AI Pipeline
Terms related to simplyblock
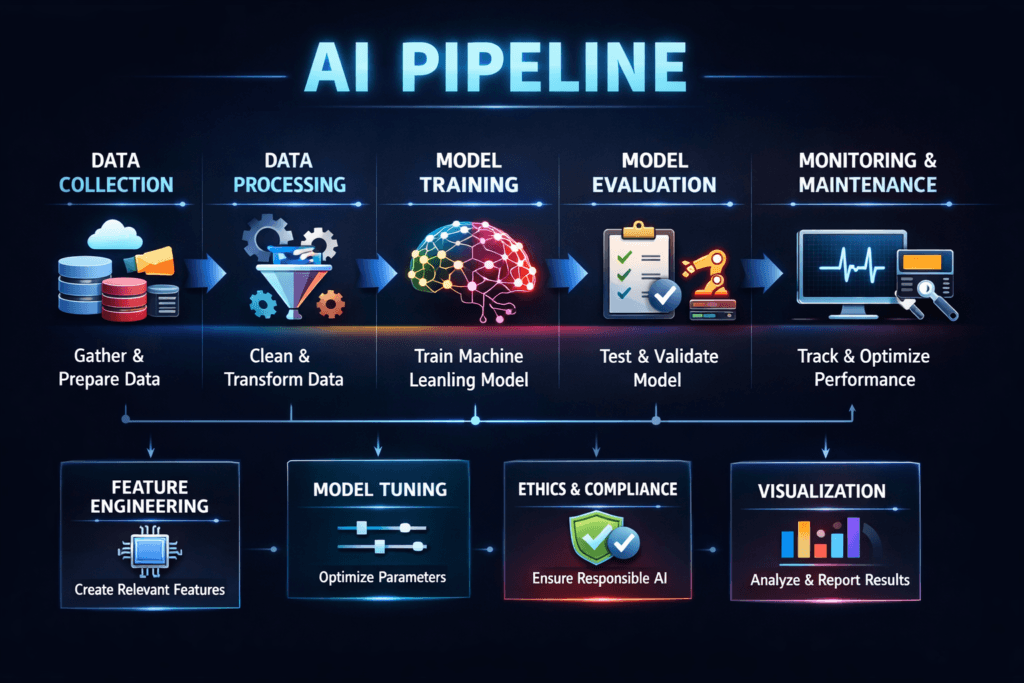
An AI pipeline is the end-to-end flow that turns raw data into a trained model and then ships that model into production. It usually includes data ingest, data prep, feature creation, training, evaluation, model registry, and rollout for batch or real-time inference. Many teams now run these steps on Kubernetes to scale GPU jobs, standardize deployments, and keep security controls consistent.
Storage sits in the critical path more often than teams expect. Training pulls large datasets, writes checkpoints, and reads them back during restarts. Feature jobs push many small reads and writes. Inference systems load model artifacts and warm caches during scaling events. When storage adds jitter, the pipeline drifts from “repeatable” to “unpredictable,” and teams overprovision GPUs to hide the delay.
Design Choices That Speed Up Data and Model Flows
A reliable pipeline starts with the data path. Put datasets, features, and checkpoints on storage that keeps latency stable under parallel access. Use clear boundaries between hot data (active training sets and checkpoints) and warm data (older runs and archived artifacts). Keep metadata responsive, too, because “small” lookups can stall a large job fan-out.
For platform teams, this often means standardizing Kubernetes Storage so every step uses the same provisioning, quotas, and policies. For executives, it reduces cost surprises and shortens delivery cycles because teams spend less time debugging “slow runs” that have no code change behind them.
🚀 Run AI Pipelines on NVMe/TCP Storage, Natively in Kubernetes
Use simplyblock to reduce GPU idle time, speed up checkpoints, and scale Kubernetes Storage with confidence.
👉 Use Simplyblock for AI and ML on Kubernetes →
AI Pipeline in Kubernetes Storage
When you run AI workloads on Kubernetes, the pipeline touches storage through PersistentVolumeClaims, StorageClasses, and CSI drivers. This makes operations consistent, but it also makes contention more visible. A single training job can flood the storage plane with parallel reads. A busy feature job can create long tail latency for every other tenant.
