SPDK Architecture
Terms related to simplyblock
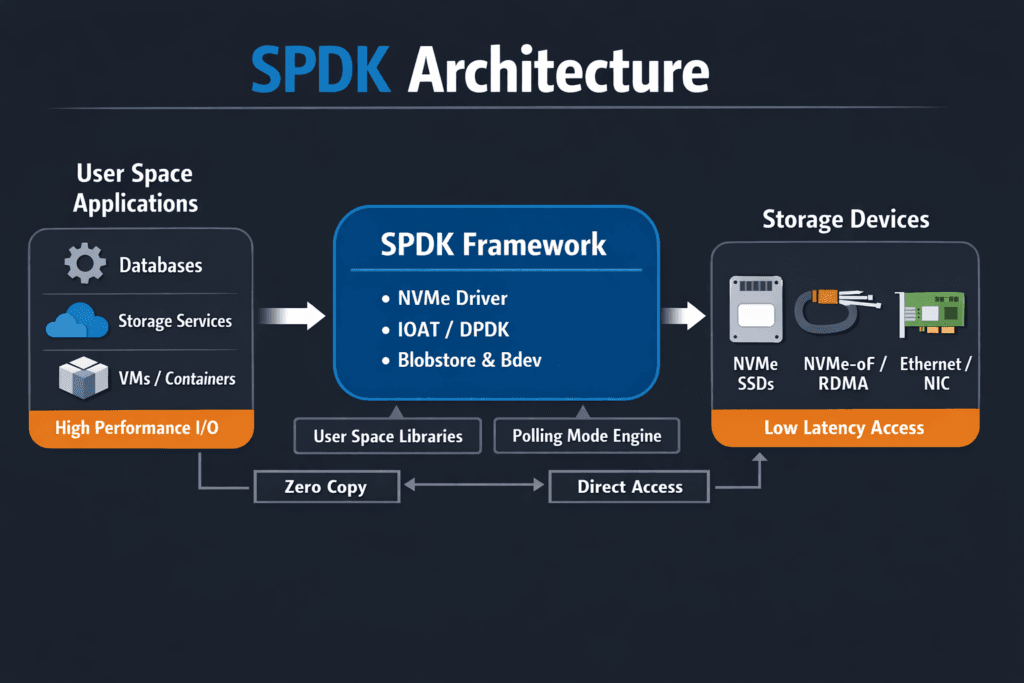
SPDK Architecture explains how the Storage Performance Development Kit runs storage services in the user space to cut kernel overhead, lower latency, and raise IOPS per CPU core. Teams adopt this approach when fast NVMe media and fast networks expose limits in the Linux kernel IO path.
Leaders care about two outcomes: steadier app latency and better cost per workload. Platform teams care about repeatable performance under load, especially when many services share the same storage pool. SPDK often becomes the missing piece when NVMe/TCP and Kubernetes Storage push concurrency high enough to make CPU overhead the real bottleneck.
Cutting IO Overhead with User-Space Storage Design
User-space storage keeps the hot path short. It avoids many context switches and cuts extra copies that add jitter. That design helps most when systems run near peak, because tail latency grows fast when the IO path wastes CPU.
A strong design also needs controls, not only speed. It must enforce limits per volume, keep background jobs from stealing IO time, and isolate tenants with a clear policy. These controls matter in Software-defined Block Storage, where shared pools need clear rules to stay predictable.
🚀 Build SPDK-Accelerated NVMe/TCP Storage in Kubernetes
Use Simplyblock to cut CPU overhead, tighten p99 latency, and enforce QoS in Software-defined Block Storage.
👉 Use Simplyblock for NVMe over Fabrics & SPDK →
SPDK Architecture in Kubernetes Storage
Kubernetes Storage adds churn: pod moves, rolling updates, reschedules, and noisy neighbors. A storage stack that burns CPU in the kernel tends to show wider p99 latency during this churn. SPDK keeps more work in a stable user-space path, which can reduce variance when the cluster gets busy.
In practice, teams tie SPDK-based performance to storage classes. They define tiers for databases, streaming, and batch. Each tier sets limits for IOPS and throughput, and then the platform enforces the rules close to the datapath. That approach keeps Kubernetes operations fast while reducing surprises for stateful apps.
SPDK Architecture and NVMe/TCP
NVMe/TCP brings NVMe semantics over standard Ethernet, so teams can scale without a specialized fabric. SPDK Architecture pairs well with NVMe/TCP because both benefit from high parallelism. As concurrency rises, CPU cost per IO becomes a key metric, and SPDK targets that cost.
