SPDK Initiator
Terms related to simplyblock
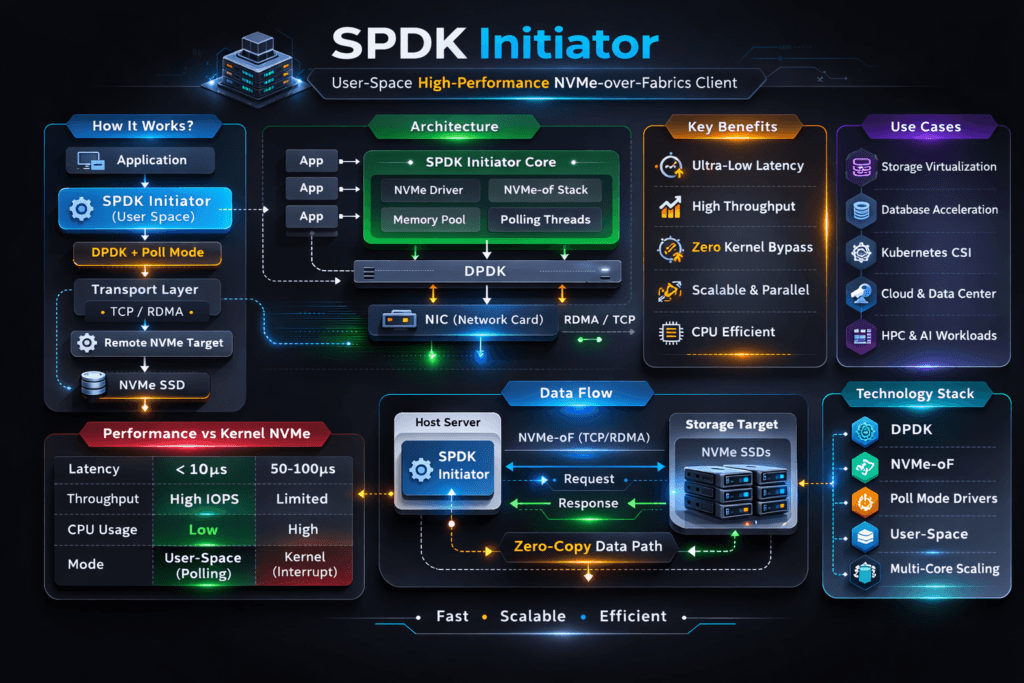
An SPDK Initiator is the host-side component that sends NVMe or NVMe-oF commands from user space, using the SPDK stack instead of the kernel I/O path. In NVMe-oF designs, the initiator connects to a remote NVMe subsystem over a fabric transport such as NVMe/TCP or RDMA, then exposes namespaces to applications through a tight, CPU-efficient path.
Executives track initiator behavior because it can set the ceiling for latency, IOPS per core, and tail stability under load. Platform teams track it because initiator CPU pressure can look like “storage is slow” even when the target and media sit idle.
Faster I/O Paths for Shared Block Storage
Performance work starts in the hot path, not the SSD spec sheet. SPDK keeps I/O in user space, avoids extra copies, and often uses polling to cut interrupts and context switches. That model can raise IOPS per core and reduce jitter when concurrency rises.
A strong storage layer still matters because initiator speed alone does not guarantee stable results. Multi-tenant clusters need QoS, clear limits, and repeatable provisioning so one workload cannot take all queues, CPU, or bandwidth. This is where Software-defined Block Storage improves day-to-day outcomes.
🚀 Compare SPDK vs Kernel Fast Paths Before You Standardize
Use Simplyblock guidance to pick the right initiator path for CPU efficiency and tail latency.
👉 SPDK vs Kernel Storage Stack →
SPDK Initiator for Kubernetes Storage Operations
In Kubernetes Storage, the initiator choice affects node behavior during bursts, rollouts, and reschedules. When the node CPU throttles, the storage path slows down, and database pods feel it first. If the storage stack shares cores with app threads, tail latency often climbs.
An SPDK-based approach works best with a clear node design. Teams usually dedicate CPU cores for the storage datapath, keep network paths clean, and size nodes for real queue depth and concurrency. With the right CSI integration, the platform can provision fast block volumes while app teams keep manifests simple.
Transport Notes That Impact Tail Latency
NVMe/TCP gives teams a practical way to run NVMe-oF on standard Ethernet. It lowers adoption friction, and it fits routed networks with familiar ops workflows. Many environments also avoid the fabric tuning work that RDMA rollouts can bring.
The initiator still drives p95 and p99 latency. TCP settings, RSS queues, IRQ pinning, and CPU headroom all shape results. SPDK can push more work per core, but only if the node protects those cycles.
