SPDK vs iSCSI Target
Terms related to simplyblock
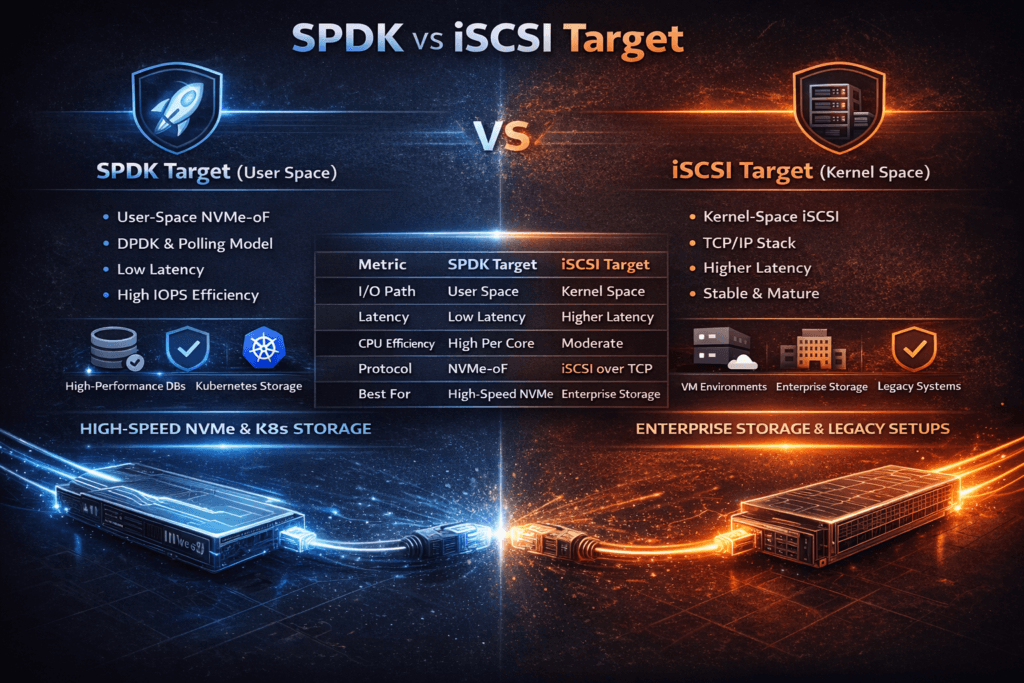
SPDK vs iSCSI Target compares two ways to serve remote block storage over Ethernet. iSCSI carries SCSI commands over TCP/IP and works in almost every environment. SPDK uses a user-space data path and targets low latency and high IOPS on NVMe media. Teams often run this comparison when a legacy SAN design starts to limit performance or when Kubernetes clusters need steadier p99 latency.
This topic matters because the bottleneck often shifts from disks to CPU and networking. A traditional iSCSI stack can spend a lot of CPU time on interrupts, context switches, and copying. A user-space SPDK approach aims to cut that overhead and deliver more IOPS per core. The trade-off usually shows up in operations: iSCSI feels familiar, while SPDK-based targets demand tighter tuning and clearer platform guardrails.
When SPDK vs iSCSI Target Matters for Platform Decisions
Executives usually care about three outcomes: stable application latency, predictable scaling, and lower cost per workload. The SPDK vs iSCSI Target discussion becomes urgent when teams add faster NVMe drives but still fail to improve p99 latency. It also shows up when a storage team wants to reduce SAN footprint and simplify network design.
Ops teams care about different signals. They watch CPU saturation during peak write bursts, noisy-neighbor impact across tenants, and rebuild behavior during node loss. They also care about how fast the platform provisions volumes and how often tuning drifts after kernel, NIC, or firmware updates.
🚀 Replace iSCSI Limits With NVMe/TCP Headroom
Use Simplyblock to modernize Ethernet block storage and reduce CPU-driven p99 spikes.
👉 Use Simplyblock for NVMe/TCP Kubernetes Storage →
Kubernetes Storage Requirements That Shift the Comparison
Kubernetes Storage changes the rules because it adds churn and multi-tenancy. Pods move after drains. Autoscaling changes demand in minutes. Multiple teams share the same storage pools. Those factors punish deep queues and inconsistent scheduling.
CSI makes volume lifecycle easier, but CSI does not solve latency jitter by itself. The storage backend still sets the ceiling. In practice, teams want a backend that holds p99 steady during normal cluster change, not only during perfect lab tests.
SPDK vs iSCSI Target Under NVMe/TCP Transition Plans
Many teams now standardize on NVMe/TCP as they modernize Ethernet-based storage. NVMe/TCP maps well to routable IP networks and supports NVMe-oF semantics without special fabrics. It also gives platform teams a clear migration path away from older SCSI-based designs.
Here’s where the comparison gets practical. If your iSCSI path hits CPU limits before NVMe media saturates, NVMe/TCP with a user-space fast path can raise headroom. If your environment depends on legacy initiators, legacy tooling, or deep iSCSI feature use, iSCSI may still fit while you modernize the rest of the stack.
