Multi-Tenant NVMe Storage
Terms related to simplyblock
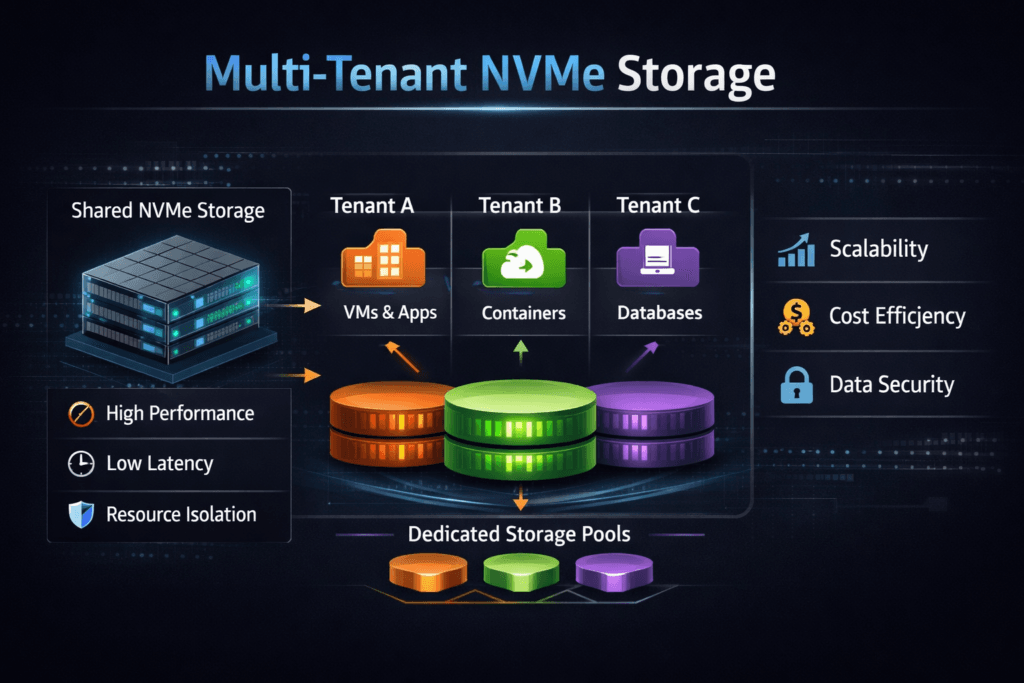
Multi-Tenant NVMe Storage is a shared NVMe-backed storage service that supports multiple tenants (teams, apps, or customers) while keeping data separation and steady performance. The storage layer enforces boundaries for capacity, IOPS, bandwidth, and latency so a “noisy neighbor” cannot take over the SSDs, CPU cores, or network links.
Executives usually want higher utilization and lower cost per workload. Platform owners want fewer incident tickets tied to p99 latency spikes. Storage teams focus on what causes jitter in shared systems: queue contention, uneven CPU scheduling, rebuild pressure, and bursty east–west traffic. A strong design combines policy-driven isolation with a fast data path. That’s where Software-defined Block Storage helps, because it can apply rules per tenant and per volume instead of treating everything as one pool. When you run Kubernetes Storage, you also need a model that survives pod movement, scaling, and node churn without manual tuning.
Noisy-Neighbor Control for Shared NVMe Pools
A multi-tenant storage service stays predictable only when it treats isolation as a first-class feature. Capacity quotas stop one tenant from consuming the pool. Performance controls keep burst workloads from pushing up latency for everyone else. Identity and encryption rules protect boundaries across tenants and environments.
The data path also matters. If the platform burns too many CPU cycles per I/O, it creates latency swings under load. A user-space path built on SPDK-style concepts can cut overhead by avoiding extra copies and context switches, which helps keep tail latency in check when several tenants spike at once. Teams that plan for DPUs/IPUs usually prioritize this efficiency because offloading only pays off when the software stack already runs lean.
🚀 Run Multi-Tenant NVMe Storage with QoS, Natively in Kubernetes
Use Simplyblock to enforce tenant isolation, control noisy neighbors, and keep p99 latency predictable.
👉 Use Simplyblock for Multi-Tenancy and QoS →
Multi-Tenant NVMe Storage for Kubernetes Storage
Kubernetes turns multi-tenancy into a daily reality. Namespaces, projects, and clusters share the same hardware, while workloads scale up and down without warning. A storage system must map tenant intent to real controls, then keep those controls in place even as pods move.
A practical approach ties StorageClasses to policy. One class can target databases with tight latency goals. Another class can serve backups with strict throughput caps. The platform team then sets per-tenant limits for capacity and performance, and the storage layer enforces them at the volume level. That model fits shared clusters, internal platform engineering teams, and SaaS environments where many product groups share one Kubernetes Storage stack.
Multi-Tenant NVMe Storage over NVMe/TCP Networks
NVMe/TCP extends NVMe over standard Ethernet using the TCP/IP stack. It fits multi-tenant environments because it scales with common switches, works across routed networks, and supports disaggregated designs where compute and storage scale independently. Many teams also like the operational model, since it aligns with existing network tooling and change control.
