Kubernetes Storage for MySQL
Terms related to simplyblock
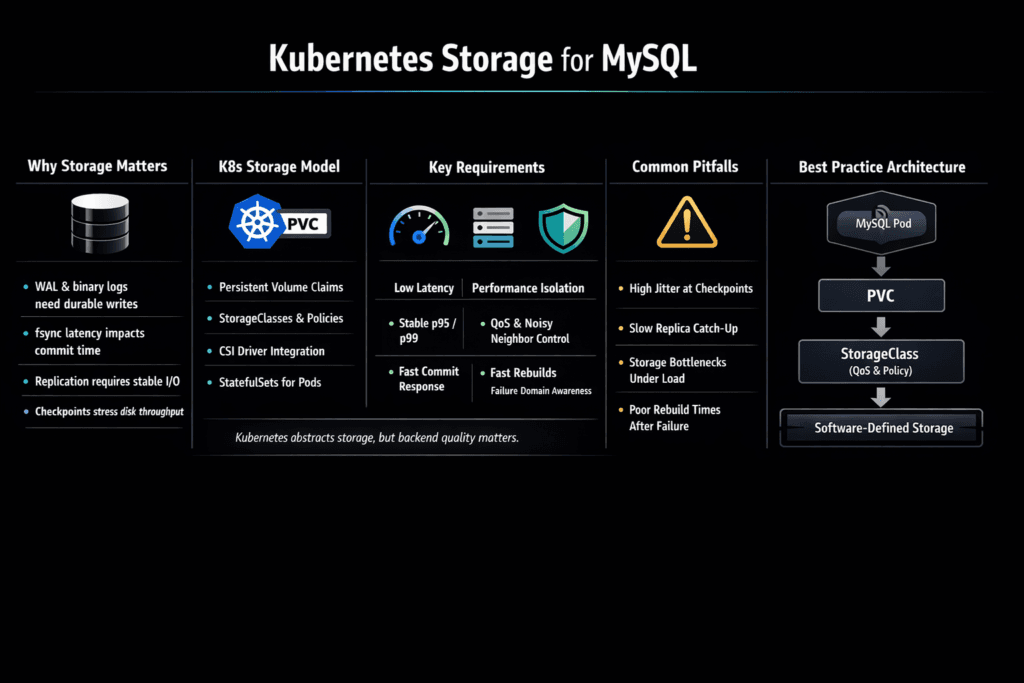
Kubernetes Storage for MySQL covers the storage patterns, volume types, and data-path choices that keep MySQL durable and fast when it runs as a StatefulSet with PersistentVolumes. MySQL stresses storage with small-block random writes, frequent fsync calls, redo log flushes, and background page writes. That mix makes latency stability more important than peak throughput, because jitter at the storage layer becomes query stalls, replica lag, and longer crash recovery.
Executives usually care about risk and cost. Platform teams care about repeatable operations. Both groups end up at the same requirement: steady p95 and p99 latency, clear failure isolation, and Kubernetes-native provisioning that does not turn into a one-off platform.
Designing MySQL Persistence Around Today’s Infrastructure
MySQL I/O is not “just disk.” InnoDB log writes, doublewrite behavior, checkpoint pacing, and buffer pool pressure create bursts that expose weak storage paths. When the stack adds extra copies, context switches, or shared choke points, tail latency rises under concurrency.
A strong design keeps the data path short, limits contention, and fits the cluster’s failure domains. Software-defined Block Storage helps when it enforces per-tenant controls, supports clean automation, and avoids heavyweight storage gateways that turn CPU into a bottleneck.
🚀 Run MySQL on NVMe Storage, Natively in Kubernetes
Use Simplyblock to simplify persistent storage and eliminate performance bottlenecks at scale.
👉 Use Simplyblock for MySQL on Kubernetes →
Stateful MySQL on Kubernetes – Volume Semantics That Matter
StatefulSets provide stable identities, and they also guide how volumes attach during reschedules. The storage layer must handle node drains, upgrades, and failovers without volume chaos or long reattach times. Volume expansion and snapshot behavior matter, too, because most teams scale databases while they stay online.
Two decisions shape most outcomes. Choose an access model that avoids hidden contention across replicas. Align placement rules with failure domains so a node loss does not trigger cross-zone I/O spikes or rebuild storms.
Kubernetes Storage works best for databases when it stays topology-aware, keeps hot paths local when needed, and uses controls that prevent one namespace from consuming the entire I/O budget.
Kubernetes Storage for MySQL and NVMe/TCP
NVMe/TCP carries NVMe commands over standard Ethernet, which makes it practical for cloud-native environments that want to scale without specialized fabrics everywhere. For MySQL, the real benefit shows up as better parallel I/O handling and less sensitivity to CPU overhead across the storage path.
NVMe/TCP also supports disaggregated layouts where compute and storage scale independently. That model helps when you need to raise capacity and IOPS without resizing database nodes. It also supports hybrid designs, where latency-sensitive replicas stay close to compute while capacity growth stays decoupled.
