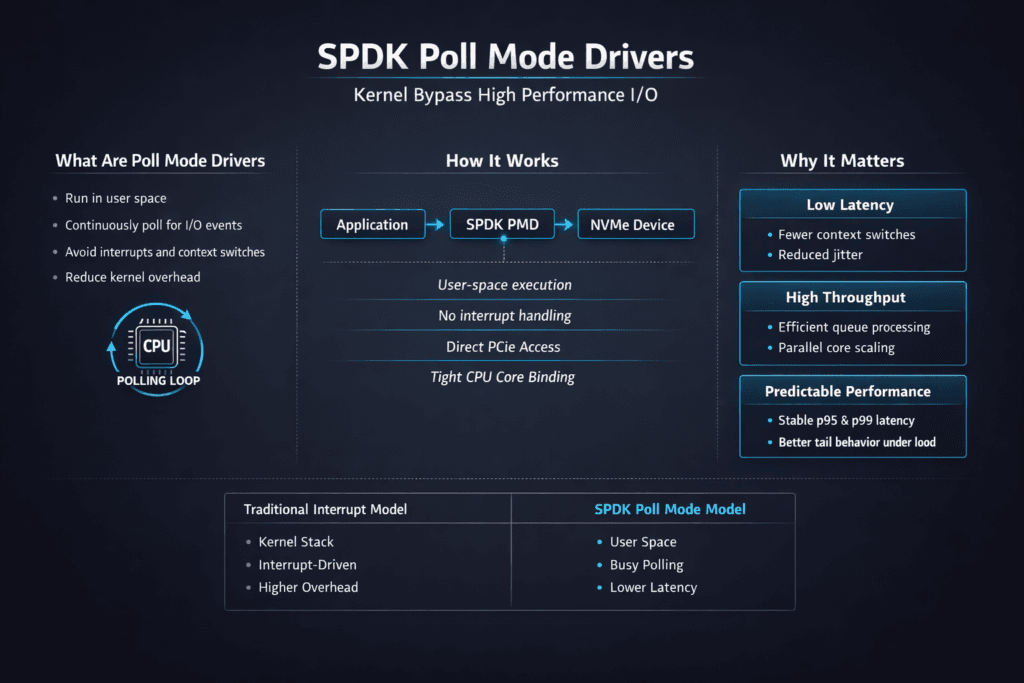
SPDK Poll Mode Drivers
Terms related to simplyblock
SPDK Poll Mode Drivers run storage I/O in user space and keep the CPU “in the loop” by polling queues instead of waiting for interrupts. This design cuts context switches, reduces kernel overhead, and helps keep latency steady when I/O depth climbs. Teams often pair this approach with NVMe/TCP to get shared, high-performance block volumes on standard Ethernet.
For execs, the value shows up as more stable p95 and p99 latency and better IOPS per core. For DevOps and SRE teams, it shows up as cleaner performance isolation when noisy neighbors hit Kubernetes Storage nodes.
Why Polling Changes the CPU Cost Model
Interrupt-driven stacks work well for mixed workloads, but they pay overhead every time the kernel schedules work, handles interrupts, and copies buffers. Polling flips the model. A dedicated core stays busy and drains queues fast, which can reduce jitter for latency-sensitive apps.
This tradeoff only works when you plan for it. Polling consumes CPU by design, so node sizing and CPU pinning matter. When you combine that design with Software-defined Block Storage, you can also add QoS controls so one tenant cannot monopolize CPU cycles or network bandwidth.
🚀 Validate SPDK Poll Mode Drivers vs Kernel Paths Before You Commit
Use Simplyblock to compare user-space polling against kernel stacks and pick the right CPU model.
👉 SPDK vs Kernel Storage Stack →
SPDK Poll Mode Drivers in Kubernetes Storage Nodes
SPDK Poll Mode Drivers fit best when your Kubernetes Storage nodes treat storage as a first-class workload. That means you reserve cores, separate storage traffic, and keep the data path consistent across nodes.
In clusters that mix stateless and stateful services, polling helps most when databases compete for latency. Transactional systems often punish jitter more than they punish a lower peak number. A poll-mode path can reduce those spikes, as long as the platform protects the CPU and avoids co-locating heavy app threads on the same cores.
NVMe/TCP Data Path Considerations
NVMe/TCP gives teams a practical way to run NVMe-oF on standard Ethernet. It lowers adoption friction and fits routed networks with familiar ops workflows. Many environments also avoid the fabric tuning work that RDMA rollouts can bring.
TCP still needs care. RSS queues, IRQ steering, and retransmit rates can decide whether p99 latency stays flat or drifts under load. Poll mode helps the storage stack keep pace, but it cannot fix a congested network or a node that runs out of CPU headroom.
