Topology-Aware Storage Scheduling
Terms related to simplyblock
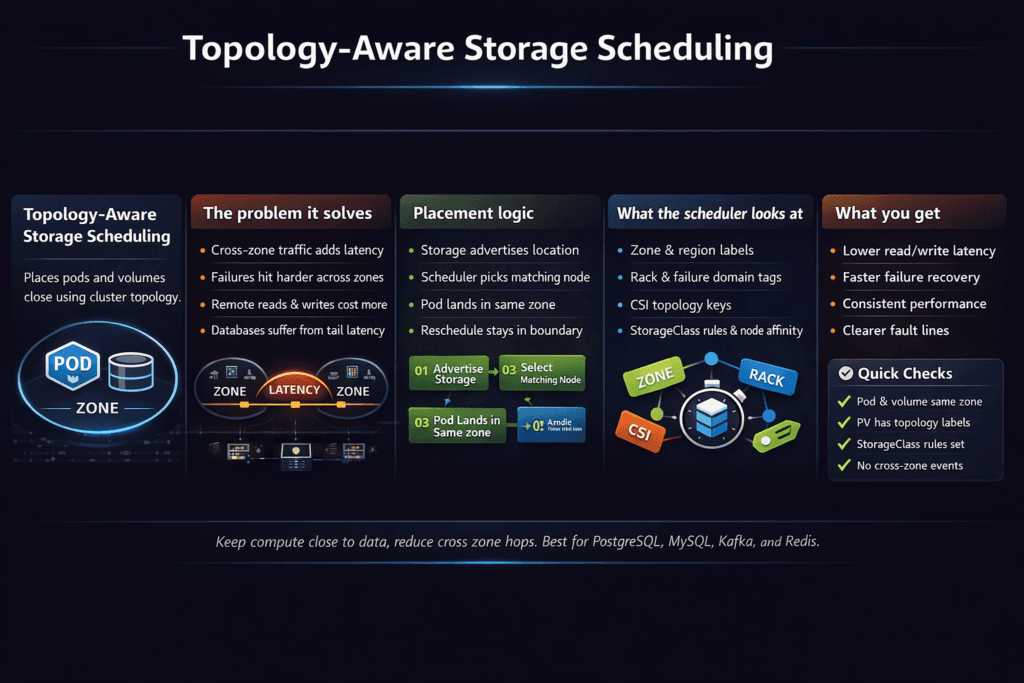
Topology-Aware Storage Scheduling aligns pod placement with where a volume can live and attach. It matters most in multi-zone or rack-aware clusters, where a volume has hard locality rules. If Kubernetes places a pod in the wrong zone, the mount fails, or the pod runs with extra network hops and higher tail latency.
This topic sits at the intersection of Kubernetes Storage and failure domains. It also changes cost and performance. Cross-zone I/O adds latency, burns bandwidth, and can raise cloud spend. A topology-aware plan keeps data close to the workload and reduces surprise behavior during node drains and rolling updates.
Executives usually see this as a reliability and cost problem. Platform teams see it as scheduler rules, StorageClass settings, and CSI behavior that must work together.
Topology-Aware Storage Scheduling with Modern Solutions
Teams used to “fix” storage placement with manual node pinning. That approach breaks down as clusters grow. Modern designs use policy so the platform can make repeatable choices.
Three controls do most of the work. StorageClasses define binding behavior and topology limits. The scheduler picks a node that satisfies compute and topology rules. The CSI driver provisions or attaches a volume that matches that node’s topology.
Software-defined Block Storage helps because it can enforce placement intent while still giving teams a shared pool of capacity. It also supports multi-tenancy and QoS, which keeps one team’s burst from pushing another team into latency spikes.
🚀 Turn Storage Placement into Policy, Not Manual Pinning
Use simplyblock Software-defined Block Storage to keep scheduling repeatable at scale.
👉 simplyblock Technology Overview →
How Kubernetes Places Pods and Volumes
Kubernetes uses several signals to place stateful workloads. Node labels represent zones, racks, or other segments. Affinity rules bias placement. Taints and tolerations restrict where pods can run. CSI topology adds storage-side constraints, so the scheduler avoids nodes that cannot use the requested volume.
The biggest operational gap shows up during change. Node drains, auto-scaling, and rolling updates happen often. If topology rules are loose, Kubernetes may move pods into segments that cannot attach their volumes. If topology rules are too strict, pods may sit pending when capacity shifts.
A good design stays strict on failure domain and volume access, while staying flexible on the rest. That balance keeps Kubernetes Storage schedulable under pressure.
Topology-Aware Storage Scheduling and NVMe/TCP Latency
Topology-Aware Storage Scheduling directly affects the storage path length. When a pod talks to storage in the same zone or rack, it avoids extra hops and reduces jitter. When a pod crosses zones, p99 rises fast, even if average latency looks fine.
NVMe/TCP amplifies this effect because it can deliver high parallel I/O on standard Ethernet. That speed helps only when the network path stays short and stable. When topology drift adds hops, the workload pays the cost in tail latency and CPU overhead.
Simplyblock uses an SPDK-based, user-space, zero-copy design to reduce overhead in the hot path. That helps Kubernetes Storage keep more CPU available for workloads, and it helps NVMe/TCP maintain steadier latency under load. This matters most for databases, queues, and search engines that react to jitter.
