Storage Data Plane
Terms related to simplyblock
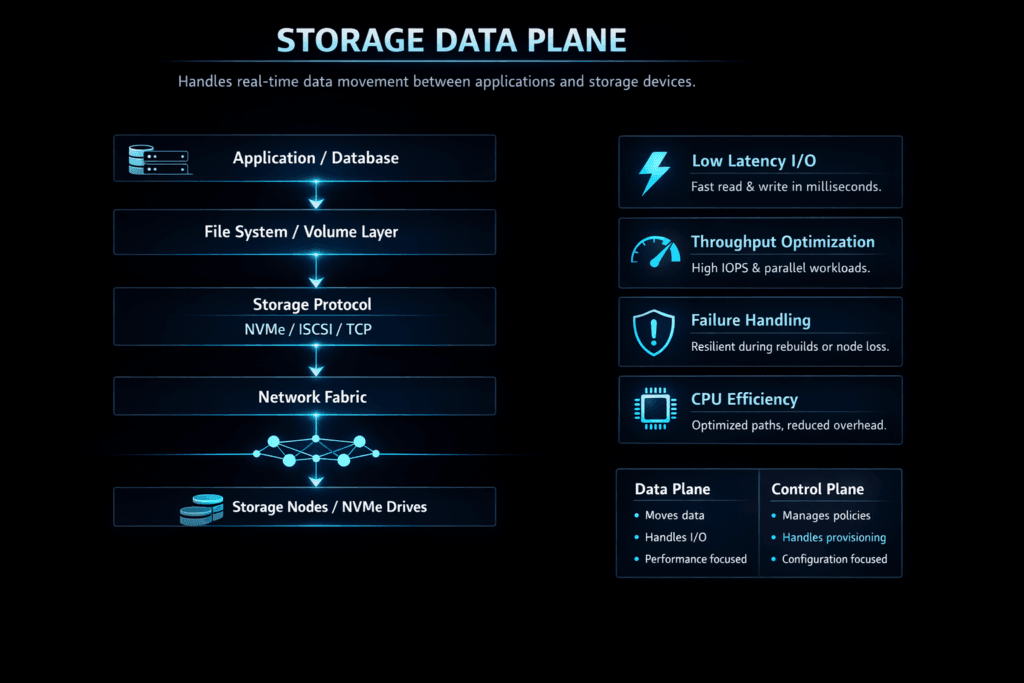
A Storage Data Plane is the part of a storage system that moves I/O. It takes reads and writes from applications, pushes them to media, and returns results with as little delay and jitter as possible. The data plane sits on the hot path, so every extra copy, context switch, or lock shows up as higher latency and lower throughput.
Most platforms split responsibilities between a control plane and a data plane. The control plane decides what should happen, like volume creation, placement, snapshots, and policy. The Storage Data Plane does the work that applications feel, including queueing, protocol handling, caching, and background tasks that run beside foreground I/O.
For executives, this component sets the ceiling for performance and the floor for consistency. For operations teams, it drives CPU use, tail latency, and failure behavior under load.
Optimizing the Storage Data Plane with modern architectures
A fast data plane keeps the hot path short. It avoids extra memory copies, reduces kernel crossings, and limits shared locks that cause stalls at scale. It also treats CPU as a first-class resource, because software storage often burns cycles in protocol work, checksum work, and copy work.
Modern Software-defined Block Storage platforms improve this path by using NVMe media effectively and by moving more I/O handling into the user space. SPDK-style design patterns help here because they reduce overhead and keep throughput stable as concurrency rises. This approach also fits baremetal deployments where you want maximum IOPS per core, and it fits cloud nodes where CPU is a direct cost line.
🚀 Run Software-defined Block Storage with a Lean Data Plane
Use Simplyblock to deploy NVMe/TCP storage across hyper-converged or disaggregated clusters.
👉 See Simplyblock Architecture →
Storage Data Plane in Kubernetes Storage environments
Kubernetes Storage adds constant motion. Pods reschedule, nodes drain, and autoscaling change the topology. The data plane must keep I/O stable through these changes while the control plane updates attachments and routing.
A strong Storage Data Plane also supports both hyper-converged and disaggregated layouts. Hyper-converged placement keeps I/O close to the workload and cuts network hops. Disaggregated placement isolates storage nodes, simplifies upgrades, and scales storage without adding compute. Many teams mix both, then map storage classes to the right path for each workload tier.
When the data plane stays lean, Kubernetes operations get easier. Volume attach happens faster, recovery takes fewer steps, and multi-tenant clusters avoid one namespace breaking everyone else.
Storage Data Plane and NVMe/TCP on Ethernet fabrics
NVMe/TCP matters because it brings NVMe-oF benefits to standard Ethernet. A Storage Data Plane that handles NVMe/TCP well can scale out block storage without a classic SAN, and it can do it with tooling that teams already know.