This pairing also fits disaggregated storage designs. Compute can scale on one schedule, and storage can scale on another. That model maps cleanly to Kubernetes Storage, where teams add nodes, expand pools, and shift workloads often.
Measuring SPDK Architecture Performance
Good measurement goes beyond peak IOPS. It also checks p95 and p99 latency under load, CPU per IO, and how the curve behaves as queue depth rises. Stable results across repeated runs matter more than one best run.
Match tests to the app. Small-block random IO often matches databases. Steady writes often match logs. Large reads often match analytics. Run tests with real concurrency, because shared clusters show the real behavior only under overlap.
Approaches for Improving SPDK Architecture Performance
Most wins come from a short set of checks. Keep changes small, measure again, and record a baseline you can repeat.
- Pin storage services and critical apps to stable CPU sets, and keep NUMA alignment consistent.
- Use storage classes as tiers, and set clear caps for IOPS and throughput where fairness matters.
- Tune NVMe/TCP host networking for steady latency, including MTU, IRQ placement, and CPU pinning.
- Watch p99 latency with queue depth to catch early saturation.
- Control background work with QoS so rebuilds, snapshots, and scrubs do not create spikes.
Comparison of IO Stack Choices for NVMe-Based Storage
The table below compares common IO stack choices teams evaluate when they modernize Kubernetes Storage. It highlights trade-offs that show up fast in Software-defined Block Storage.
| IO stack choice | Typical tail latency under load | CPU efficiency | Best fit |
|---|---|---|---|
| Kernel-based NVMe path | Often widens at peak | Moderate | General workloads, simpler tuning |
| User-space SPDK datapath | Often stays tighter | High | High-IOPS databases, shared clusters |
| RDMA-only designs | Lowest tail latency potential | High, fabric-dependent | Strict latency tiers |
| NVMe/TCP plus strong QoS | Strong balance on Ethernet | High with the right engine | Scale-out Kubernetes Storage |
Keeping Latency Steady with Simplyblock™ and Storage QoS
Simplyblock™ uses an SPDK-based, user-space, zero-copy datapath to reduce overhead in the hot path. This design helps keep CPU cost low and p99 latency steady as concurrency rises. It also supports NVMe/TCP and NVMe/RoCEv2, so teams can use standard Ethernet broadly and reserve RDMA for strict tiers.
Simplyblock™ also targets day-two needs that matter in production: multi-tenancy, QoS, and repeatable performance tiers. Those controls reduce noisy-neighbor risk and keep storage behavior aligned with Kubernetes Storage classes and business SLAs.
What Comes Next for SPDK Architecture – Offload and Zero-Copy
SPDK Architecture reduces CPU overhead by running the storage datapath in user space. As NVMe devices get faster, teams often hit CPU limits before they hit media limits. Offload options such as DPUs and IPUs can take on parts of the NVMe/TCP or NVMe-oF work, which keeps host cores available for apps and helps control tail latency.
Zero-copy IO also stays central to SPDK Architecture. When the datapath avoids extra memory copies, it reduces jitter and keeps latency more stable during bursts, especially in shared Kubernetes Storage environments.
Related Terms
These glossary pages help teams connect SPDK Architecture to NVMe/TCP performance, tenant fairness, and low-jitter IO paths.
Questions and Answers
The SPDK (Storage Performance Development Kit) architecture bypasses the kernel and uses user-space drivers with polling mode I/O to eliminate context switching. This drastically reduces latency and improves IOPS, especially for NVMe-based storage in high-performance environments.
SPDK includes user-space NVMe drivers, a polling-based I/O model, CPU core pinning, and zero-copy data paths. These components work together to achieve ultra-low latency and high throughput, especially in distributed storage systems using NVMe and NVMe-oF.
Unlike traditional kernel-based stacks that rely on interrupts and context switching, SPDK runs entirely in user space with dedicated CPU cores for I/O. This reduces overhead and delivers consistent performance — particularly useful in software-defined block storage platforms.
Yes, SPDK supports NVMe-oF transports such as TCP and RDMA. It’s especially effective when combined with NVMe over TCP, enabling low-latency, kernel-bypass I/O across standard Ethernet networks for scalable, high-speed block storage.
While not publicly disclosed in detail, Simplyblock’s platform focuses on delivering high-performance NVMe over TCP block storage with low latency and high IOPS. SPDK-like architectural principles such as polling I/O and core isolation are common in modern SDS backends.