” you can believe them.
After all, testing should be about finding out the truth, not confirming a convenient fiction.


