Kubernetes Storage for PostgreSQL
Terms related to simplyblock
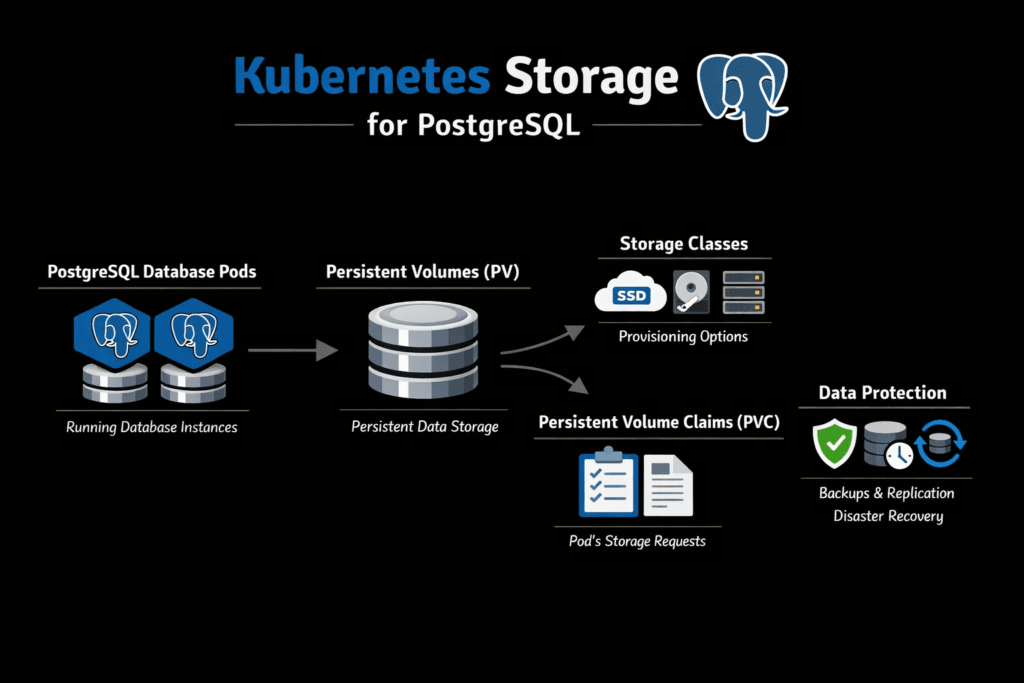
Kubernetes Storage for PostgreSQL is the persistent block layer that keeps PostgreSQL durable and fast when it runs as a StatefulSet. PostgreSQL stresses storage in ways that quickly expose weak latency control. Commits depend on WAL fsync behavior, and user experience often follows p99 latency rather than average throughput. When storage jitter rises, commit time climbs, replicas drift behind, and recovery tasks take longer than planned.
In Kubernetes, persistence is expressed through PVCs and StorageClasses, but the storage engine behind them decides how consistent the I/O path is under load. Teams that run Postgres as a shared platform need isolation, predictable queueing, and fast rebuild behavior to meet SLOs, especially on baremetal clusters where performance expectations are higher.
Modern Tactics for Database-Grade Persistence
Database-grade persistence starts with stable latency, tenant isolation, and a clear failure-domain model. Peak IOPS helps less than controlled tail latency for OLTP. A storage stack can look strong in average numbers and still fail operationally if p99 spikes line up with checkpoints, vacuum activity, or backup windows.
Software-defined Block Storage is often chosen as a SAN alternative because it can enforce policies and QoS without bringing the operational weight of legacy arrays. In Kubernetes Storage designs, a strong control plane should map intent into real limits on bandwidth and IOPS so one workload cannot starve PostgreSQL.
🚀 Remove Storage Bottlenecks from Postgres on Kubernetes
Use Simplyblock to simplify persistent volumes and enforce database-ready QoS.
👉 Use Simplyblock Persistent Storage for Kubernetes →
Kubernetes Storage for PostgreSQL in Stateful Kubernetes Architectures
Kubernetes Storage for PostgreSQL typically maps to a StatefulSet with one PVC per replica and scheduling rules that spread replicas across nodes and zones. WAL behavior is a key driver for many OLTP systems. Every commit pushes writes through the WAL path and then forces durability. If the storage layer cannot deliver consistent write latency, even small spikes can slow applications.
Some teams place WAL and the data directory on separate volumes to reduce contention. That choice can stabilize commit time, but it increases object count and demands cleaner automation for provisioning, expansion, and replacement. Whether you split volumes or not, the storage platform must protect PostgreSQL from noisy neighbors, and it must keep rebuild impact contained during node loss events.
Kubernetes Storage for PostgreSQL and NVMe/TCP Data Paths
Kubernetes Storage for PostgreSQL and NVMe/TCP fit well when you want NVMe-oF semantics over standard Ethernet without requiring an RDMA fabric. NVMe/TCP can scale parallelism and queue depth across Kubernetes fleets, but results depend on CPU efficiency and the amount of copying and context switching in the data path.
