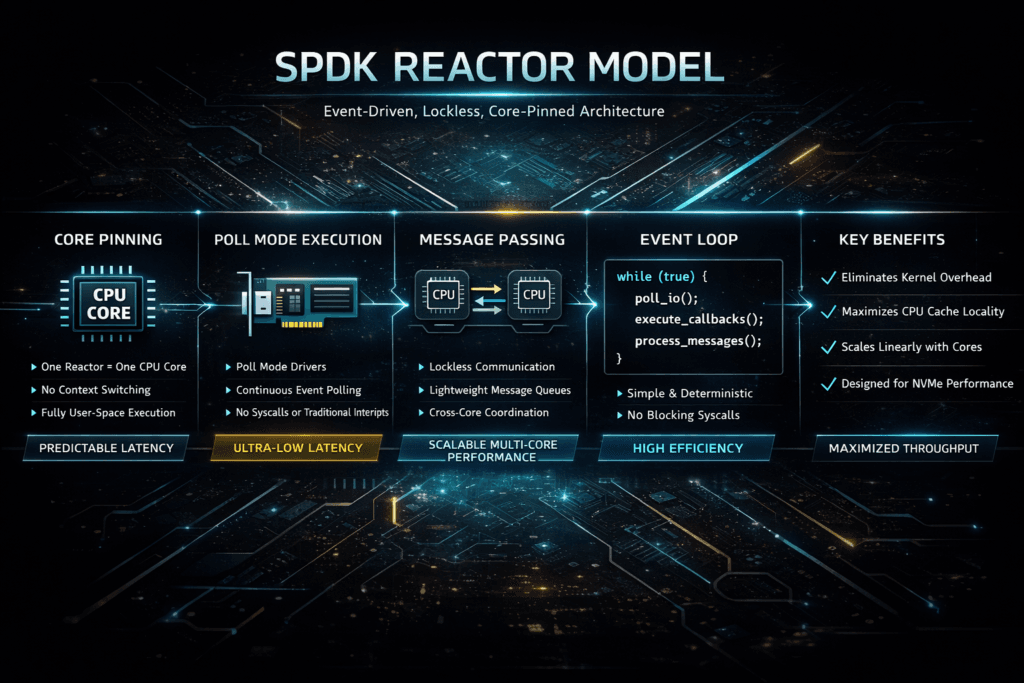
SPDK Reactor Model
Terms related to simplyblock
The SPDK Reactor Model is the scheduling design SPDK uses to run storage work on pinned CPU cores. Each reactor runs a tight loop on a core, then executes small tasks in that loop. This design reduces context switches and avoids many kernel hot-path costs. Teams often compare it to a kernel-based stack that depends on interrupts and the OS scheduler, especially when they plan Kubernetes Storage for high I/O apps.
Reactor-based storage can deliver tighter tail latency, but it also demands clear CPU planning. If you oversubscribe cores or ignore NUMA, latency jumps fast. If you reserve the right cores and keep the layout clean, Software-defined Block Storage can scale with steadier p95 and p99 results.
How the Reactor Loop Shapes the Storage Fast Path
SPDK treats the CPU as a first-class part of storage design. The reactor loop keeps working close to the core’s cache, and it runs storage tasks in short cycles. That approach can cut jitter, because the OS scheduler does less work in the hot path.
A kernel stack can still run well, yet it often pays more overhead under high concurrency. Interrupt storms, lock pressure, and cross-core wakeups can raise tail latency. Reactor-based designs aim to limit those triggers by keeping the I/O loop simple and direct.
🚀 Put SPDK-Class Performance Into Production Storage Operations
Use Simplyblock to combine a fast data path with Kubernetes-ready lifecycle control.
👉 See Simplyblock Technology →
SPDK Reactor Model in Kubernetes Storage
Kubernetes Storage adds churn and contention. Pods restart, nodes drain, and many teams share the same cluster. The reactor model helps because it makes storage scheduling more repeatable. Instead of letting the OS move work across cores, you pick the cores and keep the work there.
This matters when stateful apps run next to batch jobs. A reactor-based storage plane can protect against latency if you isolate its cores. It can also improve density, because you can track “IOPS per core” and plan capacity with fewer surprises.
For platform owners, the main rule stays simple: reserve CPU for storage, then enforce it with policies. When you skip that step, the cluster trades short-term utilization for long-term instability.
SPDK Reactor Model and NVMe/TCP
NVMe/TCP runs NVMe-oF over standard Ethernet, which helps many teams avoid a specialized fabric. It can also raise CPU load at high I/O rates. The reactor model fits well here because it keeps the hot loop in user space and reduces context switches.
A clean layout makes a big difference. Put the NIC queues and NVMe devices on the same NUMA node as the reactor cores when you can. Keep queue depth aligned to the app pattern instead of pushing it to extremes. These choices often decide whether NVMe/TCP feels like a SAN alternative or a tuning project that never ends.