How to Benchmark Initiator Behavior in Real Conditions
Benchmark the initiator as part of the full path. Capture latency percentiles, not only averages. Track CPU per IOPS, and confirm the node keeps headroom at peak load. In Kubernetes, run tests from inside pods, and keep the storage class consistent across runs.
Use profiles that match production. Small-block random I/O exposes queue contention and tail risk. Large-block sequential I/O exposes throughput limits and network pacing. Add failure-mode tests, such as a node drain or device loss, because rebuild behavior often decides SLO fit.
Practical Steps That Improve SPDK Initiator Throughput
Most gains come from protecting the CPU, keeping networking clean, and matching queue depth to the workload.
- Pin storage datapath threads to dedicated cores, and keep app threads on separate cores.
- Isolate storage traffic at the NIC or VLAN level, and watch retransmits during load spikes.
- Tune queue depth in small steps, and stop when latency rises faster than throughput.
- Keep firmware, drivers, and NIC settings consistent across nodes to avoid split behavior.
- Apply QoS so one tenant cannot saturate shared resources during backups or reindex jobs.
SPDK Initiator Compared to Common Initiator Paths
The table below highlights common initiator paths teams compare when they build NVMe-oF with NVMe/TCP for shared block volumes.
| Dimension | SPDK Initiator (user space) | Linux Kernel NVMe-oF Initiator | Legacy SCSI-era initiator (typical) |
|---|---|---|---|
| Data path | User space, low-copy design | Kernel-based | Kernel-based, older stack |
| CPU efficiency | Often strong at high concurrency | Often solid, varies by tuning | Often higher overhead |
| Tail latency control | Best with dedicated cores and a clear node design | Can drift under IRQ and scheduler pressure | Can drift under load |
| Operational fit | Best with dedicated cores and clear node design | Familiar ops, broad defaults | Familiar, but older constraints |
| Best fit | Performance-first block volumes, SAN alternative | General deployments, fast rollout | Compatibility-first environments |
Results with Simplyblock™
Simplyblock™ targets clusters that need stable latency, high IOPS, and clean multi-tenant controls. It delivers Software-defined Block Storage built around NVMe semantics, with NVMe/TCP support for disaggregated, hyper-converged, and mixed designs in Kubernetes Storage.
For initiator-heavy workloads, the key is datapath discipline plus isolation. Simplyblock aligns with SPDK-style user-space design goals, then adds tenancy controls and QoS so performance stays predictable when multiple teams share the same storage pool. This matters for databases, queues, and search platforms where p99 latency drives user impact.
Roadmap Themes for Initiator Efficiency
Initiator work keeps moving toward higher efficiency per core and stronger isolation. Expect more focus on network queue steering, better CPU pinning defaults, and clean integration with observability pipelines.
CPU offload patterns using DPUs and IPUs will also gain traction, especially in NVMe-oF deployments that push dense multi-tenant traffic.
Related Terms
Teams often cross-reference these terms for SPDK Initiator performance planning.
Questions and Answers
An SPDK initiator keeps the I/O fast path in user space, which cuts syscall/context-switch overhead and can stabilize tail latency under high queue depth. The gain is usually bigger on small-block random I/O where CPU overhead dominates, especially in Ethernet-based designs using NVMe over TCP Architecture and the SPDK vs Kernel Storage Stack tradeoffs.
SPDK initiators often use polling to hit consistent latency, so the CPU becomes a first-class capacity dimension. If you under-allocate cores, you’ll see p99 spikes even when storage is healthy; if you over-allocate, you waste compute. Validate CPU-per-IO and latency goals with Storage Latency vs Throughput and a repeatable Storage Performance Benchmarking method.
Test reconnect behavior, queue depth sensitivity, and throughput under loss/recovery scenarios, not just steady-state peak IOPS. A simple way is controlled fio runs that mirror your real block sizes and concurrency, then compare p95/p99 under load. Use Fio NVMe over TCP Benchmarking and cross-check results against SPDK Architecture assumptions.
The initiator is the host-side endpoint that submits NVMe commands over an NVMe-oF transport (often NVMe/TCP) to a user-space target. End-to-end behavior depends on both sides: target CPU budget, queue handling, and transport tuning. For architecture reviews, treat it as one pipeline spanning SPDK Target plus NVMe over TCP Architecture, not two independent components.
Because distributed block I/O can become network-limited once concurrency rises: replication, retries, or simple east–west contention can cap throughput and inflate tail latency. If adding faster SSDs doesn’t improve performance, the bottleneck is often the fabric, not storage. Confirm by correlating initiator latency with Storage Network Bottlenecks in Distributed Storage and your NVMe/TCP architecture choices.