Simplyblock is SPDK-based, using a user-space, zero-copy architecture to reduce overhead and improve CPU efficiency. That matters for PostgreSQL because database nodes run query execution, background maintenance, and replication alongside storage client work. With an efficient NVMe/TCP path, the system can keep tail latency tighter under concurrency, which is exactly what Postgres needs to hold commit time steady.
Testing and Benchmarking Kubernetes Storage for PostgreSQL at p99 Latency
Benchmarks should measure latency distributions and repeatability. Track p50, p95, and p99 for read and write workloads, and correlate those values with database signals such as commit time, checkpoint duration, WAL write time, and replication lag. Use the same PVC and StorageClass you intend to ship, and keep node placement and CPU limits consistent so results do not shift between runs.
Synthetic tools help isolate raw block behavior and saturation points. Database-aware benchmarks confirm real transactional impact, including how checkpoints and WAL pressure interact with storage. A platform that maintains a tight p99 under load usually delivers better business outcomes than a platform that advertises higher peak throughput but suffers periodic stalls.
Practical Ways to Raise PostgreSQL Throughput and Reduce Commit Latency
Apply a small set of changes, measure each one, and keep the workflow consistent across environments.
- Choose a StorageClass that targets low tail latency and includes clear performance isolation.
- Separate WAL from data volumes when commit time is the primary constraint, and keep WAL on the lowest-latency path.
- Enforce QoS so noisy neighbors cannot drain the IOPS and bandwidth needed by StatefulSets.
- Reserve CPU headroom because PostgreSQL and the storage client both need cycles during spikes and rebuilds.
- Prefer NVMe/TCP-backed Software-defined Block Storage when you need a scalable SAN alternative for Kubernetes.
Storage Options Compared for Postgres on Kubernetes
The table below summarizes typical tradeoffs that matter for PostgreSQL commit latency, isolation, and day-two operations.
| Option | Commit-latency stability | Isolation | Operational fit |
|---|---|---|---|
| Local volumes on each node | High until node events | Medium | Fast, but mobility and recovery workflows get harder |
| Network-attached block volumes | Medium, varies by tier | Medium | Simple, but jitter and throughput caps can appear |
| Traditional SAN presented to Kubernetes | Medium to high | High | Stable, but adds integration overhead and cost |
| Software-defined Block Storage with NVMe/TCP | High with QoS | High | Strong fit for StatefulSets and scale-out growth |
Consistent Database QoS with Simplyblock™ Software-defined Block Storage
Simplyblock™ provides Software-defined Block Storage for Kubernetes Storage deployments that need consistent database behavior. It supports NVMe/TCP and flexible placement models, including hyper-converged, disaggregated, and mixed clusters. That flexibility lets platform teams align topology to cost, fault domains, and operational boundaries without re-platforming PostgreSQL.
SPDK-based efficiency reduces CPU overhead in the storage path, which helps preserve CPU for queries and background work. Multi-tenancy and QoS controls help keep PostgreSQL replicas from interfering with each other, which supports steadier commits, lower p99 latency, and fewer side effects during snapshots and rebuild activity.
What Changes Next for Cloud-Native PostgreSQL Persistence
Cloud-native PostgreSQL keeps pushing storage toward stronger isolation, faster recovery, and policy-driven automation through CSI. NVMe/TCP adoption will continue in Ethernet-first data centers where teams want NVMe-oF benefits without specialized fabrics. DPUs and IPUs will also increase in importance as data-plane work moves off host CPUs to preserve cycles for database processing.
Storage platforms that control tail latency, enforce QoS, and support flexible Kubernetes Storage topologies will remain the foundation for reliable PostgreSQL fleets.
Related Terms
Teams running Kubernetes Storage for PostgreSQL often reference these terms for NVMe/TCP and QoS alignment:
- SPDK (Storage Performance Development Kit)
- NVMe over TCP (NVMe/TCP)
- NVMe/RDMA
- Asynchronous Storage Replication
Questions and Answers
PostgreSQL requires low-latency, high-IOPS block storage for WAL and data files. A distributed NVMe-backed solution like Simplyblock’s Kubernetes storage platform ensures persistent, high-performance volumes with dynamic provisioning and replication.
High storage latency increases commit times and replication lag in PostgreSQL. Using NVMe over TCP helps maintain sub-millisecond latency, improving transaction throughput and overall database responsiveness.
PostgreSQL performs best on raw block storage due to predictable I/O and lower overhead. Simplyblock provides optimized block volumes tailored for stateful Kubernetes workloads, ensuring reliable WAL writes and indexing operations.
High availability requires synchronous replication, persistent volumes, and fast failover. Simplyblock supports distributed, replicated volumes within its scale-out storage architecture, minimizing downtime during node or pod failures.
Simplyblock delivers encrypted, NVMe-based persistent volumes with performance isolation and dynamic scaling. Its software-defined storage architecture ensures consistent IOPS and low latency for production PostgreSQL clusters in Kubernetes.