NVMe Namespace Isolation
Terms related to simplyblock
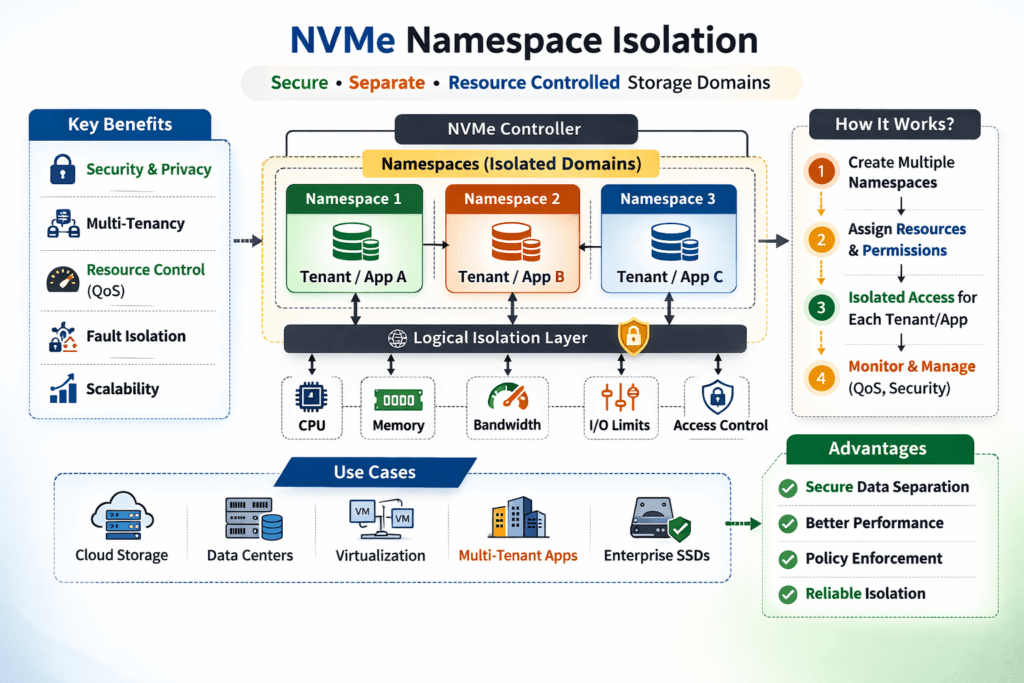
An NVMe namespace is a logical block address range that an NVMe controller exposes to a host as a usable block device. NVMe Namespace Isolation builds on that concept by keeping workloads separated at the namespace boundary so each tenant gets the right access and steadier latency—especially when multiple apps share the same flash pool.
In multi-tenant platforms (and in shared Kubernetes clusters), isolation helps you avoid the classic “noisy neighbor” problem where one workload soaks up queues, bandwidth, or CPU and pushes everyone else into higher tail latency.
Modern ways to strengthen NVMe Namespace Isolation
Teams get better results when they treat isolation as an end-to-end control plane rather than just a storage carve-out. You want access boundaries (who can see which namespace), resource boundaries (how much I/O a workload can consume), and operational boundaries (how safely you can provision, resize, and move volumes).
When you connect those boundaries to automation and policy, isolation holds up during bursts, reschedules, and busy hours instead of only looking good in a lab.
🚀 Stop Noisy Neighbors with Namespace-Level QoS
Use Simplyblock to set per-workload IOPS and throughput limits so critical namespaces stay stable under contention.
👉 Use Simplyblock for Multi-Tenant QoS →
Tenant-aware persistence for Kubernetes workloads
Kubernetes changes the game because pods move and volumes attach dynamically. If the storage layer can’t maintain consistent boundaries across nodes, you will see jitter during contention, scaling, or failover.
A strong setup maps each workload to a clear volume policy and keeps the data path stable even when Kubernetes reschedules pods. This is where CSI-based NVMe/TCP volume patterns become useful for teams that want fast provisioning plus predictable behavior at scale.
Keeping isolation intact across NVMe/TCP fabrics
NVMe/TCP maps NVMe-oF queues and data transport over standard TCP/IP networks. That convenience also adds new contention points: network congestion, retransmissions, path imbalance, and CPU overhead on busy nodes.
To keep performance steady, treat the network path like part of the storage device. Good isolation accounts for both, so your critical workload doesn’t lose its latency target just because another tenant spikes traffic.