Measuring and Benchmarking Placement Impact
Measure topology issues the same way you measure any performance risk: with repeatable tests and clear percentiles. Track p50, p95, and p99 latency, plus throughput and host CPU. Then compare results across three scenarios: same-node or same-rack access, same-zone access, and cross-zone access.
Also measure operational behavior. How long do pods stay pending after a rollout? Track mount error rates and attach time. Watch rebuild behavior during node loss. These signals show whether the scheduler and storage layer cooperate under stress.
If you only track average IOPS, you will miss the real cost of poor placement.
Approaches for Improving Placement and Reducing Cross-Zone I/O
Use a small set of changes, then validate each one with the same test plan.
- Set your StorageClass to delay binding until the scheduler picks a node when your backend has zonal limits, and enforce allowed topologies when you need strict placement.
- Use node and pod affinity rules to keep replicas spread across failure domains, while keeping each replica close to its own volume.
- Use taints and tolerations to reserve storage-capable nodes for stateful workloads and prevent accidental placement on nodes that cannot satisfy volume needs.
- Add QoS and multi-tenant limits so a busy tenant does not force reschedules and latency spikes for others.
- Prefer Software-defined Block Storage that supports Kubernetes-native automation, so the platform can react to change without manual pinning.
Side-by-Side Performance Factors
The table below compares common scheduling patterns teams use to handle topology and persistent volumes.
| Pattern | What it optimizes | Common downside | Best fit |
|---|---|---|---|
| Immediate volume binding | Fast PVC binding | Can bind volumes in the “wrong” zone | Single-zone or uniform backends |
| Delayed binding (scheduler-first) | Correct zone and attach success | Pods may wait longer when capacity is tight | Multi-zone Kubernetes Storage |
| Strict topology rules | Strong locality and cost control | More pending pods if rules are too narrow | Regulated or latency-sensitive apps |
| Loose topology rules | Higher schedulability | More cross-zone I/O and higher p99 | Batch jobs with elastic SLOs |
Stronger Kubernetes Storage Outcomes with Simplyblock™ Software-defined Block Storage
Simplyblock™ targets clean scheduling outcomes by pairing Kubernetes-native control with Software-defined Block Storage. It supports NVMe/TCP and flexible deployment models, including hyper-converged and disaggregated clusters. That flexibility helps teams keep workloads near their data while still scaling capacity across the fleet.
Because simplyblock uses SPDK, it reduces CPU overhead in the storage data path. Combined with QoS and multi-tenancy controls, that design helps hold p99 steady even when many teams share the same Kubernetes Storage platform.
Future Trends in Topology-Aware Storage Scheduling
Topology-Aware Storage Scheduling will keep moving toward tighter feedback loops. Expect stronger scheduler signals around storage capacity, faster placement decisions under churn, and better automation for multi-zone failover. Teams will also push more of the data path into DPUs and IPUs to preserve CPU for applications.
As NVMe/TCP adoption grows, placement quality will matter more. Fast storage makes network distance visible. The teams that control topology will control p99.
Related Terms
Short companion terms teams review alongside Topology-Aware Storage Scheduling:
- CSI Topology Awareness
- Kubernetes Topology Constraints
- Storage Affinity in Kubernetes
- Node Taint Toleration and Storage Scheduling
Questions and Answers
Topology-aware scheduling uses CSI topology keys and PV node/zone constraints to ensure Pods land only where the requested volume can be provisioned, attached, and mounted. When combined with volumeBindingMode: WaitForFirstConsumerthe scheduler can pick a node first, then bind a compatible PV in the same failure domain, reducing “Pod scheduled but volume stuck” scenarios. This relies on accurate CSI topology reporting through the CSI Architecture.
WaitForFirstConsumer vs immediate binding for topology-constrained StorageClasses?Immediate binding can lock a PVC to a PV in a zone that later conflicts with Pod placement, especially in multi-AZ clusters or with limited capacity per zone. WaitForFirstConsumer defers PV selection until the scheduler has a concrete node/zone decision, aligning volume provisioning with compute topology. It’s the safer default when topology or capacity varies across zones, and you want fewer reschedules and faster readiness for stateful Pods.
Pod anti-affinity and topology spread can distribute replicas across zones, but topology-aware storage must also ensure each replica gets a volume available in its target zone. If the storage backend has uneven per-zone capacity, strict spreading can deadlock scheduling. The fix is to align spread constraints with actual storage failure domains and validate that PV provisioning rules support that distribution using storage affinity in Kubernetes.
Typical failures include missing or incorrect topology keys, nodes not labeled consistently, CSI drivers advertising partial topology, or StorageClasses that don’t match the driver’s supported parameters. Another frequent issue is forcing placement with taints/tolerations or hard node selectors that contradict PV topology constraints, leading to mount loops. Cross-check scheduling rules with Node taint/toleration and storage scheduling to avoid “forced” dead ends.
Track scheduling latency, PVC binding delays, and mount/attach errors alongside storage-side saturation to detect topology bottlenecks early. Event patterns like repeated FailedScheduling volume topology messages often indicate zone capacity imbalance or conflicting constraints. Pair Kubernetes events with storage metrics in Kubernetes to confirm whether failures are topology-policy driven or caused by backend performance/limits.