Storage-Aware Scheduling
Terms related to simplyblock
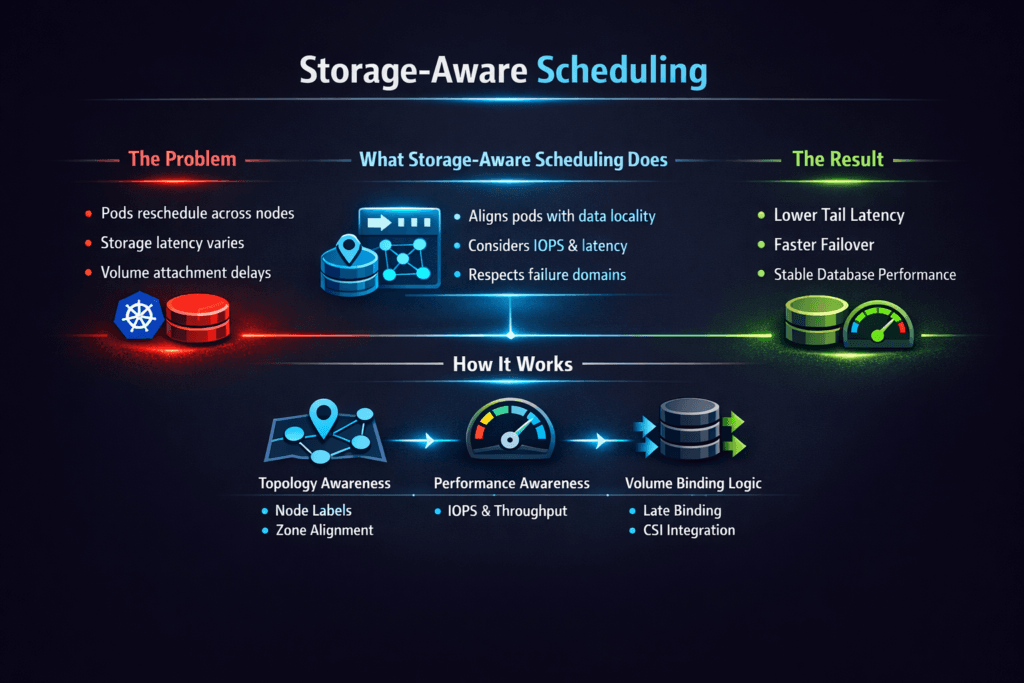
Storage-aware scheduling means the platform places a workload where it can reach the right storage path with the least delay and the fewest failure risks. In Kubernetes Storage, that decision affects attach time, read and write latency, and how often stateful Pods restart during node churn.
Teams often treat scheduling as a CPU and memory problem. Storage changes that math. A Pod can land on a “free” node and still miss its SLO if the volume sits in another zone, shares a congested path, or competes with rebuild traffic. Storage-aware scheduling reduces that gap by aligning Pods, volumes, and failure domains. It also helps platform teams keep operations stable as clusters scale.
This topic matters more with high-performance media. NVMe and Software-defined Block Storage can deliver strong throughput, but placement mistakes can wipe out those gains. When you add NVMe/TCP, the network becomes part of the I/O path, so topology rules carry even more weight.
Smarter Placement with Policy and Topology
Modern platforms improve scheduling outcomes by combining topology signals, policy-based placement, and predictable performance isolation. Topology signals tell the scheduler where data can live. Placement policy keeps stateful Pods close to their data and inside the right fault domain. Isolation tools such as QoS prevent one workload from pushing others into tail-latency spikes.
The best results come from designs that keep the rules simple. A small number of pools, clear StorageClasses, and consistent topology labels reduce surprises. A single “special” node pool can create months of drift if teams treat it like a shortcut.
🚀 Make Storage-Aware Scheduling the Default for Stateful Apps
Use Simplyblock to keep Pods close to their volumes and cut tail-latency spikes at scale.
👉 Learn About CSI Topology Awareness →
Storage-Aware Scheduling in Kubernetes Storage
Kubernetes Storage adds steps that can hide scheduling issues until rollout day. A Pod may schedule fast, but the volume can still bind late, attach slowly, or mount on the wrong side of a topology boundary. Those delays show up as Pending Pods, slow starts, or failover loops.
Two modes drive many outcomes: immediate binding and delayed binding. Immediate binding can create a volume before Kubernetes chooses a node. Delayed binding can wait for node placement and then provision the volume in the same zone or failure domain. Teams that run multi-zone clusters usually prefer delayed binding for stateful apps.
The scheduler also needs clean signals. Node labels must match your topology plan. Storage nodes must report consistent topology keys. StorageClasses must express the right intent. When these pieces align, the platform avoids cross-zone traffic and reduces reschedules.
Storage-Aware Scheduling and NVMe/TCP Paths
NVMe/TCP brings NVMe semantics over standard Ethernet using TCP. That choice gives teams a practical way to disaggregate storage while keeping the network easy to run. It also makes placement more important because the network hop sits on every read and write.
With NVMe/TCP, a “near” path can feel like local NVMe for many workloads. A “far” path can add jitter that breaks database tail latency. Storage-aware scheduling helps by keeping Pods close to their NVMe/TCP target, keeping traffic inside the same zone, and avoiding crowded links.
