Scale-Out Storage Architecture
Terms related to simplyblock
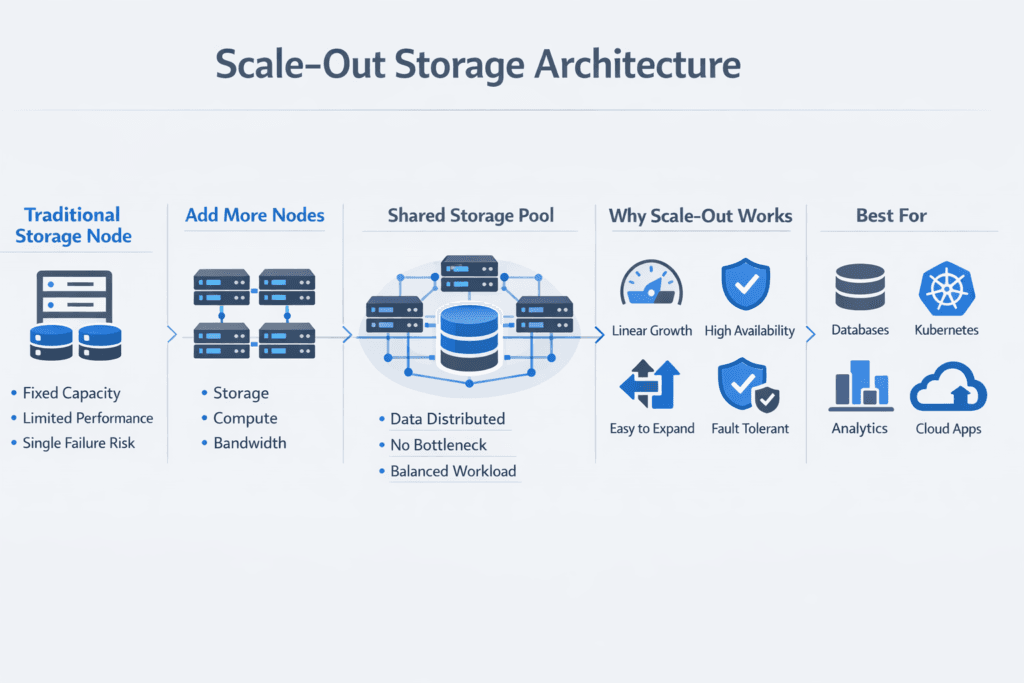
Scale-Out Storage Architecture is a cluster-based design where capacity and performance grow by adding nodes instead of upgrading a single storage controller. Each node contributes compute, network bandwidth, and media, and the cluster presents shared volumes to applications with consistent policies.
For executive teams, the value typically comes from predictable growth, reduced forklift upgrades, and a cleaner path away from proprietary arrays. For platform teams, the benefit shows up in simpler expansion, clearer failure domains, and a control plane that enforces workload intent. When this model is delivered as Software-defined Block Storage, policy and automation control data placement, rebuild pacing, and tenant isolation as the environment grows.
Scale-out designs often pair with NVMe media because NVMe supports deep parallelism and high queue counts, which align with distributed I/O paths.
Architectural patterns that scale cleanly under load
Most scale-out systems perform well when they keep the I/O path short, avoid shared choke points, and limit cross-node chatter. A strong design combines fast media, a fabric transport that matches operational realities, and a control plane that keeps volumes balanced over time.
User-space datapaths matter because they reduce context switches and extra memory copies. That reduces CPU burn per I/O and helps stabilize tail latency under concurrency. You also want predictable behavior during events like node loss, pool expansion, and rebuilds, because those moments expose architectural weak spots faster than steady-state benchmarks.
🚀 Scale Storage Capacity and Performance Without Forklift Upgrades
Use Simplyblock to expand your Kubernetes storage cluster node by node, with tenant-safe QoS.
👉 Book a Simplyblock Scale-Out Storage Demo →
Scale-Out Storage Architecture in Kubernetes Storage
Kubernetes Storage changes the requirements because pods reschedule, nodes churn, and persistent volumes must stay available without manual steps. A scale-out backend fits this model because it already expects node changes and spreads risk across the cluster.
Operationally, you want CSI-driven provisioning that supports fast volume creation, online expansion, and snapshot and clone workflows for CI and recovery. Topology-aware placement also matters. Hyper-converged layouts can reduce latency by keeping storage services near workloads, while disaggregated pools let teams scale storage independently when compute growth does not match capacity growth.
Multi-tenancy adds another constraint. Platform teams need guardrails that prevent one namespace from dragging p99 latency above the target for everyone else.
Scale-Out Storage Architecture and NVMe/TCP
NVMe/TCP is a common choice for scale-out clusters because it runs on standard Ethernet and fits typical enterprise and cloud operations. It also creates a practical migration path: teams can standardize on TCP first, then add RDMA-backed pools later for workloads with strict latency targets.