Benchmarking Poll Mode Under Load
Poll-mode stacks need benchmarks that reflect production conditions. Microbenchmarks can flatter the stack, while real clusters add contention from other pods, rollouts, and background tasks.
Measure more than throughput. Track p50, p95, and p99 latency, plus CPU per IOPS. Run tests from inside pods so you capture the full path that Kubernetes Storage uses. Add a stress run where you create noisy neighbors or drain a node, because that is where jitter often shows up.
Tuning Levers That Matter Most
Most gains come from clear CPU ownership, clean networking, and sane queue settings. Apply changes one at a time, and keep each change measurable.
- Reserve and pin cores for the poll-mode path, and keep app threads off those cores.
- Keep storage traffic on dedicated NICs or VLANs, and watch retransmits during spikes.
- Increase queue depth in small steps, and stop when latency rises faster than IOPS.
- Standardize firmware, drivers, and BIOS settings across nodes to avoid drift.
- Use QoS in Software-defined Block Storage to protect critical tenants and tiers.
SPDK Poll Mode Drivers vs Interrupt-Driven Drivers
The comparison below shows how teams typically weigh poll mode against interrupt-driven paths when they run NVMe/TCP in shared block environments.
| Dimension | Poll mode (SPDK-style) | Interrupt-driven (kernel-style) |
|---|---|---|
| CPU behavior | Dedicated cores stay busy | CPU wakes on interrupts |
| Latency profile | Starvation if the CPU is not reserved | Can jitter under contention |
| Ops requirements | Needs pinning and sizing discipline | Works with broader defaults |
| Best fit | Performance-first, low-jitter apps | General-purpose mixed loads |
| Risk area | Starvation if CPU is not reserved | Tail latency under bursty load |
Results with simplyblock™
Simplyblock™ delivers Software-defined Block Storage that targets high I/O density and stable latency for Kubernetes Storage. It supports NVMe/TCP and aligns with SPDK-style user-space goals, which helps teams reduce kernel overhead in the hot path.
For environments that want poll-mode benefits without fragile tuning, simplyblock adds multi-tenancy and QoS so performance stays consistent across teams, clusters, and workload tiers. That mix helps when multiple databases share the same storage pool and still need clear SLO boundaries.
What to Expect Next in Poll-Mode Storage Design
Poll-mode designs will keep gaining traction as storage stacks chase better efficiency per core. More teams will also push CPU offload with DPUs and IPUs, which shifts parts of the data path away from host cores.
As that happens, the most important skill will stay the same: you design the node around the storage path, then you enforce isolation so the result stays stable.
Related Terms
Teams often cross-reference these terms for SPDK Poll Mode Drivers performance planning.
- NVMe over TCP Architecture
- Kubernetes Storage Performance Bottlenecks
- Storage Offload on DPUs
- Persistent Storage for Kubernetes Databases
Questions and Answers
SPDK poll mode drivers continuously poll NVMe and NIC queues in user space, avoiding interrupt storms, scheduler wakeups, and context switches that inflate p99 under load. The result is steadier latency at high IOPS, but it trades idle CPU for determinism. This is why PMDs are typically discussed in SPDK architecture and contrasted with the SPDK vs kernel storage stack model.
Poll mode drivers depend on strict CPU affinity: pin pollers to isolated cores, keep NIC and NVMe on the same NUMA socket, and avoid sharing reactor cores with application threads. If queues or memory cross sockets, cache misses and remote memory access show up as p99 spikes. Treat this as a data-path design choice aligned with a storage data plane architecture, not a last-minute tuning step.
PMDs can hit a ceiling when PCIe bandwidth, memory bandwidth, or east–west network contention becomes the limiter. At that point, adding faster SSDs won’t improve p99 or throughput because the bottleneck is outside the device. Confirm by correlating queue depth, CPU utilization, and fabric saturation using storage network bottlenecks in distributed storage, plus end-to-end storage latency vs throughput measurements.
Use workload-shaped tests that match your real block sizes, read/write mix, and concurrency, then focus on p95/p99 and CPU-per-IOPS, not just peak throughput. Also test degraded conditions like packet loss, reconnects, and sustained background load. A reliable baseline is repeatable storage performance benchmarking plus targeted fio NVMe over TCP benchmarking runs.
The classic issues are core oversubscription, mixed workloads sharing PMD cores, and unstable NIC queue configuration that forces cross-core processing. Those missteps convert polling from “deterministic” to “busy and noisy,” producing microbursts and tail-latency cliffs. Tight operational guardrails and continuous telemetry are critical, using storage metrics in Kubernetes if the initiators run in clusters, and validating assumptions against SPDK architecture.