A practical model separates concerns. Teams keep fast block volumes for active datasets and checkpoints, and they apply quotas and QoS so one namespace cannot starve another. Software-defined Block Storage helps here because it can enforce volume-level controls and simplify multi-tenant policy without forcing every team to change their workload design.
AI Pipeline and NVMe/TCP
NVMe/TCP gives Kubernetes environments a strong option for high-throughput block access over standard Ethernet. It keeps NVMe semantics across the network, and it scales well in clusters that want a SAN alternative without RDMA-only constraints. For AI workloads, that matters because parallel reads and checkpoint bursts can expose weak links fast.
A user-space, zero-copy storage data path can also cut CPU overhead in the storage plane. That frees cycles for networking and reduces jitter when many pods push I/O at once. Simplyblock highlights this SPDK-based approach as part of its NVMe/TCP storage path.
Benchmarking an AI Pipeline
Benchmark the pipeline the way it runs, not the way it “should” run. Measure dataset read rate during training, checkpoint write time, and restart recovery time. Track p95 and p99 latency during peak concurrency, because tail delays often drive missed training windows. Correlate storage metrics with node CPU, network drops, and GPU idle time so you can see whether storage stalls the job scheduler.
Keep benchmarks repeatable. Fix the dataset subset, the batch size, and the number of workers. Run the same test at different concurrency levels, and chart how throughput drops when the cluster gets busy.
Fixes That Improve Throughput and Reduce GPU Idle Time
- Match volume type to I/O pattern, and reserve the fastest path for active datasets and checkpoints.
- Cap noisy tenants with QoS so one job cannot drain shared queues.
- Tune parallelism to the storage limit so you avoid “more workers, slower run.”
- Keep the network consistent, and size it for bursts during checkpoint writes.
- Prefer efficient, user-space data paths when CPU becomes the bottleneck.
- Track tail latency and retry rates, and alert before GPU idle time spikes.
AI Storage Options Compared
This comparison helps teams pick an approach that fits cost, speed, and day-2 operations.
| Option | Strengths | Trade-offs | Typical fit |
|---|---|---|---|
| Local NVMe on GPU nodes | Very low latency | Hard to share, harder failover | Single-node training, caches |
| Network file storage | Simple sharing | Metadata overhead, jitter under load | Shared artifacts, light I/O |
| Network block over Ethernet | Strong throughput, scalable | Needs good QoS and planning | Training datasets, checkpoints |
| Software-defined block with policy | Multi-tenant control, clear ops | Requires platform standard | Mixed pipelines at scale |
Simplyblock™ for Stable AI Data Paths
Simplyblock™ targets predictable performance for data-heavy workloads on Kubernetes, including AI and ML use cases. It combines Software-defined Block Storage controls with NVMe-first design and NVMe/TCP support, which helps teams keep throughput high while holding tail latency in check.
That balance matters when pipelines run many parallel workers and write frequent checkpoints.
What Comes Next for ML Data Operations
Teams now push toward tighter feedback loops: faster retraining, more frequent model updates, and stronger governance around datasets and artifacts. As that pace increases, storage policy, observability, and isolation move from “nice to have” to mandatory.
DPUs and IPUs can also shift CPU load away from hosts, which can help keep storage service levels steady in dense clusters.
Related Terms
Teams often review these glossary pages alongside the AI Pipeline when they tune Kubernetes Storage paths and keep training runs consistent.
Questions and Answers
An AI pipeline is a sequence of automated steps that process data, train models, and deploy AI applications. These pipelines require high-performance infrastructure, often backed by software-defined storage to handle large datasets efficiently across stages.
AI pipelines are storage-intensive, especially during model training and feature extraction. Low storage latency and high throughput ensure faster iteration cycles and prevent bottlenecks in compute-heavy tasks like deep learning and inferencing.
NVMe over TCP provides low-latency, high-throughput access to storage across standard Ethernet, making it ideal for AI workloads. It scales well across Kubernetes, enabling fast, parallel data access during model training and evaluation.
AI pipelines benefit from scalable, distributed, and container-native storage solutions. Using Kubernetes-native NVMe storage ensures elastic scaling, fast provisioning, and support for GPUs and stateful workloads in hybrid or cloud-native environments.
Simplyblock optimizes every stage of the AI pipeline by combining NVMe storage with dynamic provisioning, encryption, and Kubernetes support. This ensures fast data loading, checkpointing, and inference, while maintaining efficiency and data security.