Measuring and Benchmarking Kubernetes Storage for MySQL Performance
Benchmarking needs two lenses: storage-centric tests and database-centric tests. Storage tests isolate device and network behavior. Database tests confirm what the application feels.
Start with a repeatable I/O profile that matches OLTP behavior, such as 4K random reads and writes with a mixed ratio. Track p50, p95, and p99 latency, plus sustained IOPS and throughput. Then run a MySQL workload that mirrors production and capture query latency percentiles, redo log flush time, checkpoint activity, buffer pool hit rate, and replica lag.
Also measure during operational events. Rolling upgrades, reschedules, snapshot creation, and rebuilds often cause the worst spikes. If the platform stays stable during churn, it will usually stay stable during normal traffic.
Practical Tactics That Reduce Tail Latency for MySQL
Most MySQL “storage performance” problems in Kubernetes come from variance, not raw speed. Reduce variance, and throughput often improves as a side effect. Keep the platform simple, and failures become safer to handle.
- Enforce per-tenant QoS so one workload cannot flood IOPS and raise tail latency across the cluster.
- Prefer topologies that minimize hops for latency-critical replicas, and reserve full disaggregation for scaling and isolation needs.
- Use a data path that avoids extra copies and excess context switching to reduce CPU pressure under high concurrency.
- Protect redo log performance under write spikes, because log stalls throttle the commit rate.
- Validate changes with percentile targets, not averages, and repeat tests under churn.
Storage Options for MySQL on Kubernetes – Operational and Performance Trade-Offs
A quick comparison helps clarify which option fits steady MySQL latency, scaling needs, and day-two operations in Kubernetes. The right choice depends on how much performance headroom you need, how shared your clusters are, and how often you expect maintenance events.
| Option | Fit for MySQL on Kubernetes | Latency stability | Scaling model | Operational impact |
|---|---|---|---|---|
| Legacy SAN-style block storage | Traditional data center patterns | Can vary under contention | Centralized scale-up | Higher integration overhead |
| Cloud-managed block volumes | Fast onboarding, managed defaults | Depends on tier and limits | Per-volume scaling | Simple start, costs rise with performance |
| NVMe/TCP Software-defined Block Storage | Multi-tenant, performance-critical MySQL | Built for low jitter | Scale-out | Kubernetes-native workflows with policy control |
Kubernetes Storage for MySQL with Simplyblock™
Simplyblock™ targets consistent database outcomes by combining Kubernetes-native provisioning, NVMe/TCP networking, and an SPDK-based user-space data path that avoids extra kernel overhead and reduces CPU waste. That matters when concurrency climbs, and MySQL pushes frequent log flushes alongside background writes.
Platform teams typically standardize on simplyblock when they need a SAN alternative that behaves like enterprise block storage while still matching cloud-native operations. Multi-tenancy and QoS controls help protect shared clusters from noisy neighbors. Flexible deployment modes support hyper-converged, disaggregated, and mixed layouts, so teams can match topology to each database tier.
This approach supports Kubernetes Storage goals that executives care about, such as lower platform risk, fewer performance escalations, and predictable cost scaling as more database teams join the cluster.
What’s Next for MySQL Persistence in Kubernetes Environments
Kubernetes database storage is moving toward tighter topology awareness, stronger isolation controls, and more efficient I/O paths. Policy-driven placement and fast rebuild behavior will become more common as platforms work to protect tail latency during failures and maintenance windows.
Broader NVMe-oF adoption is also likely, with NVMe/TCP acting as the baseline in Ethernet-first environments. Offload-friendly designs will increasingly move parts of the storage data path onto DPUs or IPUs, giving CPU cycles back to MySQL and limiting performance cliffs during traffic spikes.
As these trends mature, teams will judge storage less by peak numbers and more by how well it holds p99 latency steady during real operations.
Related Terms
These terms support Kubernetes Storage, NVMe/TCP, and Software-defined Block Storage decisions for MySQL at scale.
Questions and Answers
MySQL requires low-latency, high-IOPS block storage to handle transactions, indexing, and buffer pool flushing efficiently. Simplyblock’s Kubernetes-native NVMe storage delivers persistent volumes optimized for database workloads running in StatefulSets.
High storage latency increases commit time and slows down InnoDB writes, especially for transactional workloads. Using NVMe over TCP reduces I/O wait time and improves query throughput in production MySQL clusters.
Block storage is recommended for MySQL because it offers predictable I/O performance and lower overhead. Simplyblock provides high-performance volumes tailored for stateful Kubernetes workloads, ensuring consistent database responsiveness.
High availability requires replicated volumes, fast failover, and durable persistent storage. Simplyblock supports distributed replication within its distributed block storage architecture, reducing downtime during pod or node failures.
Simplyblock combines NVMe performance with software-defined flexibility to deliver encrypted, scalable persistent volumes. Its software-defined storage platform enables dynamic provisioning and performance isolation for demanding MySQL environments.