Data Replication
Terms related to simplyblock
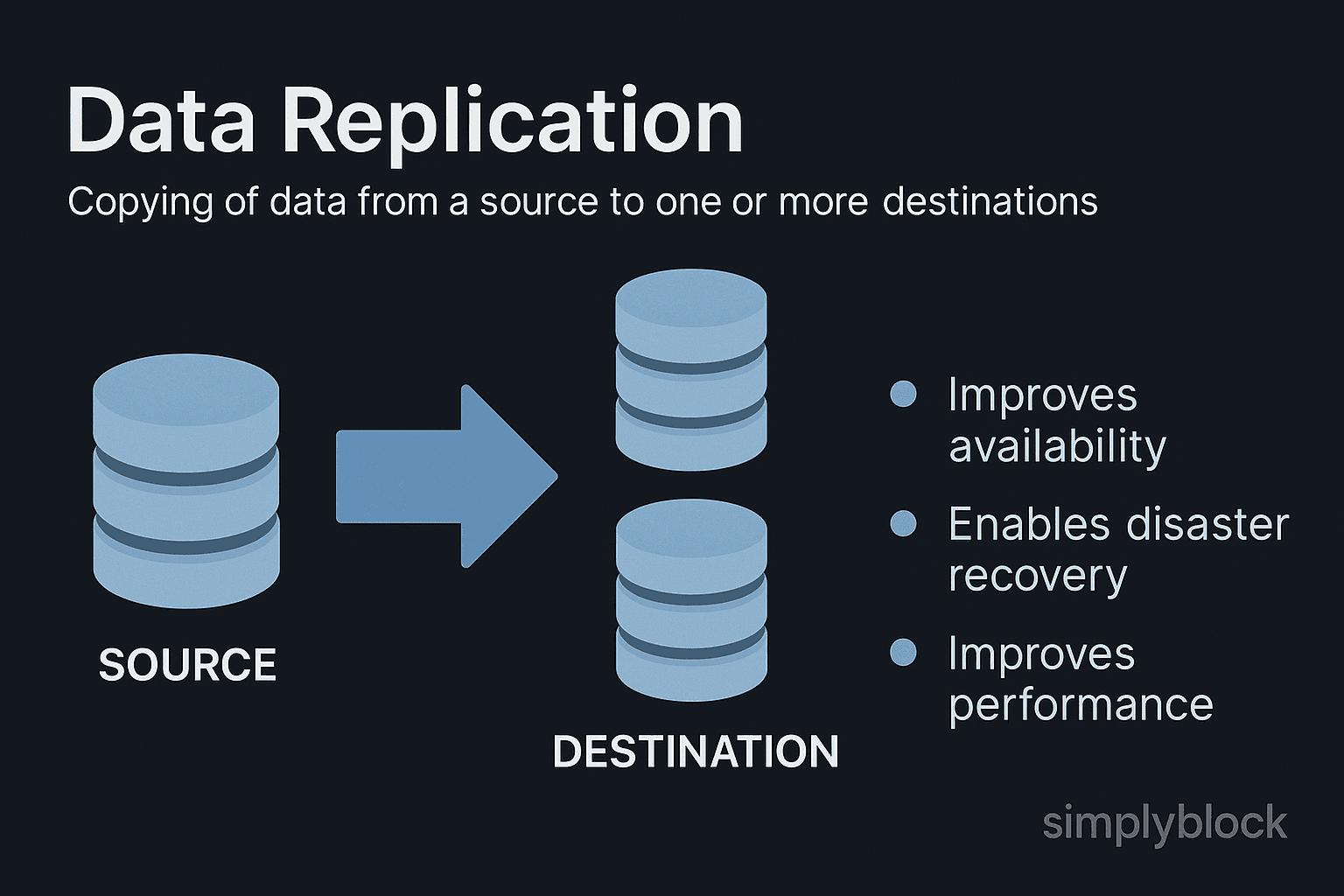
Data replication is the process of duplicating data from one storage location to another to ensure consistency, availability, fault tolerance, and disaster recovery. Replication allows systems to maintain up-to-date copies of data across multiple servers, data centers, or cloud regions, enabling high availability and resilience against failure or corruption.
