NVMe over TCP vs iSCSI
Terms related to simplyblock
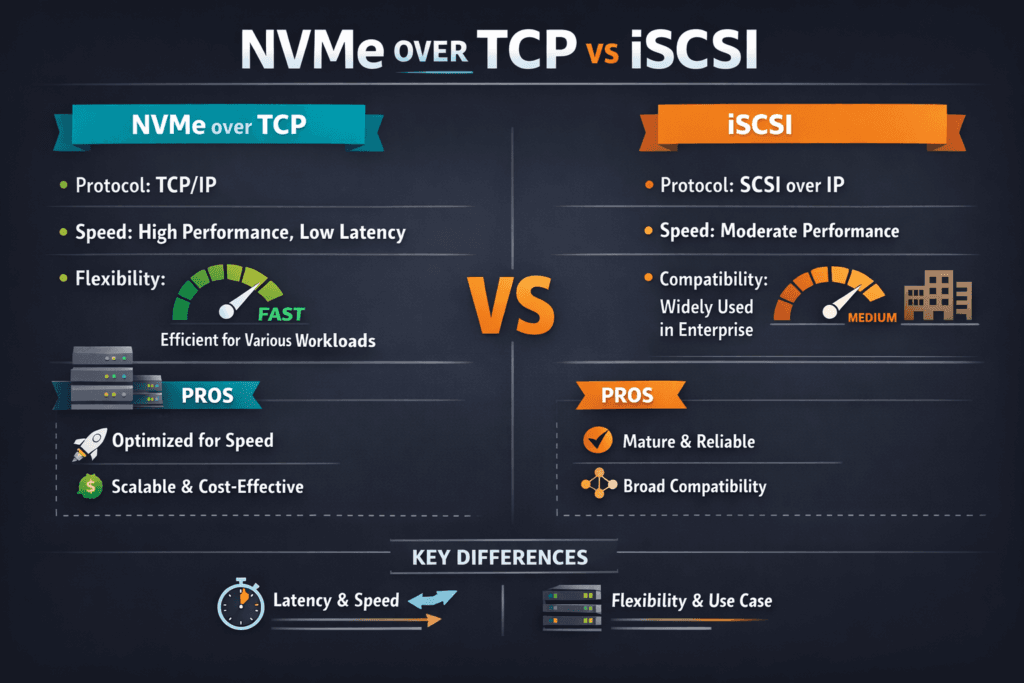
NVMe over TCP vs iSCSI compares two ways to move block I/O over IP networks, but the protocols come from different eras. iSCSI sends SCSI commands over TCP/IP and fits environments that rely on older SAN workflows and tooling. NVMe over TCP sends NVMe commands over TCP/IP and matches flash-era needs like deep queues, parallel I/O, and lower software overhead.
Leaders usually track three outcomes: steady latency under load, efficient CPU use on application nodes, and clean operations in Kubernetes Storage. NVMe over TCP often holds up better at high concurrency because NVMe was built for many queues and parallel work. iSCSI can still meet goals in compatibility-first shops, but tuning often becomes harder as load rises.
Modern Storage Networking Without Traditional SAN Lock-In
Teams that want a SAN alternative often choose Software-defined Block Storage to avoid hardware lock-in and to scale faster. This approach lets you refresh servers and drives without rewriting storage policies each time.
Platform teams also benefit from a software control plane. They can automate rollouts, keep settings consistent, and apply QoS rules across node pools. That discipline matters on bare-metal clusters, where shared CPU and NIC resources can push latency up fast.
🚀 Benchmark NVMe/TCP vs iSCSI on Your Workloads
Use Simplyblock to test NVMe/TCP performance and CPU efficiency side-by-side with iSCSI in Kubernetes Storage.
👉 See NVMe/TCP storage capabilities →
NVMe over TCP vs iSCSI in Kubernetes Storage
Kubernetes Storage exposes performance swings quickly. A small latency spike can slow database commits, raise retries, and stretch rollout windows. Cluster density makes the problem worse because storage code competes with application code for CPU time.
NVMe over TCP usually fits Kubernetes well because it scales with parallel queues and runs on standard Ethernet. iSCSI also works in Kubernetes, yet it often consumes more CPU per I/O as concurrency climbs. Your deployment model changes what you optimize. Hyper-converged nodes reward CPU efficiency and isolation, while disaggregated nodes reward strong network pathing and clear failure domains.
Why NVMe/TCP Improves Host Efficiency
NVMe/TCP brings NVMe semantics to TCP/IP without forcing RDMA across the whole fabric. That lowers the barrier for teams that already run Ethernet at scale.
A user-space data path can push efficiency further. SPDK-style design reduces context switches and avoids extra copies, so hosts spend fewer cycles per I/O. That headroom helps Kubernetes nodes run more pods per server without hitting a CPU wall.
