Kubernetes Storage Architecture for Databases
Terms related to simplyblock
Kubernetes Storage Architecture for Databases describes how Kubernetes, the CSI layer, the network, and the storage backend work together to serve database I/O. A good design keeps write latency steady, delivers high IOPS, and avoids noisy-neighbor effects. A weak design creates stalls during fsync, causes replication lag, and pushes p99 latency outside your SLO.
Databases stress storage in ways most stateless apps do not. They issue many small, random reads and writes. They depend on durable commits. They also amplify tail latency because one slow I/O can block a transaction, a checkpoint, or a compaction step. Kubernetes adds more moving parts, so you need a clear model for data placement, failover, and performance isolation.
Kubernetes Storage works best for databases when the data path stays short, the transport stays efficient, and the platform enforces boundaries. Software-defined Block Storage and NVMe semantics help because they match how SSDs work under parallel load.
Design goals that keep database I/O stable in Kubernetes
Start with outcomes, not features. A database platform needs clear targets for p95 and p99 latency, sustained IOPS, and recovery time. Your architecture should also keep performance steady during node drains, reschedules, and rolling upgrades.
Topology plays a major role. Hyper-converged layouts keep storage close to compute, which reduces hops. Disaggregated layouts scale compute and storage on their own, which improves fleet planning. Many teams run both, so the storage layer must support mixed placement without making operations harder.
Isolation matters as much as speed. One busy tenant can drain shared queues and crush others if the platform lacks QoS. Strong multi-tenancy controls keep database classes from stepping on each other.
🚀 Fix Kubernetes Storage Architecture for Databases with NVMe/TCP, Natively in Kubernetes
Use Simplyblock to reduce database tail latency, enforce QoS, and keep storage SLOs steady at scale.
👉 Use Simplyblock to Remove Database Storage Bottlenecks →
Kubernetes Storage Architecture for Databases inside Kubernetes Storage
In Kubernetes Storage, the database I/O path runs through the kubelet, the CSI driver, and the volume backend. Each layer can add delay. Your goal is to keep that delay predictable.
Most database issues come from queueing. When several pods hit the same backend, latency rises fast. Journaling and sync writes also surface problems. A slow commit forces the database to wait, and that wait often shows up as app timeouts.
Scheduling can help or hurt. If Kubernetes places a database pod far from its data, the network adds jitter. If the platform lacks storage-aware placement rules, you can end up with hot volumes sharing a thin path. Good architectures add placement controls, so Kubernetes aligns pods, volumes, and failure domains.
Why NVMe/TCP fits database-heavy clusters
NVMe/TCP carries NVMe commands over standard Ethernet. It fits Kubernetes well because it scales across nodes and works in common networks. It also keeps the storage stack closer to NVMe behavior, which helps with deep queues and parallel I/O.
For database tiers, NVMe/TCP often hits a better balance than older protocols. It can deliver strong throughput without special fabrics. It also supports disaggregation without forcing a SAN mindset.
Some teams use NVMe/RDMA for the tightest latency targets. Others standardize on NVMe/TCP to keep ops simple. Either way, NVMe semantics help reduce overhead and keep I/O behavior easier to predict under load.
How to measure Kubernetes Storage Architecture for Databases under real load
Measure what the database feels. Track p50, p95, and p99 latency for reads and writes. Monitor fsync time, checkpoint duration, and replication lag. Tie those metrics to throughput and CPU use, so you see tradeoffs.
Benchmark with realistic settings. Match block size, read/write mix, and queue depth to your database profile. Run tests through Kubernetes, not around it. A direct node benchmark can hide CSI overhead, network jitter, and contention.
Test failure events on purpose. Drain a node. Move pods. Restart the storage side. Your architecture should keep latency within a known band during change, not only during steady state.
Practical changes that improve database storage outcomes
Use a simple rule: fix the biggest limiter first. Most platforms see gains from tightening the data path, tuning concurrency, and enforcing QoS. Make one change at a time, then re-test.
- Choose a storage class that matches the database tier, and separate noisy workloads from critical ones
- Set clear limits for IOPS and bandwidth so background jobs do not starve commits
- Keep the data path efficient by reducing extra copies and avoiding heavy kernel work in hot I/O paths
- Align pod placement with storage placement to reduce network hops and jitter
- Validate queue depth and parallel threads against the backend’s real limits
These steps reduce cost because they improve performance per node. They also make capacity planning easier because latency stays stable as load grows.
Storage architecture patterns compared for database workloads
The comparison below focuses on what usually breaks databases first: tail latency, CPU overhead, and behavior under contention.
| Architecture pattern | Strength | Typical risk for databases | When it fits best |
|---|---|---|---|
| Local SSD only (node-bound) | Very low latency | Hard failover, limited mobility, tougher ops | Small clusters, dev, edge tiers |
| Network SAN / iSCSI style | Familiar model | Higher latency variance, CPU overhead | General enterprise apps |
| NVMe/TCP Software-defined Block Storage | Strong IOPS, steady p99 potential, flexible placement | Needs solid network design and clear tiers | OLTP, streaming, analytics, multi-tenant DB platforms |
Storage SLOs at Scale with Simplyblock™
Simplyblock™ targets database-grade Kubernetes Storage by keeping the data path efficient and enforcing isolation. It uses an SPDK-based, user-space, zero-copy architecture to reduce CPU overhead in the hot I/O path. That design helps databases sustain high concurrency without burning cores that should run queries.