This is where Software-defined Block Storage adds value. It can map storage pools to topology, enforce QoS, and keep background work from colliding with foreground I/O. The scheduler then makes choices that match real performance behavior, not guesses.
Measuring and Benchmarking Placement Outcomes
A good benchmark checks placement outcomes, not just raw IOPS. Start with time to ready for a stateful Pod, including bind, attach, and mount. Track p95 and p99 latency once the workload runs. Then repeat during node drains, rollouts, and rebuild activity.
Also, measure how often workloads cross failure domains. A single cross-zone placement can raise cost and add latency. Track recovery time after node loss and the time to return to steady p99 latency. These numbers reflect user impact and operator effort.
Approaches for Improving Storage-Aware Scheduling Performance
Teams usually improve placement by reducing variance and removing silent mismatches. Keep your policy readable, and keep your storage tiers small in number.
- Align StorageClasses to intent, and keep the number of tiers low enough that teams can choose without meetings.
- Use topology rules that keep Pods and volumes in the same zone or failure domain for stateful services.
- Add QoS limits per tenant or workload class to prevent noisy neighbors from shaping cluster “normal.”
- Control background work impact, so rebuild and snapshot traffic do not flatten foreground latency.
Scheduling Approaches Comparison Table
The table below compares common approaches teams use when they try to align Pods and storage in Kubernetes Storage environments.
| Approach | What it optimizes | Common risk | Best fit |
|---|---|---|---|
| Default scheduling with no storage policy | Fast placement | Cross-zone volumes, high tail latency | Stateless apps, dev clusters |
| Topology-aware volume binding | Fault-domain alignment | Label drift causes Pending Pods | Multi-zone stateful apps |
| Affinity rules for node and storage locality | Shortest I/O path | Over-constraining reduces scheduling flexibility | Low-latency databases |
| Policy-driven pools with QoS | Predictable multi-tenancy | Poor tier design creates confusion | Shared platforms at scale |
Storage-Aware Scheduling with simplyblock™
Simplyblock™ supports Kubernetes Storage with Software-defined Block Storage that focuses on predictable placement outcomes. It supports NVMe/TCP so teams can scale storage nodes and keep an NVMe-first I/O model on standard Ethernet. It also supports multi-tenancy and QoS, so one workload does not distort latency for the rest of the cluster.
This combination helps platform teams run fewer “special case” clusters. It also helps app teams get steady behavior during drains and rollouts. When the storage layer reports clear topology and enforces performance policy, the scheduler can make decisions that match the SLO.
Future Directions for Data-Local Scheduling
Scheduling will keep moving toward tighter coordination between the Kubernetes scheduler and the storage control plane. Expect more policy that expresses “place compute near data” and “keep data in-zone” as defaults, not exceptions. Expect more emphasis on tail latency, not only averages, because p99 drives user pain and paging.
NVMe/TCP adoption will also push better placement controls. Faster storage makes placement mistakes more visible. Teams that treat scheduling as part of the storage design will ship more stable platforms.
Related Terms
For Storage-Aware Scheduling, related pages for Kubernetes Storage and Software-defined Block Storage.
- CSI Topology Awareness
- Storage Affinity in Kubernetes
- Node Taint Toleration and Storage Scheduling
- Kubernetes Topology Constraints
Questions and Answers
WaitForFirstConsumer and zone-aware PersistentVolumes?With volumeBindingMode: WaitForFirstConsumerKubernetes delays PV binding until a Pod is scheduled, so the scheduler can pick a node whose zone/topology can actually satisfy the claim. This avoids “scheduled but can’t mount” loops when a StorageClass or CSI backend restricts volumes by zone, rack, or node. It pairs well with CSI topology and clear CSI Architecture signals.
Use node taints to keep general workloads off storage-optimized nodes, then add tolerations only to Pods that truly need low-latency or high-IOPS volumes. Storage-aware rules should still validate attach/mount feasibility, so you don’t “force” placement onto nodes that can’t serve the PVC. This pattern is especially useful when mixing different storage pools or failure domains.
Prioritize storage-side saturation and consistency metrics, not just CPU/RAM. Watch latency percentiles, queue depth, throttling, and burst-credit behavior, then steer new Pods away from hot nodes or congested paths. Feeding the scheduler with meaningful storage metrics in Kubernetes helps prevent “noisy neighbor” placement that looks fine on compute but collapses under I/O contention.
Storage-aware placement should align Pods with the topology where their volumes live (same zone/rack when required), otherwise you pay with higher latency, more jitter, and harder failure handling. Use topology labels plus storage affinity in Kubernetes and confirm it matches your CSI driver’s topology keys so scheduling decisions reflect real data locality constraints.
If the attach or mount is slow, the scheduler can appear “correct” while Pods churn in ContainerCreating due to backend limits, sidecar retries, or topology mismatch. Storage-aware scheduling should account for CSI behavior end-to-end, including controller/node responsibilities and sidecars. Tightening this feedback loop with a solid CSI driver vs sidecar understanding reduces false placements and retry storms.