Region vs Availability Zone
Terms related to simplyblock
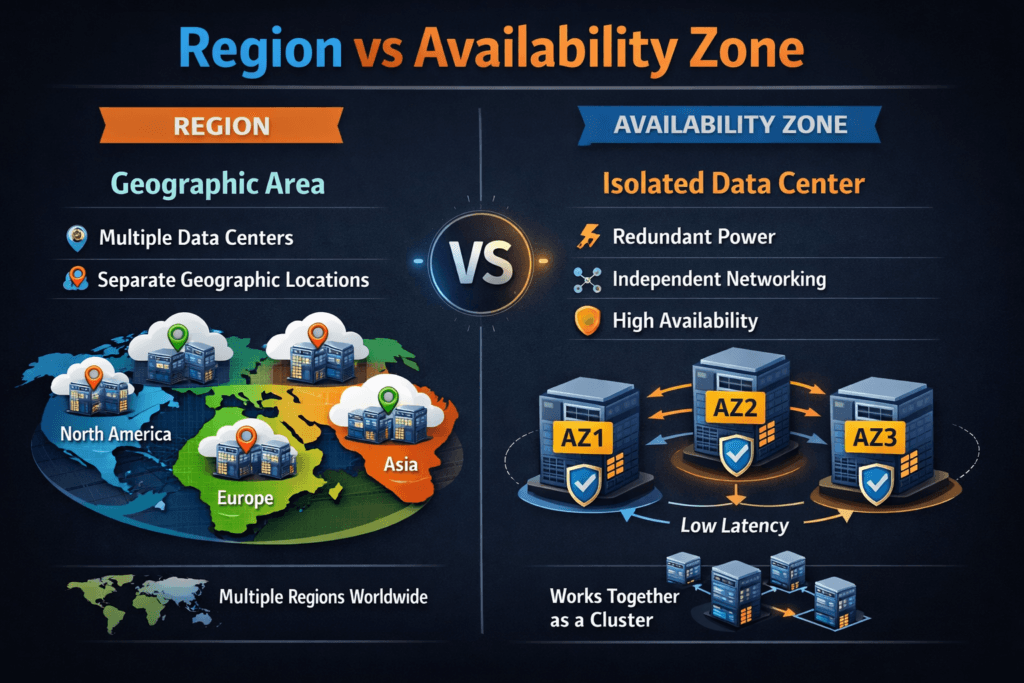
A Region is a geographic area where a cloud provider operates infrastructure. An Availability Zone (AZ) is an isolated failure domain inside a Region, designed to reduce shared-risk events such as power, cooling, or local network failures. Regions drive data residency and broad disaster recovery design, while AZs drive day-to-day high availability design.
For most stateful platforms, the Region vs Availability Zone choice becomes a trade-off between latency and fault separation. Zone-local placement usually delivers lower latency and steadier tail behavior. Cross-zone replication improves resilience to zone loss, but it adds network hops and background work that can raise p99 latency if you do not control it.
Optimizing multi-region and multi-zone placement with current solutions
Teams get better outcomes when they match the failure domain to the business target. Many organizations treat an Availability Zone as the default unit of high availability, then treat the Region as the boundary for compliance, sovereignty, and larger-scale disaster scenarios.
A common approach keeps the steady-state IO path zone-local, then applies cross-zone replication for durable datasets. Cross-region replication often stays reserved for true disaster recovery because it increases latency and usually costs more in network egress and operational complexity. This layered design also keeps change management simpler because you can evolve the recovery policy without redesigning the entire storage stack.
For executives, the important point is that you can buy resilience in two ways: by placing replicas across AZs, or by pushing copies across Regions. The first option aims at fast recovery. The second option aims at geographic separation.
🚀 Run Multi-AZ Kubernetes Storage Across Availability Zones and Regions
Use Simplyblock to keep zone-local latency low while scaling resilient NVMe/TCP volumes.
👉 Use Simplyblock for Kubernetes NVMe/TCP Storage →
Region vs Availability Zone in Kubernetes Storage
In Kubernetes Storage, topology rules decide where pods run and where volumes land. If the platform places a volume in one Availability Zone and schedules the pod in another, the mount workflow often fails or stalls. Topology-aware provisioning prevents that mismatch by aligning volume placement with the pod’s failure domain.
Multi-AZ clusters also need predictable scheduling during rolling updates, node drains, and sudden reschedules. Teams often pair topology spreading with storage-aware placement so they can distribute replicas across zones while still respecting volume locality. That reduces both outage risk and operational friction because the cluster makes fewer “impossible placement” decisions.
Region vs Availability Zone and NVMe/TCP
NVMe/TCP enables disaggregated storage over standard Ethernet, which makes it easier to run consistent storage designs across bare metal, virtualized infrastructure, and managed Kubernetes. That consistency matters when you operate in multiple Availability Zones and want one operational model.