Simplyblock also supports flexible deployment models. Teams run hyper-converged for hot tiers, disaggregated for scale, or mixed for shared clusters. Multi-tenancy and QoS controls help protect one database tenant from another, which keeps SLOs realistic and easier to enforce.
This approach fits platforms that run many stateful services in one fleet. It also fits teams that want NVMe/TCP performance without building a SAN-like stack.
What changes next in database-focused Kubernetes storage
Hardware offload will keep growing. DPUs and IPUs can take on parts of storage and networking work, which reduces host CPU pressure and smooths tail latency. User-space I/O will also expand because it can cut overhead under heavy IOPS.
Expect stronger policy control inside Kubernetes. Teams want storage behavior that follows intent: latency targets, tenant limits, and durability rules. Storage platforms will move toward automated tiering and smarter placement so databases keep fast paths even as clusters scale.
NVMe/TCP will likely remain a core option because it runs well on standard Ethernet and scales across environments. Faster fabrics and better offload will improve it further.
Related Terms
Use these pages to tighten database storage design in Kubernetes and keep p99 latency under control.
- Persistent Storage for Databases
- Write Amplification
- CSI NodePublishVolume Lifecycle
- Kubernetes StatefulSet VolumeClaimTemplates
Questions and Answers
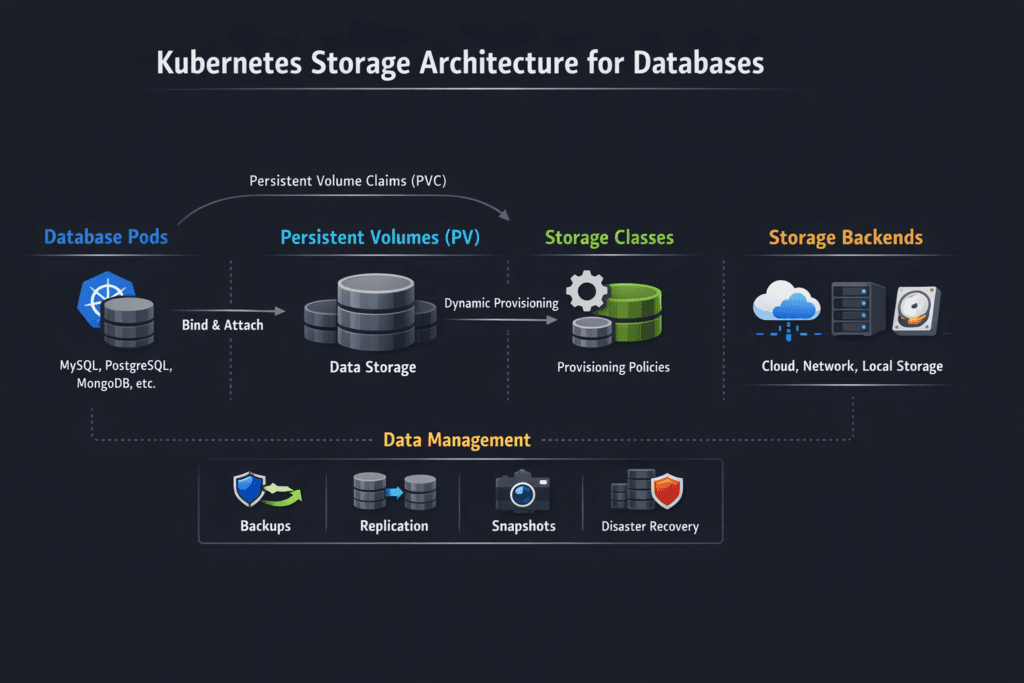
Databases on Kubernetes require storage that supports low latency, high IOPS, and data durability. A distributed block storage backend with NVMe over TCP enables reliable, high-performance storage provisioning for stateful sets and persistent volumes.
Kubernetes uses PersistentVolumeClaims (PVCs) and StorageClasses to provision persistent volumes through CSI. Simplyblock’s CSI-integrated storage architecture supports stateful database workloads with encryption, replication, and scale-out performance.
Databases demand consistent latency and durability, which can be impacted by shared storage or network congestion. Platforms like Simplyblock address this with per-volume isolation and performance tuning within their multi-tenant Kubernetes architecture.
Yes, NVMe offers microsecond-level latency and high parallel I/O, ideal for databases. When delivered over TCP, it enables scalable, distributed storage for Kubernetes without special hardware, as used in Simplyblock’s block storage platform.
Simplyblock provides fast, CSI-provisioned NVMe over TCP volumes with encryption, replication, and snapshots. This enables high-performance, resilient storage for PostgreSQL, MySQL, and NoSQL workloads running inside Kubernetes clusters.