Storage IO Path in Kubernetes
Terms related to simplyblock
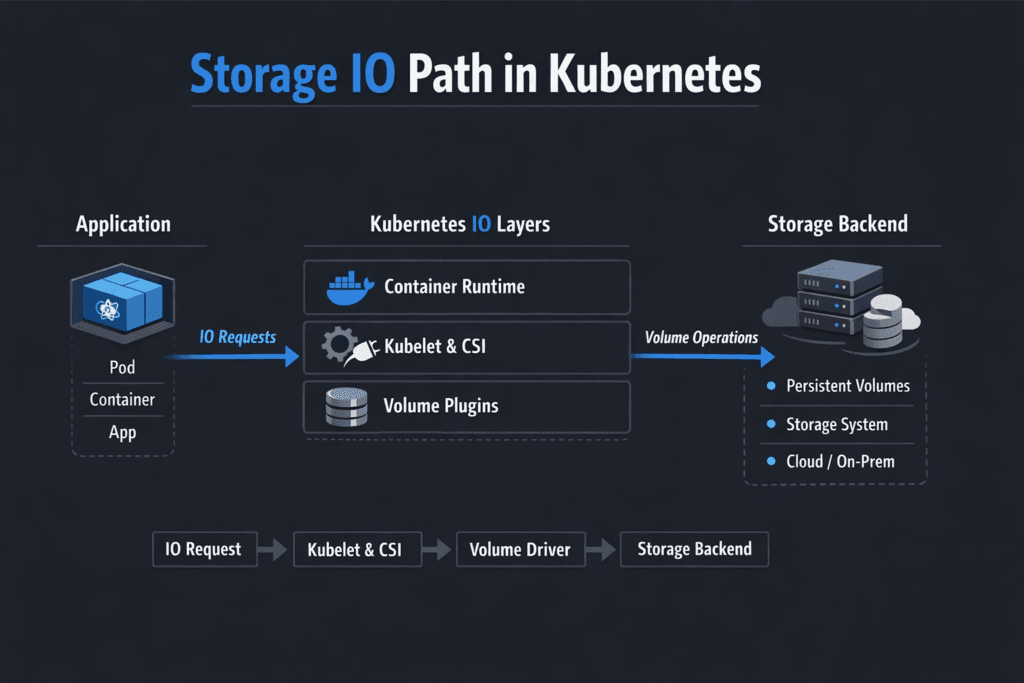
Storage IO Path in Kubernetes describes the exact route every read and write takes from an app running in a Pod to persistent media, and back. The path usually starts at the application syscall, passes through the container runtime and kubelet, hits the Container Storage Interface (CSI) components, and then reaches either local NVMe or a remote target over the network. Each layer adds latency, CPU overhead, queueing, and failure points, so the IO path often explains why “fast disks” still produce uneven p99 latency for databases and analytics.
In Kubernetes Storage, the IO path becomes a platform concern, not a single-team tuning task. Node churn, rescheduling, multi-tenancy, and rolling upgrades change IO patterns every day. A stable path protects both service levels and infrastructure spend because it reduces overprovisioning that teams use to hide storage jitter.
Reducing Storage Latency and CPU Overhead in the Kubernetes Data Plane
Teams improve the IO path when they reduce context switches, avoid extra memory copies, and keep queues short under load. Kernel-heavy stacks can burn CPU on interrupts and copies, which shows up as higher tail latency when concurrency rises. User-space data planes based on SPDK can cut overhead because they keep IO processing close to the device and avoid avoidable kernel transitions.
For Software-defined Block Storage, the goal is consistent behavior across nodes, clusters, and failure domains. That means you want predictable queue depth behavior, clear isolation between tenants, and a control plane that does not interfere with the hot path during routine operations. A Kubernetes-native storage platform should also support both hyper-converged and disaggregated deployment models so you can align storage placement with risk, cost, and performance targets.
🚀 Shorten the Storage IO Path in Kubernetes with Multi-Tenant QoS
Use Simplyblock to isolate workloads, cap noisy neighbors, and keep p99 latency stable.
👉 Use Simplyblock for Multi-Tenancy and QoS →
Optimizing the Storage IO Path in Kubernetes
A typical CSI-backed Kubernetes Storage path looks like this: Pod → kubelet → CSI node plugin → device mount → filesystem or raw block → network transport (optional) → storage target → NVMe media. This chain changes based on volume mode, mount options, and whether the data plane runs locally or over the network.
The most common IO path bottlenecks in real clusters come from:
Application-level sync behavior and write amplification, noisy-neighbor contention on shared nodes, storage backend saturation, and network jitter between workers and storage targets. When a platform hides those signals, teams chase symptoms instead of fixing the path. When a platform exposes them, teams can set clear SLOs for throughput, latency percentiles, and recovery time.
If you want a Kubernetes-native storage baseline, the CSI model matters because it standardizes how Kubernetes talks to storage providers, and it separates control-plane actions from the fast data path.
Storage IO Path in Kubernetes and NVMe/TCP
NVMe/TCP keeps the NVMe command model while using standard Ethernet and TCP/IP. That gives teams a practical NVMe-oF transport without requiring an RDMA-only network in every environment. It also fits well with Kubernetes because it scales across node pools, supports flexible placement, and works with common operational tooling.