Benchmarking the SPDK Reactor Model Under Real Load
Benchmarking should prove two outcomes: stable latency percentiles and efficient CPU use. Run tests long enough to reach steady state, then repeat them to confirm the result.
- Measure p50, p95, and p99 latency as you raise the queue depth in steps.
- Track CPU use per IOPS on initiator and target nodes.
- Test mixed I/O, such as a 70/30 read/write pattern, to expose tail behavior.
- Re-run the same profile during a node restart to see how the system behaves under churn.
Also record core masks and NUMA placement for every run. Those inputs often explain more variance than the storage media.
Tuning Moves That Improve Tail Latency
Start with core isolation. Pin reactor cores and keep the app noise off those cores. Next, align memory and devices to reduce remote NUMA hops. After that, tune the queue depth to match the workload’s parallelism.
Watch for two common failure modes. Some teams oversubscribe CPU, then blame storage for jitter. Other teams ignore NUMA and pay a latency tax on every I/O. Fixing either issue can deliver a clear gain without new hardware.
Decision Matrix for Reactor Scheduling vs Kernel I/O
This comparison focuses on what shows up in production: tail latency, CPU cost, and day-two clarity for Software-defined Block Storage.
| Area | Reactor-based SPDK path | Kernel-based path |
|---|---|---|
| Scheduling style | Pinned cores, polled loop | Interrupts and OS scheduler |
| Tail latency under contention | Often tighter with clean core policy | Often wider under mixed load |
| CPU cost per I/O | Often lower when tuned | Can rise with syscalls and wakeups |
| Ops mindset | CPU and NUMA planning first | Familiar defaults, but indirect tuning |
| Best fit | Performance-first Kubernetes Storage | General-purpose stacks with simple setup |
Why Simplyblock Uses Reactor-Style Design
Simplyblock™ applies SPDK concepts to keep the storage fast path lean and repeatable. It targets Kubernetes Storage with NVMe/TCP support and delivers Software-defined Block Storage with multi-tenancy and QoS controls. That mix helps teams protect tail latency in shared clusters, where noisy neighbors can break SLOs.
Platform teams also care about day-two work. A storage service succeeds when it stays stable during upgrades, reschedules, and scale-outs. Reactor-style scheduling supports that goal by making CPU behavior easier to plan and easier to enforce.
Where Reactor-Based Storage Goes Next
Reactor-based designs will keep gaining ground as clusters pack more workloads per node. DPUs and IPUs will also push storage work closer to the network edge, which fits user-space, pinned-core models. At the same time, Kubernetes will keep pushing for faster lifecycle actions and clearer isolation.
Expect more focus on smarter core use, better fairness for multi-tenant workloads, and tighter integration with NVMe-oF transports. Teams that pair these advances with a clean ops policy will see the biggest gains.
Related Terms
Teams pair these glossary pages with the SPDK Reactor Model when they tune Kubernetes Storage.
DPDK (Data Plane Development Kit)
NVMe Performance Tuning
Fio NVMe over TCP Benchmarking
Storage Offload on DPUs
Questions and Answers
The SPDK reactor model pins lightweight pollers to CPU cores and runs I/O work in tight user-space loops, reducing context switches and lock contention. This makes p99 latency more predictable at high queue depths, especially when you’re avoiding the kernel fast path. It’s typically evaluated alongside SPDK architecture and the SPDK vs kernel storage stack tradeoff for CPU efficiency.
You want reactor-to-core pinning that aligns with NIC RSS queues and NVMe queue pairs to minimize cross-core bouncing. If RX/TX interrupts or queue processing lands on different cores than the pollers, latency jitter rises and scaling flattens early. This is why SPDK deployments treat CPU affinity as part of the storage data path design, not a tuning afterthought, consistent with a storage data plane mindset.
Polling consumes CPU even when idle, but it buys deterministic latency by avoiding sleep/wake overhead and scheduler variability. For latency-sensitive block workloads, spending cores for stability can be the best trade, especially when the alternative is unpredictable p99 under load. Use storage latency vs throughput to justify the choice based on SLOs rather than peak IOPS alone.
Instead of shared locks across threads, SPDK encourages per-core ownership and message passing between reactors. That means most hot-path state stays local to a core, and cross-core operations become explicit messages rather than implicit contention. This architecture is a common reason SPDK can scale linearly on modern CPUs compared to more lock-heavy stacks, as explained by SPDK architecture.
The usual culprits are core oversubscription (too many pollers per core), mismatched NUMA locality between NIC and NVMe, and mixing noisy app threads on reactor cores. Any of these forces causes cache misses and cross-socket traffic that shows up as latency spikes. Validate with disciplined storage performance benchmarking and keep the hot path aligned with the SPDK vs kernel storage stack assumptions.