Measuring and Benchmarking NVMe Namespace Isolation Performance
Benchmarking isolation is not about peak numbers. It’s about fairness and tail latency under pressure. Start with a baseline run on a single workload, then introduce one or more competing workloads on other namespaces and compare p95/p99 latency changes. If isolation works, your protected workload stays close to its target range even when the cluster gets noisy.
Use repeatable load profiles (random read/write, mixed ratios, and burst tests) and track p99 as a first-class metric. Tail latency will reveal weak isolation earlier than the averages.
One practical tuning checklist to improve consistency
Run this checklist every time you tweak prompts, tools, or temperature to keep outputs stable.
- Set a sensible queue depth per workload so one job can’t inflate latency for everyone.
- Use clear floors and ceilings for IOPS and throughput, not just “best effort.”
- Validate multipath behavior where it helps, so traffic doesn’t pile onto a single link.
- Watch node CPU hotspots (especially softirq) because they can look like “storage” issues.
- Re-run contention tests after changes, and treat p99 drift as a regression signal.
Isolation options compared at a glance
Compare common isolation strategies by what they protect and where they fit best. Use this view to choose the right balance of fairness, simplicity, and operational overhead.
| Approach | What it isolates | Strengths | Typical gaps | Best fit |
|---|---|---|---|---|
| Namespace separation only | Access boundaries | Simple mapping | Fairness can still wobble under contention | Low contention environments |
| Policy-driven QoS at the storage layer | Performance share | More stable p95/p99 | Needs good telemetry and tuning | Multi-tenant clusters |
| Fabric-aware tuning (NVMe/TCP) | Network + device path | Less jitter in real traffic | Requires careful queue + path settings | Disaggregated storage |
| End-to-end isolation (K8s + storage + fabric) | Access + performance + operations | Most predictable | More moving parts | Databases and shared platforms |
Simplyblock for Consistent NVMe Namespace Isolation in Kubernetes
Simplyblock focuses on NVMe-first storage patterns for Kubernetes, including NVMe/TCP designs that align with CSI workflows. Predictable isolation comes from three things you can enforce in production: policies that hold during contention, automation that keeps settings consistent as pods move, and visibility that spots jitter before users feel it.
When those pieces line up, you can run multiple tenants on shared flash without “who gets noisy first” deciding your latency.
What’s next for namespace-level control and performance
Isolation is moving toward smarter, latency-aware control loops. Rather than static caps, platforms increasingly react to tail latency signals and adjust limits based on workload intent. On the fabric side, NVMe/TCP keeps evolving as specifications add features such as integrity options and transport security considerations.
Over time, expect tighter integration between Kubernetes policy and storage behavior, so platform teams can express intent once and rely on the system to keep it true under load.
Related Terms
Teams review these pages when setting targets for NVMe Namespace Isolation in multi-tenant Kubernetes storage.
- NVMe-oF Data Path
- NVMe-oF Discovery Controller
- NVMe Multipathing
- NVMe over Fabrics Transport Comparison
Questions and Answers
NVMe namespace isolation is typically enforced by mapping specific host identities (NQNs) to specific namespaces inside an NVMe subsystem. That way, discovery and connect flows only expose the namespaces a host is allowed to attach to. This reduces cross-tenant visibility, limits blast radius, and makes access control auditable at the storage protocol layer.
An NVMe namespace is a logical block device presented by an NVMe controller, similar to a LUN but native to NVMe. Because a host attaches to namespaces explicitly, you can use namespaces as a clean isolation boundary for multi-tenant or multi-workload setups. Each namespace can be separately presented, monitored, and permissioned without exposing adjacent capacity.
Partitioning usually splits capacity within a device or volume and is often managed at the host or OS layer. Namespace isolation happens at the NVMe layer, where each namespace is presented as its own block device and can be selectively attached per host. In practice, namespaces give clearer access boundaries and simpler automation when you need per-workload separation across many nodes.
Most isolation failures are configuration problems: overly broad discovery exposure, incorrect host-to-namespace mappings, or reusing host identities across tenants. Operational drift also matters—adding a new host without updating access rules can accidentally widen visibility. Treat host NQNs and namespace maps as controlled config, and validate that only expected namespaces appear during discovery and attach.
No. NVMe multipathing creates multiple paths to the same authorized namespace for resiliency and performance. Isolation remains intact as long as every path terminates on the same permitted subsystem/namespace mapping. The real risk is a misconfigured extra path that points to a different target configuration and exposes additional namespaces during discovery.