The Region and AZ boundary affect NVMe/TCP in two main ways. First, it changes replication latency because cross-zone links add hop count and contention. Second, it changes recovery load because resync and rebuild traffic increase sharply after failures. Storage stacks that keep the IO path efficient can preserve CPU for applications while handling replication and rebuild activity.
SPDK-style user-space design helps here because it reduces kernel overhead and improves CPU efficiency in the data path. In multi-zone designs, that extra headroom often shows up as steadier tail latency during recovery windows.
Measuring and Benchmarking Region vs Availability Zone Performance
Benchmarking should mirror production placement and policy, not best-case lab assumptions. Use the same StorageClass behavior, the same replica policy, and the same scheduling rules you plan to run in production.
Measure average latency, p95 and p99 latency, IOPS, throughput, CPU per IO, and east-west network utilization. Run a baseline test with compute and storage in the same Availability Zone. Then repeat with cross-zone replication enabled. After that, run a disruption test under load, such as draining nodes or cordoning a zone, and track reattach time, resync duration, and tail latency impact.
For shared platforms, add a contention test that simulates noisy neighbors. Multi-tenant behavior often determines real performance more than peak throughput numbers.
Practical ways to improve multi-zone storage performance
Use one repeatable playbook for latency, resilience, and recovery behavior. This avoids one-off tuning per team and reduces surprises during incidents. The actions below often deliver the most improvement.
- Keep a steady-state IO zone-local when the app can tolerate zone loss through restart or failover.
- Use topology-aware provisioning so volumes land in the same Availability Zone as the pods that write to them.
- Apply replication per workload tier so you do not pay cross-zone cost for every dataset.
- Enforce QoS to protect business-critical workloads from noisy neighbors.
- Test resync and rebuild under load because failures turn background work into the main limiter.
Region and zone trade-offs at a glance
This table summarizes what changes when you move the fault boundary from a single Availability Zone to a full Region. It also shows why Kubernetes Storage policy and Software-defined Block Storage controls matter in multi-AZ operations.
| Dimension | Region | Availability Zone (AZ) |
|---|---|---|
| Scope | Separate geographic area | Isolated location inside a Region |
| Main goal | Data residency, broad disaster recovery boundary | High availability, fault isolation |
| Latency profile | Higher between regions | Lower inside one region’s zones |
| Common failure event | Regional service impact, wide outage | Zone-local power, cooling, or network incident |
| Typical storage policy | Cross-region DR, async replication | Cross-zone replication, fast failover |
| Kubernetes focus | Multi-cluster policy, compliance | Topology-aware provisioning, pod spreading |
How Simplyblock™ keeps multi-zone storage predictable
Simplyblock helps teams run Software-defined Block Storage across Availability Zones without letting replication traffic or rebuild work disrupt application latency. The platform focuses on an efficient IO path and policy controls that matter in production, including multi-tenancy, QoS, and replication choices aligned to zone-level failure domains. With NVMe/TCP, teams keep the fabric simple on standard Ethernet while still supporting disaggregated storage layouts.
This model supports hyper-converged, disaggregated, and mixed deployments for Kubernetes Storage. Teams can keep zone-local performance for the hot path, replicate across zones for resilience, and maintain predictable behavior during node drains and zone events.
Where multi-zone cloud design is headed
Cloud providers continue to expand zone coverage and offer more options that sit between a single region and full cross-region designs. Platform teams increasingly treat topology as a first-class input to scheduling, provisioning, and recovery planning.
On the storage side, more systems will offload data-path work to DPUs and IPUs, especially for encryption, replication, and packet handling. That shift increases the value of low-overhead IO paths because the platform can preserve CPU for applications while it handles recovery work. As these patterns mature, NVMe/TCP, Kubernetes Storage, and Software-defined Block Storage will converge further into one operational model across hybrid environments.
Related Terms
Teams often review these glossary pages alongside Region vs Availability Zone when they set availability targets for Kubernetes Storage and Software-defined Block Storage.
- CSI Topology Awareness
- Kubernetes Topology Constraints
- Cross-Zone Replication
- Storage High Availability
Questions and Answers
A Region is a geographical area, while an Availability Zone (AZ) is an isolated data center within that region. In cloud infrastructure, using multiple AZs within a Region ensures higher availability and redundancy, which is crucial for distributed storage systems.
Availability Zones provide fault isolation within a Region. If one AZ goes down, services in another can stay operational. For workloads like Kubernetes backups or databases, AZs allow you to build highly available and resilient architectures.
Latency between Availability Zones is low, but cross-Region traffic can introduce significant delay. For optimal p99 latency and throughput, it’s best to deploy your storage and compute in the same AZ whenever possible.
Yes, but the cost and complexity vary. Replicating across AZs is common for RPO and RTO reduction, while cross-Region replication adds geo-redundancy but increases latency. Simplyblock supports both synchronous and asynchronous replication for flexible resilience.
Multi-AZ deployment is typically sufficient for most use cases and offers lower latency. Multi-Region is better for disaster recovery and compliance. For cloud-native storage, combining both ensures maximum uptime and data protection.