In a mixed environment, general workloads can run on NVMe/TCP volumes while a smaller set of performance-critical volumes uses RDMA over a tuned, lossless fabric. This split works best when one control plane manages both transports and applies the same tenant and QoS policies across pools.
How to measure scale-out performance without misleading numbers
Benchmarking a scale-out system requires more than a single “IOPS” headline. You need to confirm how performance changes as you add nodes, mix workloads, and introduce failure or rebuild pressure.
Measure latency distribution, not only averages. Track p50, p95, and p99 latency, and validate that p99 stays within the target during bursts. Watch CPU per I/O as well, because CPU-heavy data paths raise compute cost and reduce headroom for recovery events.
In Kubernetes, repeat tests through real PVCs and StorageClasses, because sidecars, networking, and scheduling can shift outcomes. If you run databases, include fsync-heavy patterns and mixed read/write profiles, not only read-only tests.
Tuning strategies for lower latency and higher throughput
Most performance gains come from removing bottlenecks and controlling variance across tenants. The following actions often produce measurable improvement and translate well to scale-out operations.
- Keep the hot path efficient with a user-space NVMe stack and reduce extra memory copies where possible.
- Validate the network early by checking MTU consistency, congestion behavior, and oversubscription ratios.
- Enforce QoS to prevent noisy neighbors from pushing tail latency above the target.
- Separate pools by workload class so rebuild and background tasks do not collide with the hottest volumes.
- Re-test during failure and rebuild scenarios, because steady-state numbers rarely match production stress.
Architectural trade-offs across SAN, scale-up arrays, and SDS
The table below summarizes common storage approaches and how they behave when node counts, tenants, and throughput requirements rise.
| Approach | How growth happens | Common constraints | Best fit |
|---|---|---|---|
| Scale-up array | Upgrade controllers, add shelves | Controller ceilings, forklift cycles, vendor lock-in | Smaller, stable environments |
| Traditional SAN | Expand behind fabric | Cost, operational overhead, complex tuning | Legacy enterprise stacks |
| Scale-out SDS | Add nodes for capacity and throughput | Needs strong balancing and tenant controls | Cloud-native, multi-tenant growth |
| Software-defined Block Storage (simplyblock model) | Add nodes, mix hyper-converged and disaggregated | Requires policy planning for pools and tenants | Kubernetes-first scale and SAN alternative |
Predictable operations with Simplyblock™ at cluster scale
Simplyblock targets predictable behavior as clusters grow by using an SPDK-based, user-space, zero-copy data path that reduces overhead and keeps CPU use efficient under concurrency. It supports NVMe/TCP and RDMA options, which let teams align performance with operational complexity instead of locking into one fabric.
For Kubernetes Storage, simplyblock supports hyper-converged, disaggregated, and hybrid layouts in one platform. Multi-tenancy and QoS controls help keep one workload from distorting another. That protects tail latency and makes capacity planning more reliable as node counts rise.
Roadmap trends – DPUs, multi-fabric NVMe-oF, and policy-driven automation
Scale-out roadmaps increasingly include DPUs/IPUs, where storage targets can run closer to the network and shift work off application CPUs. Multi-fabric designs also appear more often, especially when teams use NVMe/TCP broadly and reserve RDMA for the tightest latency targets. Policy-driven automation continues to expand because operators need safe defaults for placement, rebuild pacing, and tenant isolation as clusters grow.
Standardization around observable SLOs will also accelerate. More teams now treat storage as a measurable platform service, with latency budgets tied directly to application health and rollout safety.
Related Terms
Teams reference these related terms when implementing Scale-Out Storage Architecture in Kubernetes Storage with Software-defined Block Storage.
Questions and Answers
Scale-out storage architectures provide elastic scalability by distributing data and I/O across nodes, making them ideal for environments with fluctuating demands like Kubernetes or multi-tenant SaaS. This design ensures consistent performance even under unpredictable load and enables seamless capacity expansion.
Scale-up storage scales vertically by adding resources to a single system, often leading to bottlenecks. Scale-out architectures add entire nodes, improving redundancy, throughput, and storage efficiency. This horizontal design is better aligned with cloud-native and containerized environments.
Scale-out systems support Kubernetes through features like dynamic provisioning, multi-zone replication, and failover. With CSI-integrated storage like Simplyblock, you get low-latency, NVMe-based performance and scalability tailored for containerized workloads.
Absolutely. NVMe drives reduce latency and maximize parallelism, which aligns perfectly with scale-out storage models. When used with NVMe over TCP, NVMe allows distributed clusters to scale linearly using standard Ethernet networks.
Scale-out storage is used in data lakes, AI/ML training, streaming platforms, and Kubernetes backups. It enables high throughput, availability, and fault tolerance, which are essential for performance-sensitive or rapidly growing infrastructures.