Pod Affinity and Storage
Terms related to simplyblock
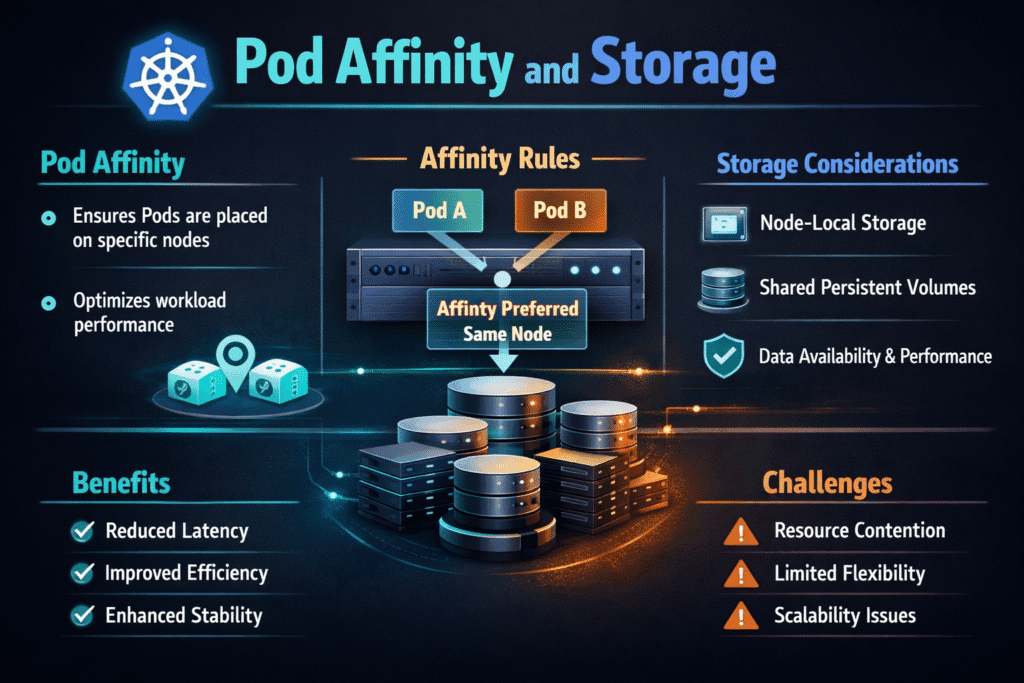
Pod affinity controls where Kubernetes places a pod based on labels on other pods. Storage controls where data lives, how volumes attach, and which failure domains protect it. When these two decisions align, stateful services keep I/O stable during scale-outs, node drains, and failovers. When they drift apart, pods sit pending, volumes bind in the wrong zone, and p99 latency becomes hard to explain.
Teams often treat “placement” as a scheduler topic and “performance” as a storage topic. In real clusters, they merge into one operational risk. A strong approach lines up workload intent, topology rules, and the storage platform’s volume placement so the control plane does not fight itself.
Placement mechanics that keep data close to the compute
Affinity, anti-affinity, and topology spread constraints steer pods toward the right nodes and away from risky co-location. StorageClass settings steer volume provisioning toward the right performance tier and the right failure domain. The cluster runs best when labeling stays consistent across node pools, zones, and storage pools.
Hard affinity can raise risk during disruption. If a node fails, the scheduler loses options, and a StatefulSet may wait for a “perfect” node while the business waits for recovery. In many environments, spread constraints plus softer preferences deliver resilience without blocking progress.
🚀 Run Stateful Pods with Affinity on NVMe/TCP Storage, Natively in Kubernetes
Use Simplyblock to keep pod placement and volume locality aligned and prevent tail-latency spikes.
👉 Use Simplyblock for Kubernetes Storage →
Pod Affinity and Storage in Kubernetes Storage Workflows
Kubernetes Storage adds constraints that the scheduler must respect. Persistent volumes may only attach in a zone, on a node type, or through a specific CSI path. Access modes also matter. A single-writer volume forces replicas to land on different claims, while multi-attach patterns change how you handle failover and maintenance.
This is where Software-defined Block Storage helps. Instead of tying persistence to one fixed appliance or one rigid topology, you can align provisioning with scheduling intent across hyper-converged, disaggregated, or hybrid deployments. That alignment lowers the chance of “scheduled but not attachable” events, and it reduces cross-zone I/O that inflates tail latency.
Topology alignment strategies for multi-zone clusters
Topology-aware provisioning works best when labels, zones, and StorageClass intent match. If your platform team uses consistent zone labels on nodes and consistent topology keys in storage, the control plane can place replicas where they belong and still keep volume locality intact.
Cross-zone replication also needs a clear intent. Replication protects availability, but it can introduce steady cross-zone traffic if the storage layer replicates synchronously across domains while the scheduler keeps pods local. A clear policy defines which workloads accept synchronous durability costs and which workloads prefer asynchronous replication with faster steady-state latency.
