NVMe over Fabrics Architecture
Terms related to simplyblock
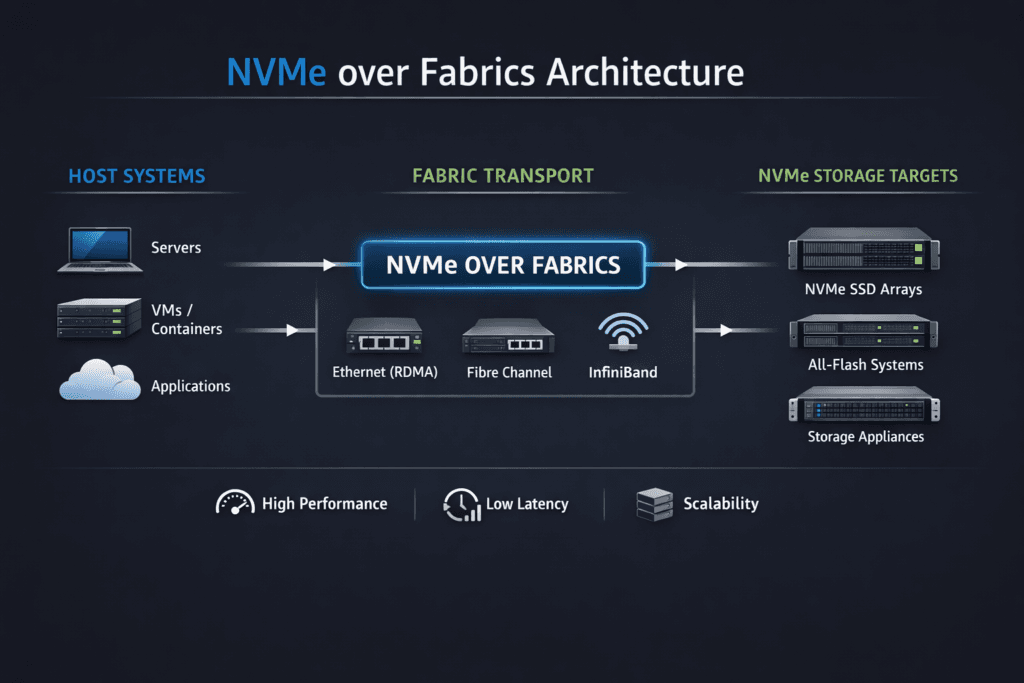
NVMe over Fabrics (NVMe-oF) architecture describes how systems extend the NVMe command set across a network so hosts can access remote NVMe media with low protocol overhead. The design separates initiators (clients that issue I/O) from targets (endpoints that expose NVMe namespaces) and uses multiple queue pairs to drive parallel I/O at scale.
Architects usually evaluate NVMe-oF architecture through three lenses: the transport (TCP, RDMA, or FC), the data path implementation (kernel vs user space), and the control plane that handles provisioning, isolation, and day-2 operations. This matters most when you run stateful workloads in Kubernetes Storage, where noisy neighbors, mixed I/O, and frequent scheduling changes can stress tail latency.
Engineering NVMe-oF for Low Latency and Stable Tail Behavior
A strong NVMe-oF design treats the network and the host as part of the storage stack. Queue depth, CPU placement, and NIC behavior shape latency as much as media speed. Teams that adopt Software-defined Block Storage can standardize these controls across hardware generations, which reduces operational drift.
User-space acceleration can also shift the efficiency curve. SPDK’s NVMe-oF target runs in user space and supports TCP and RDMA transports, which helps reduce context switching and extra copies in the hot path.
🚀 Run NVMe-oF Storage Pools Directly in Kubernetes
Use Simplyblock to simplify provisioning and keep performance steady across node pools.
👉 Use Simplyblock for Persistent Storage on Kubernetes →
NVMe over Fabrics Architecture in Kubernetes Storage
In Kubernetes, the storage path competes with application threads, networking, and runtime overhead. NVMe-oF architecture fits Kubernetes well when the platform uses CSI to provision volumes, enforce policies, and scale node pools without manual storage zoning.
The architecture choice also interacts with deployment style. Hyper-converged layouts often prioritize CPU efficiency per I/O, while disaggregated layouts prioritize predictable network paths and failure domain design. Simplyblock positions these options as first-class deployment modes for Kubernetes clusters.
NVMe over Fabrics Architecture and NVMe/TCP
NVMe/TCP maps NVMe queue pairs onto standard TCP/IP networking, which keeps adoption practical for Ethernet-first environments. It also avoids the “all or nothing” fabric decision that some teams face with RDMA-only approaches. The NVMe community designed NVMe-oF as a common architecture that supports multiple fabrics and scales to large NVMe device counts.
