Distributed Block Storage Architecture
Terms related to simplyblock
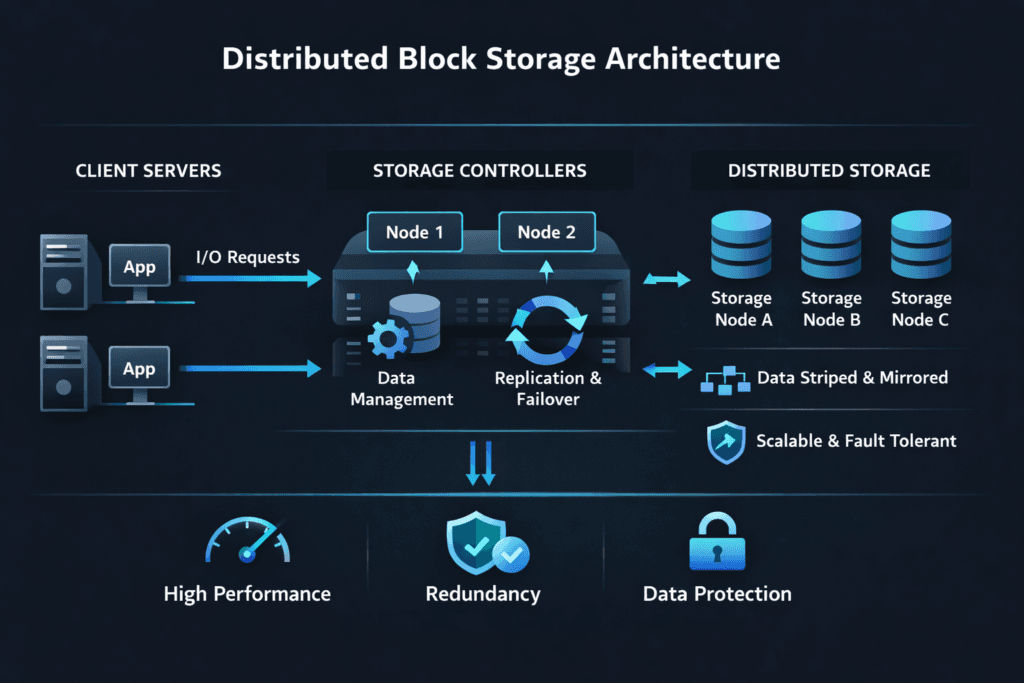
Distributed Block Storage Architecture describes a block storage design that spreads data, metadata, and I/O work across multiple nodes. Instead of relying on one storage controller, the cluster shares responsibility for placement, protection, and rebuilds. This model supports horizontal growth because you add nodes to raise capacity and performance without replacing a central array.
Leaders adopt this architecture to avoid forklift upgrades and reduce platform risk. Operations teams like it because the system can automate volume lifecycle tasks and keep the same runbook as the cluster grows. In many environments, the architecture also serves as a SAN alternative when teams want faster change control and fewer vendor ties.
Distributed designs often pair with Software-defined Block Storage. Software sets the rules for durability, placement, and performance, while standard servers and NVMe media provide the raw power.
Core Building Blocks That Make Distribution Work
A distributed block system succeeds when it keeps the data path fast and the control plane clear. The control plane tracks where blocks live, how volumes map to nodes, and which policies apply. The data plane handles reads and writes, rebuilds, and background tasks.
Placement strategy matters. Good systems balance hot data across nodes and avoid “hot spots” that raise tail latency. Fault domain awareness also matters. When the platform understands racks, zones, or hosts, it can place replicas or erasure-coded stripes across failure boundaries.
Protection choices shape cost and speed. Replication keeps the model simple and reduces rebuild math. Erasure coding can raise usable capacity, but it needs smart scheduling so background work does not steal bandwidth from foreground I/O.
🚀 Standardize Distributed Block Storage Architecture for Kubernetes Storage on NVMe/TCP
Use Simplyblock to scale volumes across nodes, apply QoS per tenant, and keep latency predictable.
👉 See Simplyblock’s Architecture and Data Path →
Distributed Block Storage Architecture for Kubernetes Storage
Kubernetes Storage puts pressure on block systems in a unique way. It creates many small volumes, changes attachments often, and runs mixed workloads side by side. A distributed architecture fits well when the storage platform can translate storage policies into volume behavior with consistent results.
Topology plays a big role. Hyper-converged layouts keep storage close to compute to cut hop count. Disaggregated layouts separate compute and storage so each can scale on its own. Hybrid layouts let one cluster run both patterns, which helps when databases and general services share the same platform.
Multi-tenancy also becomes a first-class need. The storage layer must stop one noisy workload from pushing latency up for others. Strong isolation and QoS controls keep SLOs realistic in shared Kubernetes clusters.
