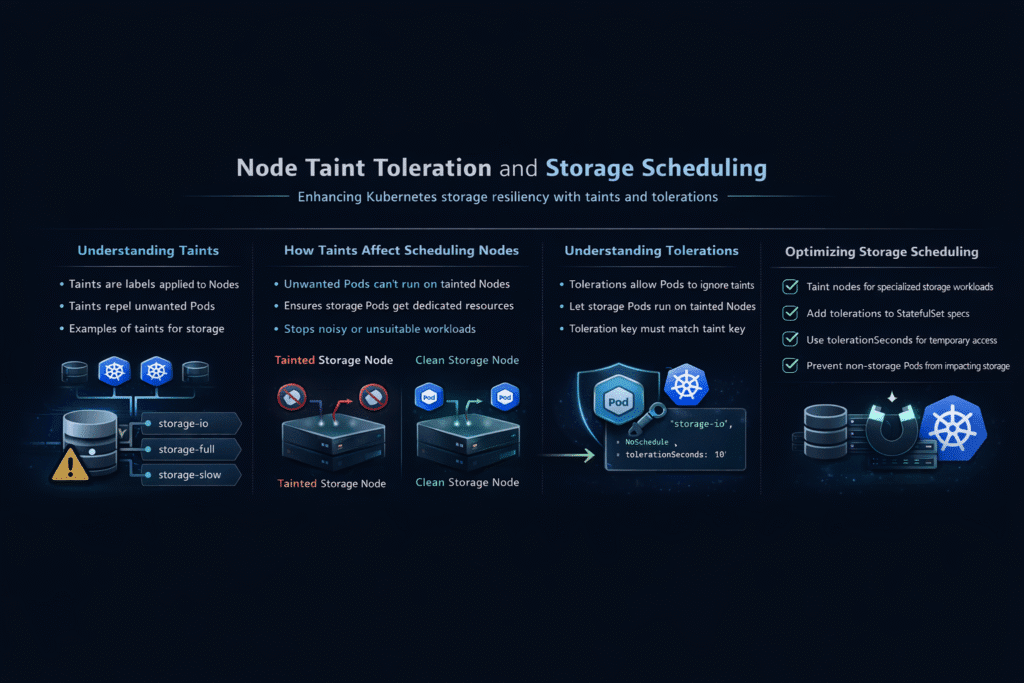
Node Taint Toleration and Storage Scheduling
Terms related to simplyblock
Node taints and tolerations control where Kubernetes places pods, while storage scheduling decides where persistent volumes get created and attached. When these two behaviors align, stateful apps start faster, avoid repeated reschedules, and keep a stable I/O path. When they drift apart, teams see pods stuck in Pending, cross-zone volume mistakes, or noisy-neighbor slowdowns that show up as p99 latency spikes.
Executives usually feel the impact as missed SLOs for databases, longer recovery during node failures, and higher cloud or bare-metal spend caused by overprovisioning. Platform teams feel it as YAML sprawl, “special case” tolerations, and late-night paging tied to storage contention.
Policy Design for Stable Stateful Placement
A clean policy starts with intent. Reserve specific node pools for storage services and for latency-sensitive workloads, then encode that intent with taints and labels. Keep tolerations narrow, so only the right pods can enter those pools. Pair that with affinity rules so the scheduler picks the correct hardware class, NIC profile, and failure domain.
This approach reduces accidental co-location, because the platform stops “hoping” the scheduler will do the right thing. It also makes audits easier, because teams can trace placement decisions back to explicit policy rather than tribal knowledge.
🚀 Stop Pending Loops Caused by Storage Misplacement in Kubernetes
Use simplyblock to run NVMe/TCP volumes with Kubernetes-native orchestration, so taints and tolerations map cleanly to storage-ready nodes.
👉 Use simplyblock for Kubernetes Storage with NVMe/TCP →
Storage-Aware Scheduling Inside Kubernetes
Kubernetes Storage introduces extra moving parts: dynamic provisioning, attach and mount timing, and topology constraints. A pod can schedule successfully and still fail later if the cluster cannot create or attach the volume where the pod landed. That mismatch wastes time and creates retry storms in the control plane.
Good platform design treats storage signals as first-class inputs. Capacity awareness helps the scheduler avoid dead ends. Topology awareness keeps volumes close to the workload, which cuts network hops and reduces tail latency. Clear StorageClass rules prevent teams from requesting the wrong tier, then blaming the scheduler when performance drops.
Node Taint Toleration and Storage Scheduling with NVMe/TCP
When you run NVMe/TCP, the data path depends on both compute placement and network placement. A workload that lands on the “wrong” node may still run, but it can take a longer network path, share a congested link, or lose the intended MTU and tuning. Those small differences show up as jitter during peak hours.