For many teams, NVMe/TCP becomes the default transport for broad rollout, while RDMA or FC-NVMe covers the narrow set of workloads that justify specialized networking or existing FC estates.
Measuring and Benchmarking Architecture Performance
Benchmark NVMe-oF architecture with workload shapes that match production. Use tests that vary block size, read/write mix, and concurrency. Report p50 and p99 latency, plus CPU consumption per I/O, because efficiency differences often decide the real cost per workload.
Also, validate the fabric before you tune storage. Retransmits, drops, and buffer pressure can inflate latency and hide the true bottleneck. When you compare transports, keep hardware, MTU, and CPU pinning consistent across runs so the data stays honest.
Approaches for Improving Architecture Performance
Use one repeatable checklist so teams can apply the same playbook across clusters and node pools:
- Pin I/O threads and IRQs to dedicated cores, and keep initiator and NIC queues NUMA-local.
- Size the queue depth and job count to the app, then confirm p99 stays inside the target under steady load.
- Separate storage traffic from east-west pod traffic when the cluster runs hot.
- Standardize MTU end-to-end, and track retransmits during load tests.
- Validate multipathing behavior under failover, not just in idle tests.
Architectural Comparison – Transport and Data Path Choices
This comparison focuses on what changes the most across NVMe-oF designs: transport characteristics, CPU cost, and operational complexity.
| Design choice | Typical benefit | Typical trade-off | Where it fits best |
|---|---|---|---|
| NVMe/TCP transport | Broad Ethernet compatibility, simpler rollout | Higher latency floor than RDMA in some setups | Most Kubernetes clusters, mixed workloads |
| NVMe/RDMA (RoCEv2) transport | Requires a disciplined CPU and hugepage setup | Fabric tuning, congestion control needs | Latency-sensitive tiers, specialized networks |
| Kernel-based target path | Familiar ops model | More context switching, higher CPU cost | Compatibility-driven environments |
| SPDK user-space target path | Lower overhead, high IOPS per core | Requires disciplined CPU and hugepage setup | High-density nodes, performance-focused clusters |
Simplyblock™ for NVMe-oF at Scale
Simplyblock™ implements Software-defined Block Storage with an NVMe-first approach and positions NVMe/TCP as a primary transport for high-performance storage on commodity Ethernet. It pairs that with SPDK-based, user-space, zero-copy design to improve throughput per core and reduce software overhead in the data path.
Simplyblock also targets day-2 control, not just peak benchmarks. It emphasizes multi-tenancy, QoS, and flexible deployment across hyper-converged, disaggregated, and hybrid Kubernetes environments, which helps teams keep storage behavior stable as node pools change.
Future Directions and Advancements in NVMe over Fabrics Architecture
NVMe-oF architecture continues to shift toward “Ethernet everywhere” rollouts, with NVMe/TCP as the broad baseline and RDMA as an optimization tier. Industry guidance also points to stronger standardization around scalable NVMe access over extended distances inside the data center.
Expect more attention on host CPU efficiency and offload paths. DPUs and IPUs can handle parts of the storage and network pipeline, which raises the value of designs that minimize copies and keep the hot path lean.
Related Terms
One-click references that teams review alongside NVMe over Fabrics Architecture.
- NVMe over Fabrics Transport Comparison
- NVMe over TCP Architecture
- NVMe-oF (NVMe over Fabrics)
- Persistent Storage for Kubernetes Databases
Questions and Answers
An NVMe-oF design is built from an NVMe-oF transport, a target that exports namespaces, and initiators that connect from hosts. The architecture choice is mostly about where you terminate the data path and how you isolate failure domains across the fabric. Use What is NVMe-oF as the baseline definition, then validate transport behavior with NVMe over Fabrics transport comparison.
NVMe/TCP optimizes for operational simplicity on Ethernet, RDMA targets lower latency but requires RDMA-capable networking, and NVMe/FC fits Fibre Channel environments with SAN-style isolation. The architectural impact is in network design, host CPU cost, and how you implement HA/multipath.
The first ceiling is often the fabric: oversubscription, microbursts, or packet-loss-driven retries can inflate p99 while NVMe media stays underutilized. Next is the host CPU, especially for TCP-based initiators/targets under high PPS. If scaling flattens, validate against storage network bottlenecks in distributed storage and interpret results with storage latency vs throughput.
NVMe-oF HA depends on correct discovery, path policy, and fast reconnect behavior under link or target loss. The key metric is not “does it fail over,” but how quickly p99 returns to normal after the event.
SPDK becomes “required” when kernel overhead or scheduling jitter prevents you from meeting p99 latency or CPU-per-IOPS targets at your desired scale. In those cases, a user-space target can keep the data plane predictable, but you must budget dedicated cores and NUMA locality. This decision ties directly into SPDK for NVMe over Fabrics and the SPDK vs kernel storage stack architecture tradeoff.