In modern architectures, replication is implemented across block, file, and object storage systems, and is often used in conjunction with erasure coding, snapshots, or geo-distributed deployments. simplyblock enables real-time block-level replication across hybrid and cloud-native environments, optimized for performance and data durability.
How Data Replication Works
Replication can be synchronous or asynchronous:
- Synchronous replication writes data to multiple locations simultaneously. It guarantees consistency but introduces latency due to the write acknowledgment across nodes.
- Asynchronous replication writes data to a primary node first, then propagates updates to secondary locations with a delay. It reduces latency but may risk temporary inconsistency.
Replication strategies may include:
- One-to-one (primary to replica)
- One-to-many (hub-and-spoke)
- Bidirectional (active-active clusters)
- Geo-redundant (across regions or clouds)
Benefits of Data Replication
Enterprises use replication to improve performance, uptime, and compliance:
- High availability: Ensures continued access during node, rack, or site failure.
- Disaster recovery: Maintains backup copies in case of hardware failure or ransomware.
- Data locality: Serves global users by replicating data to local regions.
- Performance optimization: Reduces read latency by load-balancing access across replicas.
- Compliance and retention: Supports retention policies by storing multiple consistent copies.
With erasure coding and snapshotting, replication enhances fault tolerance without sacrificing space efficiency.
Use Cases for Data Replication
Data replication is used across a wide range of mission-critical scenarios:
- Stateful Kubernetes applications: Replicated persistent volumes for failover or cross-zone storage availability
- Databases: Replication in PostgreSQL, Cassandra, or MongoDB to ensure read/write availability
- Edge to cloud: Syncing data from IoT devices or edge locations to a central cloud system
- Disaster recovery planning: Protecting against infrastructure or region-wide outages
- Multi-cloud storage: Avoiding vendor lock-in while maintaining consistent datasets
Data Replication vs Backup vs Erasure Coding
Each technique addresses durability and availability differently. Here’s how they compare:
| Feature | Data Replication | Backup | Erasure Coding |
|---|---|---|---|
| Purpose | High availability, resilience | Recovery after failure or loss | Space-efficient fault tolerance |
| Timing | Real-time or near real-time | Scheduled | Real-time |
| Storage Overhead | High (full copies) | High (full copies) | Low to moderate |
| Recovery Speed | Instant failover | Slower (restore needed) | Near-instant |
| Ideal Use Case | Clustering, failover systems | Archival, compliance | Large-scale distributed storage |
Data Replication in Simplyblock™
Simplyblock implements block-level data replication to ensure consistency across hybrid and cloud-native deployments. Features include:
- Replication across availability zones or edge nodes
- Real-time propagation of changes for low RPO
- Integration with CSI volumes in Kubernetes for stateful apps
- Support for hybrid cloud storage with unified volume orchestration
- Resilience layering with erasure coding for durable and efficient replication
This ensures that applications experience no downtime, even during infrastructure failures.
Related Terms
Teams often review these glossary pages alongside Data Replication when they define recovery objectives, pick replication modes, and standardize failover workflows for Kubernetes Storage and Software-defined Block Storage.
Asynchronous Storage Replication
Cross-Zone Replication
Cross-Cluster Replication
Hybrid Erasure Coding
External Resources
- Data Replication – IBM
- Disaster Recovery and Replication – AWS
- Synchronous vs Asynchronous Replication – Red Hat
- Understanding Kubernetes StatefulSets
- Replication Strategies for Databases – DigitalOcean
Questions and Answers
Data replication ensures high availability and fault tolerance by copying data across multiple nodes or locations. It protects against hardware failures and enables disaster recovery, making it essential for databases, Kubernetes clusters, and mission-critical apps.
In Kubernetes, replication is often managed at the storage level through CSI-compatible platforms. Using Kubernetes-native storage like Simplyblock, you can replicate volumes across nodes or zones with minimal latency and automatic failover.
Common types include synchronous replication, which mirrors data in real time, and asynchronous replication, which introduces slight delays but reduces latency impact. Each serves different RPO/RTO needs and can be used with software-defined storage platforms.
Replication can affect performance depending on the method and infrastructure. Synchronous replication adds latency but offers zero data loss. With NVMe over TCP, modern systems reduce that overhead while maintaining high performance.
Yes. Replication works alongside encryption at rest, ensuring that all data copies are protected. Volume-level encryption ensures security and compliance, even across geographically distributed replicas.