Pod Affinity and Storage over NVMe/TCP networks
Disaggregated designs push compute and storage into separate pools. That makes scheduling more flexible, but it also makes the storage network part of the latency budget. NVMe/TCP helps because it keeps NVMe semantics over standard Ethernet, which fits most enterprise networks and avoids specialized fabrics for many deployments.
An SPDK-based datapath also matters here. User-space I/O and zero-copy techniques reduce CPU overhead, which protects application cores when you pin high-throughput pods to specific nodes. In practice, NVMe/TCP plus an efficient datapath lets platform teams keep Kubernetes Storage flexible without giving up predictable block performance.
Pod Affinity and Storage performance metrics that matter
Measure placement outcomes before you chase raw IOPS. Start with locality. Confirm that pods land in the intended zone and node class, and confirm that their volumes bind and attach in the same locality model. Then measure storage behavior under real cluster events such as node drains, rolling updates, and pod reschedules.
For performance, focus on what impacts users and SLOs. Track p50, p95, and p99 latency, plus throughput and queue depth. Also track attach time, mount time, and volume binding time. These signals show whether the storage layer and scheduler cooperate under pressure.
One practical tuning checklist for higher consistency
- Use topology spread constraints to distribute replicas, and pair them with StorageClass settings that keep volumes in the same failure domain as the selected nodes.
- Prefer anti-affinity or “preferred” affinity rules for most stateful apps so the scheduler can react fast during failure.
- Reserve node pools for latency-sensitive workloads, and apply node affinity so pods land on predictable CPU, NIC, and storage profiles.
- Apply per-tenant or per-workload QoS so one noisy job cannot consume shared bandwidth in Kubernetes Storage.
- Validate the NVMe/TCP network path with headroom targets for peak hours, not lab averages, then re-test during rollouts.
Placement patterns compared
The table below summarizes how common scheduling and storage patterns behave when you optimize for steady latency and operational safety.
| Pattern | What it optimizes | Trade-off | Best fit |
|---|---|---|---|
| Hard pod affinity with local disks | Lowest hop count in steady state | Low flexibility during failures | Small baremetal footprints with fixed layouts |
| Spread constraints with topology-aligned provisioning | Resilience plus locality | Requires disciplined labels and policies | Multi-zone databases and queues |
| Disaggregated storage over NVMe/TCP | Independent compute and storage scaling | Needs network headroom and QoS | Larger clusters replacing a SAN alternative |
| Hyper-converged storage with dedicated node pools | Simple operations and upgrade paths | Noisy-neighbor risk without QoS | Cost-focused environments with mixed tenants |
Predictable placement with Simplyblock™
Simplyblock supports Kubernetes Storage with NVMe/TCP and Software-defined Block Storage so teams can align pod placement with volume locality across hyper-converged, disaggregated, or hybrid layouts. That alignment reduces pending pods caused by volume constraints and lowers cross-domain traffic that drives tail latency.
Because simplyblock uses an SPDK-based architecture, it targets efficient I/O processing and strong CPU utilization. That matters when you pin performance-critical pods with affinity rules and still need compute headroom for application threads. Multi-tenancy and QoS controls also help keep performance consistent when several teams share the same storage plane.
What to expect next in scheduling-aware persistence
Kubernetes keeps improving topology controls, and storage platforms keep adding policy-driven placement and QoS. Expect more automated coordination between the scheduler and provisioners, tighter locality controls in multi-zone clusters, and broader NVMe/TCP adoption in disaggregated designs. As those pieces mature, teams will rely less on rigid hard-affinity rules and more on resilient placement policies that still protect storage locality.
Related Terms
Teams often review these glossary pages alongside Pod Affinity and Storage when they set enforceable policies for Kubernetes Storage and Software-defined Block Storage.
Questions and Answers
Pod affinity influences workload placement by scheduling pods close to specific nodes or other pods. When aligned with storage topology, it enhances data locality and reduces network latency between compute and persistent volumes—critical for IOPS-heavy applications.
Yes. If a pod is scheduled to a node without access to its bound volume (due to zone or topology constraints), scheduling will fail. Using topology-aware CSI provisioning ensures volumes are created in zones that match pod placement preferences.
Absolutely. AccessModes like ReadWriteOnce require the pod and volume to reside on the same node or zone. Combining affinity with preferredDuringScheduling can guide placement without causing hard scheduling failures—especially in stateful workloads relying on local access.
StatefulSets often rely on stable identity and storage, making predictable pod placement crucial. Using podAffinity or podAntiAffinity In conjunction with StorageClass, topology allows optimized performance, HA planning, and reduced IO contention.
Yes. Simplyblock supports CSI features TopologyAwareProvisioning and integrates with Kubernetes’ scheduler to align volume provisioning with pod affinity. This ensures high-performance storage is placed close to workloads—boosting throughput and minimizing cross-zone traffic.