NVMe-oF Transport Comparison
Terms related to simplyblock
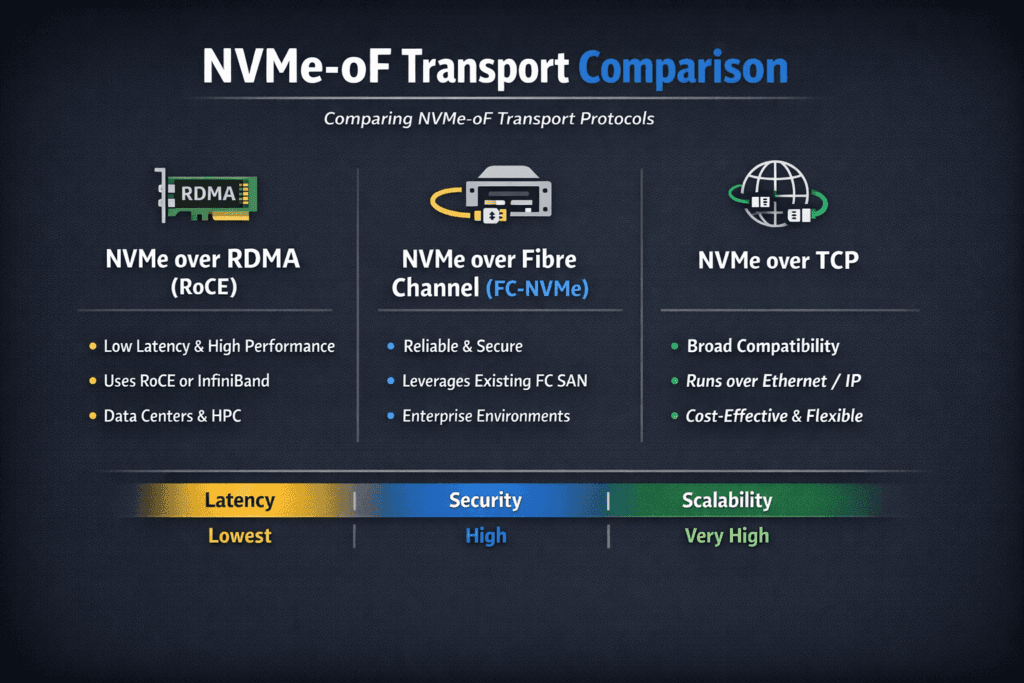
NVMe-oF transport comparison is the process of evaluating how NVMe over Fabrics behaves across different network transports, such as NVMe/TCP, NVMe/RDMA (RoCEv2 or InfiniBand), and NVMe/FC. Each transport changes latency, CPU load, throughput, failure modes, and day-2 operations. Teams use this comparison to pick the right fabric for each tier, then keep behavior consistent under real production load.
Executives usually want predictable app response times and fewer operational surprises. Platform and storage teams want clean automation, repeatable troubleshooting, and stable p99 latency when multiple tenants share the same storage.
What matters most when selecting an NVMe-oF transport
Start with the data path, not the transport label. The same fabric can look great in a lab and fall apart under contention if the host burns CPU on I/O handling or if queueing gets out of control.
User-space storage stacks help because they keep the hot path tight and reduce kernel overhead. That matters most when you run NVMe-oF on Ethernet, where CPU cycles and network noise can shift tail latency. It also matters for RDMA designs because a clean I/O path helps you keep latency steady as you scale queue depth and parallelism.
When you run Software-defined Block Storage, you also gain a practical advantage: you can standardize the storage control plane and still choose different transports per performance tier.
🚀 Reduce Fabric Sprawl While Comparing NVMe-oF Transports
Use Simplyblock to manage NVMe-oF transport choices through one Software-defined Block Storage control plane.
👉 Use Simplyblock to Standardize NVMe-oF Storage →
NVMe-oF Transport Comparison in Kubernetes Storage
Kubernetes Storage pushes storage choices into the platform roadmap. Clusters add nodes fast, workloads move, and teams expect storage to behave like an API. A transport that feels “fine” for static SAN hosts can become painful when you add rolling upgrades, node reboots, and frequent provisioning.
NVMe/TCP often aligns with Kubernetes operations because it rides on the same Ethernet domain that already supports the cluster. Teams can reuse the same network tooling, routing discipline, and observability. RDMA transports can deliver lower latency, but they demand stricter network design, tighter change control, and more specialized troubleshooting. NVMe/FC can fit organizations with deep SAN experience, yet it can split ownership between Kubernetes teams and SAN teams, which slows down incident response.
A solid transport decision for Kubernetes keeps three things stable: provisioning time, p99 latency under mixed load, and failure recovery behavior during node churn.
NVMe-oF Transport Comparison and NVMe/TCP
NVMe/TCP trades a small latency premium for broad deployability. It works on standard Ethernet, scales with commodity switching, and fits cloud-native ops patterns. The tradeoff shows up in CPU cost and jitter if you let storage I/O fight with other traffic or if hosts run short on reserved cores.