Distributed Block Storage Architecture with NVMe/TCP
NVMe/TCP brings NVMe semantics over standard Ethernet and TCP/IP, which makes it practical for broad rollouts. Teams can keep familiar network tools and still deliver a modern block protocol to hosts.
CPU cost matters with NVMe/TCP, so the I/O stack must stay lean. User-space, SPDK-style designs help here because they reduce kernel overhead and cut needless copies. That efficiency helps the platform sustain high queue depth while keeping CPU use in check.
When an organization needs even tighter latency, it can add RDMA-capable pools for specific tiers. The key point stays the same: the architecture should keep one operational model while letting teams choose the right fabric per workload.
Benchmarking Distributed Block Storage Architecture for Real Scale
Benchmarks should show scaling behavior, not just peak numbers on one node. Start with clear workload shapes: block size, read/write mix, queue depth, and concurrency. Then track IOPS, throughput, and p95/p99 latency as you add nodes.
Tail latency deserves special focus. Many apps fail due to the slow outliers, even when the averages look fine. Kubernetes adds more variance through shared networks and busy nodes, so tests should include multi-tenant pressure when possible.
CPU per I/O also belongs in the report. If storage consumes too many cores, the platform loses density. That tradeoff shows up quickly at scale.
Practical Tuning to Reduce Latency Drift
Most gains come from reducing variance, keeping rebuild work under control, and enforcing isolation. Use this checklist to guide changes and validation:
- Keep the data path short, and avoid extra copies when the platform supports it.
- Set QoS limits per tenant or workload class to prevent queue takeover.
- Validate the network first, including MTU consistency and congestion behavior.
- Use repeatable fio profiles, and gate changes on p95 and p99 latency.
- Limit rebuild and rebalance impact so foreground I/O stays steady during node events.
How Distributed Architectures Compare in Production
The table below compares common block storage approaches, with a focus on how they behave as node count and workload mix grow.
| Attribute | Traditional SAN Array | Single-Node Block Service | Distributed Block Storage Architecture |
|---|---|---|---|
| Growth method | Upgrade controllers and shelves | Replace the node | Add nodes to the cluster |
| Failure model | Controller-centric | Host-centric | Shared responsibility across nodes |
| Kubernetes fit | Often added later | Limited scale | Built for cluster operations |
| Performance scaling | Peaks early | Peaks early | Improves with node count when balanced |
| Isolation controls | Array policies | Minimal | Tenant-aware QoS and policy control |
| Operational model | Vendor workflows | Local tooling | Central policies with automation |
Distributed Block Storage Architecture with Simplyblock™
Simplyblock™ builds around a distributed model designed for NVMe media and high concurrency. Simplyblock uses NVMe/TCP as a primary transport option and targets Kubernetes Storage deployments that need consistent operations across clusters.
The platform also leans on SPDK-style, user-space performance principles to reduce overhead in the I/O path. That approach helps keep latency steadier as load rises and tenants share the same pool. Multi-tenancy and QoS controls add another layer of predictability, because they give teams direct levers to limit noisy-neighbor impact.
Next Steps for Distributed Designs
Distributed storage keeps moving toward tighter automation and simpler scale. Expect smarter placement that reacts to live load, faster rebalancing that avoids disruption, and better scheduling of background work. More environments will also adopt offload paths via DPUs or IPUs to reduce host CPU usage while sustaining high IOPS.
At the platform layer, deeper alignment with Kubernetes scheduling and topology signals will help teams get the right volume behavior with fewer manual steps.
Related Terms
Teams review these pages in the context of the Distributed Block Storage Architecture.
Questions and Answers
Distributed block storage ensures high availability by replicating data across nodes and implementing quorum-based write consistency. When a node fails, others continue serving I/O without data loss. Simplyblock leverages this model to support fault-tolerant Kubernetes storage and synchronous replication.
Centralized systems often have single points of failure and limited scalability. Distributed block storage spreads data across multiple nodes, enabling horizontal scaling and built-in redundancy. This architecture is ideal for modern infrastructures that require resilience and elasticity.
Yes, NVMe offers low-latency, high-throughput performance and integrates well with distributed block storage systems—especially when combined with NVMe over TCP. It enables each node to contribute local NVMe capacity to the overall cluster.
Stateful workloads like databases, analytics engines, and persistent containers gain the most from distributed block storage. It ensures data durability, scalability, and performance isolation—particularly in multi-tenant Kubernetes clusters or virtualized environments.
Simplyblock delivers a fully distributed block storage backend using NVMe over TCP. It features per-volume encryption, replication, and dynamic provisioning via CSI—making it a powerful foundation for Kubernetes and VM workloads that demand resilience and speed.