The key is how the data plane deals with network reality. Retries, congestion, and path changes happen in production. A solid implementation keeps queueing under control, uses multiple paths when available, and maintains low jitter during peak hours. It also avoids excessive CPU burn in protocol handling, because CPU spikes often turn into latency spikes.
This is where a user-space, low-overhead design helps. It frees CPU for the application tier and keeps the storage tier steady as load ramps.
Measuring and benchmarking Storage Data Plane behavior
Benchmarking should show more than peak numbers. Measure latency percentiles, throughput, and CPU per I/O, then repeat the test under a realistic mix and concurrency. Include tail metrics, because p99 and p999 are where timeouts and retries start.
Use the same test plan across designs, so comparisons stay fair. Keep block size, queue depth, job count, and read/write mix consistent. Then add failure-adjacent stress, such as background rebuild, rebalancing, or a node reboot, while the workload runs. A Storage Data Plane that stays smooth during stress reduces incident tickets, even if its headline IOPS looks similar to alternatives.
Approaches for improving Storage Data Plane efficiency
- Cut overhead on the hot path by reducing memory copies and avoiding extra hops between user space and the kernel.
- Reserve CPU cores for protocol and target work so noisy neighbors do not steal cycles from the I/O path.
- Enforce QoS per tenant or workload class so one namespace cannot drain shared bandwidth or IOPS.
- Separate failure domains in placement so background repair work does not overload a single node or rack.
- Validate networking under load, including retransmits, congestion, and multipath behavior for NVMe/TCP.
Side-by-side comparison of Storage Data Plane designs
The table below compares common Storage Data Plane approaches that teams evaluate when they plan for scale, cost, and operations.
| Data Plane Approach | Typical strength | Typical trade-off |
|---|---|---|
| Kernel-centric I/O path | Familiar ops model | Higher overhead at high IOPS |
| User-space SPDK-style path | Lower CPU per I/O, steadier latency | Needs careful CPU pinning and tuning |
| Hyper-converged placement | Low hop count to media | Shares failure and resource domains with apps |
| Disaggregated placement | Clear separation of roles | Relies more on the network and path design |
Storage Data Plane outcomes with Simplyblock™ architecture
Simplyblock™ provides Software-defined Block Storage built for Kubernetes Storage and NVMe/TCP. It focuses on an efficient data path so the cluster keeps stable behavior at high concurrency. It also supports hyper-converged, disaggregated, and hybrid deployments, which lets teams place the data plane where it best fits their risk and cost model.
Simplyblock adds multi-tenancy controls and QoS to keep critical services steady when other workloads spike. That matters in shared clusters where background tasks and tenant bursts can collide with database write paths. The platform also aligns with NVMe-oF growth, including support for NVMe/RoCEv2 in environments that want RDMA tiers alongside NVMe/TCP.
Future directions and advancements in storage hot paths
Storage data planes are trending toward policy-driven designs that tie performance, placement, and transport into a single intent model. That helps platform teams offer self-service storage without letting teams create risky layouts.
Offload is another major direction. DPUs and IPUs can take on protocol and networking work, which isolates storage performance from application CPU spikes. Expect more designs that place the data plane closer to the NIC, keep the host CPU focused on apps, and improve stability at high load. Teams will also keep tightening observability, because the fastest path still needs clear metrics for latency, queue depth, and CPU use.
Related Terms
These pages help when you compare Storage Data Plane designs for throughput, latency, and failure behavior.
- CSI Control Plane vs Data Plane
- IO Path Optimization
- Storage Offload on DPUs
- Storage Virtualization on DPU
Questions and Answers
The storage data plane is responsible for handling actual read and write I/O between applications and storage nodes. It operates independently from the control plane to ensure low-latency, high-throughput access within a distributed block storage architecture.
The data plane directly determines latency, IOPS, and throughput. Optimized implementations use multi-queue I/O paths and efficient networking to minimize overhead. Simplyblock leverages NVMe over TCP to deliver high-performance data-plane operations over standard Ethernet.
The control plane manages provisioning and orchestration, while the data plane processes I/O traffic. This separation prevents management tasks from interfering with performance. Simplyblock applies this model within its software-defined storage platform to ensure predictable workload behavior.
In Kubernetes, once a volume is mounted, all application I/O flows through the data plane. A highly optimized data path ensures reliable performance for stateful Kubernetes workloads such as databases and analytics engines.
Simplyblock uses a distributed NVMe-based backend with direct I/O paths and network-efficient transport. Its Kubernetes-native storage integration ensures that data-plane operations remain fast and isolated, even under multi-tenant or high-concurrency workloads.