A strong pattern ties NVMe/TCP fast lanes to specific node pools. The platform taints those pools, grants tolerations only to approved workloads, and enforces QoS so one tenant cannot starve another. That combination creates repeatable performance without turning every deployment into a one-off scheduling puzzle.
How to Measure Scheduling Impact on Storage Outcomes
Raw IOPS numbers do not explain scheduling quality. Track time-to-ready for stateful pods, because the user experience depends on how fast the platform can place, provision, attach, and mount. Monitor reschedule counts and “Pending” duration to spot policy drift early. Watch p95 and p99 latency for the storage path, because tail latency exposes contention and misplacement faster than averages.
Use a two-step test method. Run a focused block test to validate the storage tier under load. Then run a workload test that mirrors real concurrency, recovery behavior, and background tasks such as compaction or checkpoints. That pairing prevents false wins from synthetic tests that ignore scheduler pressure.
Practical Changes That Improve Placement and Throughput
Below is a single, policy-first checklist that teams can apply without rewriting every workload.
- Define dedicated node pools for storage services and high-IO workloads, and keep the pool names consistent across clusters.
- Apply taints to those pools, then grant tolerations only to the pods that truly need them.
- Add node labels and affinity rules that match CPU class, NIC profile, and topology boundaries.
- Standardize StorageClasses so each tier maps to clear performance and protection behavior.
- Enable storage QoS so one noisy tenant cannot dominate queues and inflate tail latency.
- Validate changes with a repeatable benchmark suite that includes failover and scale events.
Scheduling Strategy Trade-Offs at a Glance
The table below summarizes common scheduling approaches and how they behave when clusters face contention, topology constraints, and multi-tenant load.
| Approach | What it does well | Where it breaks | Best fit |
|---|---|---|---|
| Default scheduling | Minimal setup effort | Pods land on nodes with poor storage locality, which raises latency variance | Small clusters, low-risk apps |
| Taints and tolerations only | Strong role separation | Performance still varies when tenants compete for the same queues | Dedicated lanes without strict SLOs |
| Taints + topology + QoS | Predictable placement and stable tail latency | Requires platform discipline and standards | Production stateful platforms |
Platform-Level Guardrails for Storage Scheduling with Simplyblock
Simplyblock supports Kubernetes Storage with a design that aligns policy, placement, and performance. Teams can run hyper-converged, disaggregated, or mixed layouts without changing how apps request storage. Platform owners can enforce QoS and multi-tenant controls so scheduling decisions translate into predictable I/O behavior.
The data path benefits from SPDK-style user-space principles, which reduce CPU overhead and improve consistency under load. That matters when clusters push NVMe/TCP at scale and still need headroom for compute. When you combine clean taint and toleration policy with a fast storage path, teams reduce reschedules, tighten p99 latency, and simplify operations.
Future Directions in Node Taint Toleration and Storage Scheduling
Storage scheduling will move toward tighter feedback between the scheduler and the storage layer. Clusters will rely more on real capacity signals, faster placement decisions, and clearer failure-domain behavior. Multi-tenant platforms will also raise the bar for isolation, because mixed workloads keep growing in the same clusters.
Acceleration will play a bigger role as well. DPUs and similar devices can offload parts of the I/O path, reduce CPU contention, and keep NVMe/TCP performance more stable during spikes. Teams that plan for these shifts now can avoid later rework in policy, labels, and node pool design.
Related Terms
Teams often review these glossary pages alongside Node Taint Toleration and Storage Scheduling when they set measurable targets for Kubernetes Storage and Software-defined Block Storage.
- CSI Topology Awareness
- Storage Quality of Service (QoS)
- Kubernetes Volume Expansion
- Asynchronous Replication
Questions and Answers
Taints repel pods from nodes unless those pods tolerate the taint. For workloads with attached persistent volumes, tolerations must be correctly set to ensure scheduling works with stateful Kubernetes deployments where pod-node affinity and volume availability are critical.
Yes, but only if the pod includes matching tolerations. This is common in storage-dedicated nodes. With CSI, proper configuration ensures that persistent volumes are still provisioned and mounted. Simplyblock supports topology-aware volume scheduling even in tainted node pools.
While taints/tolerations are pod-level, they indirectly affect storage scheduling by controlling pod placement. To avoid provisioning errors, ensure CSI volume provisioning aligns with node availability, tolerations, and any zone or failure domain constraints.
Use taints to isolate IOPS-heavy workloads on storage-optimized nodes. Then apply tolerations only to pods that require that storage class or node type. This aligns with Simplyblock’s approach to dedicated storage node performance tuning.
Absolutely. If pods can’t be scheduled to a node where the PVC is accessible, volume attachment will fail. It’s essential to coordinate tolerations with persistent volume topology and storage class zone settings.