Teams get the best results with NVMe/TCP when they control CPU placement, keep node configs consistent, and apply QoS. Those steps reduce variance and protect tail latency, which matters more than peak IOPS for databases and multi-tenant platforms.
Measuring and Benchmarking Transport Performance
Benchmarking should mirror production. First, measure local NVMe performance to set a ceiling. Then, measure networked NVMe-oF with the same workload shape. Keep block size, read/write mix, job count, and queue depth consistent across runs.
Focus on sustained results, not short bursts. Track p50, p95, and p99 latency alongside IOPS and bandwidth. Run a contention test where a second workload drives load at the same time, because shared platforms break at tail latency before they break at throughput.
Approaches for Improving Transport Performance
Use a single, repeatable benchmark profile, and change one variable at a time. These steps usually deliver the biggest gains without turning tuning into a long science project.
- Reserve CPU cores for storage services, and keep IRQ and NIC queue settings consistent across nodes.
- Standardize MTU and congestion behavior across the fabric so every node follows the same rules.
- Set queue depth to meet latency goals instead of chasing peak IOPS.
- Enforce tenant-aware QoS so background jobs cannot crush latency-sensitive services.
Transport Decision Scorecard Table
The table below summarizes what teams typically evaluate when they compare NVMe-oF transports for cost, operations, and performance stability.
| Factor | NVMe/TCP (Ethernet) | NVMe/RDMA (RoCEv2 / IB) | NVMe/FC (Fibre Channel) |
|---|---|---|---|
| Hardware reach | Broad, standard NICs and switches | Tighter requirements, stricter fabric design | Dedicated SAN gear and ports |
| CPU efficiency | Good with a tight data path | Often strong due to RDMA offload | Depends on host stack and SAN design |
| Latency profile | Low, with some jitter risk under noise | Very low, sensitive to fabric correctness | Low and steady in SAN-first shops |
| Kubernetes fit | High, aligns with cluster Ethernet | Viable, but raises network complexity | Works well with mature SAN ops |
| Ops model | Familiar IP tooling, automation-friendly | More specialized troubleshooting | SAN governance, zoning, SAN workflows |
Simplyblock™ control points for consistent results
Simplyblock™ helps teams standardize Software-defined Block Storage while choosing the right transport for each tier. It focuses on an SPDK-based, user-space design to reduce overhead and keep the I/O path efficient. That approach supports NVMe/TCP environments where CPU noise and host variance can push up p99 latency.
For Kubernetes Storage, simplyblock supports multi-tenancy and QoS so teams can isolate workloads and keep behavior stable under mixed load. The platform also supports flexible layouts, including hyper-converged, disaggregated, and mixed deployments, so you can scale compute and storage in the way that matches each application tier.
The next wave of NVMe-oF transport improvements
Transport decisions will keep shifting toward operational simplicity and repeatable outcomes. Ethernet NVMe/TCP will gain ground as teams standardize on one network domain and demand consistent automation. RDMA transports will remain important for ultra-low-latency tiers, especially where teams can enforce strict fabric rules. SAN-based NVMe/FC will stay relevant in enterprises that value dedicated storage networks and established governance.
Expect more designs to use DPUs and IPUs to offload networking and storage work. Offload can reduce CPU jitter and help platforms hold steady p99 latency as tenant density rises.
Related Terms
Teams reference these pages when they compare NVMe-oF transports for Kubernetes Storage outcomes.
Questions and Answers
Pick based on the constraint you hit first: operational simplicity, lowest tail latency, or existing SAN investment. NVMe/TCP is easiest on standard Ethernet, NVMe/RDMA targets the lowest latency but needs RDMA-capable networking, and NVMe/FC fits Fibre Channel fabrics with SAN-style isolation. Start from the NVMe over Fabrics transport comparison and anchor the design in What is NVMe-oF.
CPU cost often separates transports more than raw bandwidth. NVMe/TCP can become CPU-bound under high PPS, while RDMA reduces host CPU by offloading more work to the NIC, and NVMe/FC shifts the model to FC HBAs and fabric semantics. The practical comparison is CPU-per-IOPS and p99 under your workload shape. Validate assumptions with NVMe over TCP CPU overhead and storage latency vs throughput.
NVMe/FC commonly maps to dual-fabric SAN patterns, while NVMe/TCP and NVMe/RDMA rely on IP redundancy and careful topology design to avoid shared-fate links. The “gotcha” is that IP fabrics can hide oversubscription and correlated failures unless you model boundaries explicitly.
All transports suffer from a bad fabric, but NVMe/TCP is often the most exposed because packet loss and queueing inflate tail latency quickly under high concurrency. RDMA can reduce CPU overhead, yet it still depends on clean loss characteristics and disciplined network design.
Run the same workload shape across transports: identical block size, read/write mix, queue depth, and multipath settings, then compare p95/p99 and CPU-per-IOPS. Also test degraded conditions like failover and sustained background traffic because that’s where transports diverge operationally. Use storage performance benchmarking and targeted fio NVMe over TCP benchmarking to keep results repeatable.