Under load, NVMe/TCP performance depends on CPU headroom, queue tuning, and traffic patterns. Multi-tenancy raises the stakes because one tenant can create bursts that inflate p99 latency for others. Strong QoS policies, careful queue management, and an efficient user-space fast path help keep performance stable while still letting tenants burst within defined limits. This approach also supports hybrid environments that mix hyper-converged and disaggregated layouts under one policy model.
Validating Tenant-Fair Performance and SLOs
Multi-tenant benchmarking should answer a tenant-fairness question: “What happens to Tenant B when Tenant A gets noisy?” Start with baselines per tenant, then add a controlled interference workload that reflects reality, such as backups, analytics scans, or log compaction.
Track IOPS, bandwidth, average latency, and p95/p99 latency per tenant, and correlate those metrics with CPU utilization and network counters on both initiators and targets. In Kubernetes, add the timings that affect app recovery: volume provision time, attach time, and reschedule recovery time. For databases, measure app-level signals like commit latency and timeouts, since those expose jitter faster than device stats alone.
Tuning Levers That Keep Latency Predictable
Most improvements come from reducing contention and limiting variability, not from chasing a single peak number. Use policy first, then tune placement and queues.
- Define per-volume QoS ceilings and, when needed, guaranteed minimums, so bursty tenants cannot starve others.
- Separate pools or failure domains when tenants need different durability, rebuild behavior, or latency targets.
- Tune queue depth by workload class, and keep it tight for latency-sensitive services.
- Align CPU and NUMA placement for the storage data plane to avoid cross-socket penalties.
- Throttle rebuild and rebalancing work so background activity does not hijack foreground latency.
Deployment Models Compared
The table below summarizes common patterns for multi-tenant NVMe environments, with emphasis on isolation strength and day-two operations.
| Model | Isolation Strength | Operational Effort | Typical Fit |
|---|---|---|---|
| Dedicated hardware per tenant | Very high | High | Regulated workloads, strict separation |
| Shared platform with soft limits | Medium | Medium | Best-effort mixed workloads |
| Policy-driven Software-defined Block Storage | High | Medium | Shared Kubernetes platforms, SaaS tiers |
| Disaggregated NVMe-oF pool with QoS | High | Medium | Elastic growth, large clusters |
| Hyper-converged nodes with guardrails | Medium–High | Low–Medium | Smaller footprints, cost focus |
Multi-Tenant NVMe Storage with Simplyblock™
Simplyblock™ focuses on predictable performance in shared environments by combining multi-tenancy controls with QoS and an SPDK-based, user-space architecture. That design targets CPU efficiency and stable tail latency when many tenants spike at the same time. Simplyblock also supports NVMe/TCP, which lets teams scale on standard Ethernet while keeping consistent policy enforcement.
Platform teams can deploy simplyblock in hyper-converged, disaggregated, or mixed modes, then apply per-tenant rules across those layouts. This operational model fits DBaaS, internal platforms, and shared Kubernetes clusters where reliability depends on keeping tenant impact contained.
What Changes Next in Tenant-Aware NVMe Platforms
Teams are pushing multi-tenant NVMe platforms toward tighter automation and lower CPU cost per I/O. More organizations will adopt DPUs and IPUs to offload parts of the data path and isolate traffic earlier.
Platform engineers are also tightening the link between Kubernetes intent and storage policy, so classes like “database,” “analytics,” and “backup” map to enforced limits by default. Finally, many teams are raising the bar on p99 and p999 targets because those numbers drive user experience and executive dashboards.
Related Terms
Teams often review these glossary pages alongside Multi-Tenant NVMe Storage.
Questions and Answers
Multi-tenant NVMe storage usually isolates tenants by mapping each tenant’s host identity (NQN) to specific NVMe namespaces inside an NVMe subsystem. Discovery and connect, then expose only the allowed namespaces, reducing cross-tenant visibility. This model scales better than host-side partitioning because access control lives at the storage protocol layer and can be audited and automated.
Noisy neighbor happens when one tenant’s bursty I/O consumes shared device queues, CPU cycles, or network buffers, pushing up other tenants’ tail latency. You detect it by correlating per-tenant p99 latency with shared resource signals like target CPU, queue occupancy, and retransmits. If throughput stays flat but p99 rises across tenants, you’re likely seeing queuing, not a bandwidth limit.
Performance isolation aims to keep one tenant from stealing IOPS, bandwidth, or latency budget. Controls typically include per-volume limits, fair scheduling, and background-work shaping so rebuilds or compaction don’t spike latency. In practice, the best indicator is stable p95/p99 latency under mixed tenant load, not peak IOPS in a single-tenant test. See performance isolation in multi-tenant storage for the core concept.
NVMe/TCP can be a strong fit because it disaggregates storage while preserving NVMe semantics, which helps with centralized policy and tenant mapping. The tradeoff is extra network and target-side processing, so you must tune queueing and parallelism carefully to protect tail latency. Multi-tenant designs usually prefer predictable per-tenant limits over maximizing single-tenant throughput.
A solid design includes strict identity-to-volume mapping, tenant-aware QoS, and safe discovery so hosts only see what they should. It also needs observability for per-tenant latency and throttling events, plus operational guardrails to prevent config drift. Many teams start from a reference multi-tenant storage architecture and then validate with mixed-workload tests that match production concurrency.