NVMe/TCP often outperforms legacy iSCSI paths in both latency and CPU efficiency because NVMe semantics reduce protocol overhead. When teams combine NVMe/TCP with an SPDK-based target, they can tighten the hot path further by reducing copies and minimizing kernel time.
Measuring and Benchmarking Storage IO Path in Kubernetes Performance
Benchmarking works only when it matches how the workload issues IO. fio remains the standard tool for block storage testing because it can model random and sequential access, mixed read/write ratios, sync behavior, and queue depth. Use it to measure p50, p95, p99, and p999 latency, not just averages, because executives feel tail latency through customer experience and SLA penalties.
Run tests at three levels:
Test inside a Pod on a PVC, test directly on the node against the mapped device, and test the backend storage nodes. This split shows where the IO path shifts from application limits to CSI overhead, network issues, or media saturation.
Approaches for Improving Storage IO Path in Kubernetes Performance
Use controlled changes and retest after each one. Start with the hot path signals, then lock in platform defaults that keep performance stable during scaling and upgrades.
- Pin IO-heavy workloads to stable CPU resources and avoid cross-NUMA placement when possible, because scheduler churn can increase jitter.
- Use raw block volumes for latency-sensitive databases that do not need filesystem features, because filesystems can add overhead and write amplification.
- Enforce per-tenant QoS so one namespace cannot starve another, especially in shared Kubernetes Storage clusters.
- Keep the storage and application topology explicit with zone and node constraints so reschedules do not add hidden network hops.
- Tune the network path for NVMe/TCP with consistent MTU, IRQ steering, and CPU affinity, then re-check p99 latency under peak load.
- Instrument queues, retries, and saturation signals end-to-end so teams can see where the IO path bends under pressure.
IO Path Options Compared – Latency, Complexity, and Operational Fit
The table below compares common Kubernetes storage approaches based on how they shape the IO path. It helps platform owners map performance goals to operational cost and risk.
| Approach | IO Path Shape | Operational Complexity | Typical Fit |
|---|---|---|---|
| Legacy SAN / iSCSI style | Longer protocol stack, higher CPU per IO | Medium to High | Lift-and-shift, conservative change windows |
| NVMe/TCP over Ethernet | Shorter NVMe semantics over standard networks | Medium | Most Kubernetes Storage platforms |
| NVMe/RDMA (RoCE/InfiniBand) | Lowest latency, lowest CPU per IO | High | Ultra-low-latency tiers, specialized fabrics |
| SPDK-based user-space target | Fewer context switches, tighter queueing | Medium | High IOPS, multi-tenant Software-defined Block Storage |
Predictable Latency and QoS with Simplyblock™ for Multi-Tenant Clusters
Simplyblock™ focuses on predictable IO behavior by combining an SPDK-based, user-space data path with Kubernetes-native lifecycle management. That design targets lower CPU cost per IO and tighter latency under concurrency, which helps stateful services keep steady p99 latency during reschedules, rollouts, and mixed-tenant load.
Simplyblock also supports NVMe/TCP and flexible Kubernetes deployment models, including hyper-converged, disaggregated, and mixed layouts. That flexibility helps platform teams align fault domains with cost targets while still maintaining consistent performance.
What’s Next – DPU Acceleration, IO-Aware Scheduling, and NVMe-oF Evolution
Kubernetes Storage roadmaps keep moving toward better topology awareness, clearer volume health signals, and stronger scheduling hints that account for storage locality.
On the infrastructure side, DPUs and IPUs will take more data plane work off the host CPU, which can improve efficiency and reduce jitter for shared clusters. NVMe-oF continues to expand across transports, and teams will pick the right fabric per tier, instead of forcing one transport everywhere.
Related Terms
These pages support troubleshooting along the Storage IO Path in Kubernetes.
Questions and Answers
The storage I/O path in Kubernetes flows from the containerized application through the kubelet and CSI driver to the backend storage system. With platforms like Simplyblock, this path leverages NVMe over TCP for direct, high-throughput access to persistent volumes.
The CSI driver handles control-plane tasks like provisioning and attachment, but it does not sit in the I/O path. I/O is sent directly from the pod to the storage backend, which allows high-performance setups—especially in Kubernetes stateful workloads—to avoid unnecessary bottlenecks.
Yes. Optimizations include using fast protocols like NVMe/TCP, reducing filesystem overhead, and tuning volume parameters. Simplyblock enables such low-latency I/O paths by combining CSI-based orchestration with a high-performance scale-out architecture.
Block storage (via CSI) provides raw volumes directly attached to pods, offering higher performance and better control for databases and latency-sensitive workloads. File storage routes I/O through networked filesystems, which adds complexity and latency. Simplyblock supports fast, persistent block storage ideal for high IOPS use cases.
Tools like iostat, blktrace, and perf can profile latency and IOPS across the full I/O path. For CSI-specific environments, metrics can also be collected from the CSI driver and kubelet to debug provisioning or mount issues in production.