Building a Benchmark That Matches Production
Good tests mirror real workloads. Use fio patterns that match block size, read/write mix, and concurrency. Sweep iodepth and job count to find the point where latency starts to drift.
Percentiles matter more than averages. Track p50 and p99 latency, then map those numbers to app SLOs. Include CPU metrics on both initiator and target, because protocol overhead shows up there first. Validate the network before you blame storage, since drops and retransmits can hide the real limit.
One Tuning Checklist That Improves Results
Use one repeatable set of steps so you can apply the same playbook across clusters:
- Pin storage threads to specific CPU cores, align IRQ affinity with NIC queues, and keep I/O NUMA-local.
- Set multipath policy on purpose, test failover under load, and keep path rules consistent.
- Match queue depth and parallel jobs to the app profile, then verify p99 latency stays within the target.
- Split storage traffic from east-west pod traffic during busy periods using VLANs or dedicated NICs.
- Keep MTU consistent end-to-end, and confirm low retransmits before you change storage knobs.
NVMe over TCP vs iSCSI Trade-Offs That Matter
The table below summarizes the differences teams most often see when they compare behavior under real concurrency in Kubernetes Storage and shared Ethernet fabrics.
| Category | NVMe over TCP | iSCSI |
|---|---|---|
| Command model | NVMe with many queues | SCSI with older semantics |
| CPU cost under load | Often lower per I/O with modern stacks | Often higher as concurrency rises |
| Latency pattern | Often tighter at high queue depth | Often wider spread under pressure |
| Scaling behavior | Built for flash-era parallelism | Can hit limits sooner |
| Kubernetes fit | Strong for dense stateful nodes | Works, but tuning load can rise |
| Typical best fit | Cloud-native DBs, analytics, shared NVMe pools | Compatibility-first estates, legacy tooling |
How Simplyblock™ Helps Control Latency and CPU Overhead
Simplyblock™ provides Software-defined Block Storage for teams that need stable performance in Kubernetes Storage. Its SPDK-based, user-space zero-copy design targets high throughput with better CPU efficiency, which helps on dense bare-metal clusters.
Simplyblock also gives operators tools that shape real outcomes. QoS and multi-tenancy controls reduce noisy-neighbor impact. Flexible deployment options support hyper-converged, disaggregated, and hybrid layouts, so teams can modernize without forcing one topology across every environment.
Future Signals for NVMe over TCP vs iSCSI
Enterprise roadmaps now favor NVMe/TCP on Ethernet-first data centers that want higher concurrency without fabric upheaval. Many orgs keep iSCSI where legacy systems require it, then shift new stateful platforms to NVMe/TCP to tighten tail latency and reduce CPU drag.
Hardware offload will push this trend further. DPUs and IPUs can take on parts of the data path and free the host CPU for apps. Teams will choose protocols based on measurable SLOs, automation fit, and cost per unit of performance, not just peak throughput.
Related Terms
One-click references for teams comparing NVMe/TCP and iSCSI for Kubernetes Storage.
- SPDK (Storage Performance Development Kit)
- SPDK vs iSCSI Target
- NVMe over Fabrics Transport Comparison
- Storage Network Bottlenecks in Distributed Storage
Questions and Answers
In many real-world tests, NVMe over TCP delivers higher IOPS and lower latency than iSCSI because it carries NVMe semantics end-to-end with less protocol overhead. The gap is most visible on small-block random I/O at high queue depth, where CPU and queuing dominate.
NVMe/TCP is optimized for flash-style parallel queues, so it can push more work per core before hitting scheduler and locking overhead that shows up as p99 jitter. iSCSI can remain “good enough” for moderate I/O, but CPU becomes a limiter sooner on heavy random workloads. Validate by correlating p95/p99 with your NVMe over TCP architecture.
Use the same block size, read/write mix, queue depth, and multipath setup, then compare p95/p99 and CPU, not just throughput. For NVMe/TCP, run repeatable fio profiles designed for remote namespaces using fio NVMe over TCP benchmarking so results reflect real host overhead and tail latency.
If you need maximum compatibility with legacy hosts, tooling, and existing SAN practices, iSCSI is often simpler operationally. NVMe/TCP is frequently chosen when you want SAN-like block access as an IP-native design and a clearer upgrade path for modern flash performance, especially as a SAN alternative.
Both run on Ethernet, but NVMe/TCP can reduce latency headroom requirements and simplify scaling for flash-heavy workloads, while iSCSI may reuse more legacy operational muscle memory. The practical comparison is network design, CPU sizing, and day-2 behavior under churn, plus the full NVMe over TCP cost comparison for your environment.