Measuring SPDK vs iSCSI Target Performance the Right Way
Benchmarks should answer two questions: how far can the system scale, and how stable does it stay under real change. Use the same block sizes, the same read/write mix, and the same sync pattern you run in production. Increase concurrency in steps and record p50, p95, and p99 latency along with throughput.
Test “busy mode” on purpose. Run recovery-like background load, run a noisy neighbor profile, and repeat the test during a node drain window. Many systems look fast in calm mode and fall apart in busy mode. Busy mode tells you which target protects the tail.
Track CPU per IOPS as a first-class metric. A design that delivers high IOPS but burns too many cores will not scale cost-effectively in Kubernetes.
Operational Levers That Improve Results Without Surprises
Use these actions to improve outcomes in either approach and to keep results repeatable.
- Pin and isolate CPU resources for storage and networking work, and align NUMA where possible.
- Measure packet rate headroom, not only bandwidth, especially on small-block I/O.
- Test p99 during background events, including rebuild and resync windows.
- Apply tenant controls so one workload cannot dominate queues in shared clusters.
- Keep configuration drift low by standardizing NIC settings, MTU, and queue settings across nodes.
Architecture Trade-offs Between User-Space Targets and iSCSI
The table below highlights the usual trade-offs teams see when they compare a user-space SPDK target approach with an iSCSI target approach in modern Ethernet environments.
| Approach | What limits scale first | Common symptom | Typical fit |
|---|---|---|---|
| Traditional iSCSI target stack | CPU overhead and queueing | Rising p99 under bursts | Broad compatibility, legacy estates |
| Tuned iSCSI on fast NICs | Packet rate, kernel overhead | High CPU at peak IOPS | Incremental upgrades, mixed hosts |
| SPDK user-space target | Network or media before CPU | Better IOPS per core | NVMe-heavy nodes, low-latency focus |
| NVMe/TCP with user-space fast path | TCP CPU or NIC limits | Stable p99 when tuned | Kubernetes-first designs, SAN alternative |
Kubernetes Storage With Simplyblock™ for Consistent Performance
Simplyblock™ focuses on the bottlenecks that often decide SPDK vs iSCSI Target comparisons: CPU cost per I/O, tail latency, and multi-tenant isolation. Simplyblock uses an SPDK-based user-space data path to reduce hot-path overhead, then adds controls that platform teams need for Kubernetes Storage, including multi-tenancy and QoS.
Simplyblock™ also supports NVMe/TCP and NVMe/RoCEv2, so teams can use standard Ethernet today and adopt RDMA where it makes sense. This approach supports a Software-defined Block Storage model that can replace SAN designs while keeping operations aligned with cloud-native workflows.
Where Ethernet Block Storage Is Heading Next
Teams increasingly optimize for p99 stability and performance per core. That focus pushes more platforms toward user-space data paths and clearer isolation controls.
Expect more use of DPUs/IPUs to offload networking and protocol work, especially on dense bare-metal nodes. Expect stronger observability for queueing and jitter, too, because operators need to find the exact layer that drives tail spikes.
Related Terms
Teams review these glossary pages alongside SPDK vs iSCSI Target during storage platform selection.
What is iSCSI
SPDK Target
SAN vs NVMe over TCP
NVMe over TCP Architecture
Questions and Answers
An SPDK target runs the I/O fast path in user space with poll-mode processing, reducing context switches and kernel overhead that typically add jitter to iSCSI under high queue depth. The advantage is most visible on small random I/O where CPU overhead dominates. This comparison is rooted in SPDK target design and the broader SPDK vs kernel storage stack tradeoff.
SPDK targets commonly expose NVMe-oF (often NVMe/TCP), which uses the NVMe command set optimized for parallel queues and low latency. iSCSI encapsulates SCSI over TCP and can introduce extra translation and queuing overhead, especially as concurrency rises. For Ethernet deployments, evaluate end-to-end behavior using the NVMe over TCP architecture rather than only peak throughput.
SPDK targets often “buy” determinism with dedicated pinned cores for pollers, so CPU is a capacity metric like IOPS. iSCSI targets are typically interrupt-driven and can share CPU more flexibly, but tail latency can be less stable under bursty load. If your goal is predictable latency, design around SPDK’s reactor model assumptions and validate using storage latency vs throughput.
Both can hit a “network wall” when east–west contention, oversubscription, or packet loss amplifies retries and queueing. SPDK may preserve lower software overhead, but it can’t outrun a saturated fabric. If scaling stalls despite fast NVMe, check storage network bottlenecks in distributed storage and confirm your NVMe over TCP architecture is aligned with your topology.
Don’t treat it as a simple protocol swap—validate multipath/failover behavior, reconnect time, and p99 under degraded conditions. Benchmark with production-like concurrency and track CPU-per-IOPS so initiators don’t become the new bottleneck. A practical workflow uses storage performance benchmarking plus targeted fio NVMe over TCP benchmarking before cutover.