CSI Volume Lifecycle
Terms related to simplyblock
CSI Volume Lifecycle describes how a CSI driver moves a volume through its full run in Kubernetes: create, attach, stage, mount, expand, snapshot, unmount, detach, and delete. Each step affects how fast a PersistentVolumeClaim (PVC) becomes usable, how cleanly pods move during node drains, and how often stateful apps hit restart delays. The CSI spec defines the required calls and behavior, so driver design and backend behavior both shape real-world results.
Platform leaders usually care about lifecycle time because it sets the floor for deployment speed and recovery time. DevOps teams see lifecycle issues as pods stuck in ContainerCreating, PVCs stuck in Pending, or long drain windows during upgrades.
Cutting Control-Plane Time with Kubernetes-First Storage
Lifecycle slowdowns often start in the control plane, not in the data path. A backend may deliver high IOPS while still taking too long to provision, attach, or mount under churn. Kubernetes also retries aggressively, so a small delay can turn into a queue during rollouts.
Kubernetes-aware Software-defined Block Storage helps by keeping provisioning logic close to Kubernetes patterns, exposing clear storage classes, and reducing extra coordination steps. When the data path also uses a user-space design built around SPDK concepts, the system can save CPU cycles and keep latency steadier during bursts.
🚀 Install a CSI Driver That Keeps Volume Operations Stable
Use Simplyblock to reduce attach/mount retries and keep node drains under control.
👉 Install Simplyblock CSI →
CSI Volume Lifecycle in Kubernetes Storage
In Kubernetes Storage, the lifecycle starts when a PVC references a StorageClass and ends when Kubernetes reports the volume ready, and the pod mounts it. Kubernetes binds the claim to a PV, schedules the pod, and triggers the CSI driver to make the block device available on the target node. Kubernetes then relies on the node plugin to format (when needed), stage, and publish the volume to the pod path.
This flow breaks down most often when topology rules do not line up, when stale attachments linger after a node loss, or when the node image drifts and mount behavior changes across pools. Topology-aware provisioning reduces surprises by placing data where Kubernetes plans to run the workload.
NVMe/TCP Effects on Pod Reconnect and Mount Times
NVMe/TCP matters because it can shorten reconnect time when pods move. It carries NVMe-oF commands over standard TCP/IP networks, which fits common Ethernet designs and avoids specialized fabrics in many clusters.
From a lifecycle view, focus on three moments: initial connect, reconnect after reschedule, and cleanup after teardown. Fast reconnect keeps stateful rollouts smooth. Clean cleanup prevents attachment conflicts that block scheduling in busy clusters.
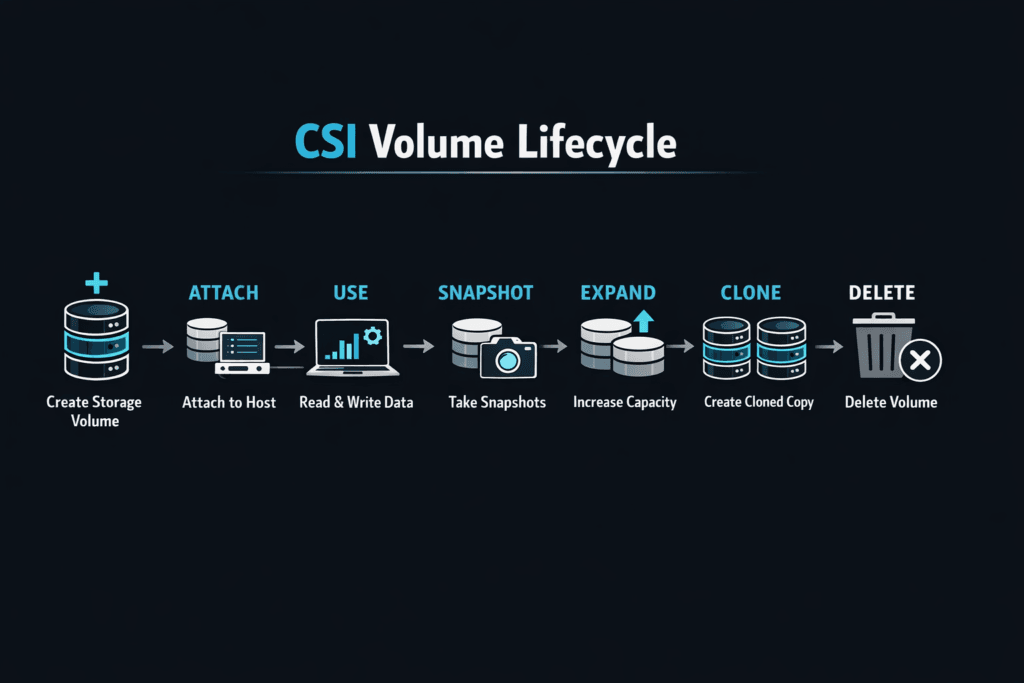
Measuring and Benchmarking CSI Volume Lifecycle Performance
Measuring and Benchmarking CSI Volume Lifecycle Performance works best when you track time-to-ready metrics, then tie them to Kubernetes events and CSI logs. Start with these clocks: PVC create to Bound, pod schedule to attach complete, attach to mount complete, and pod deletes to detach complete. Those numbers tell you whether delays come from provisioning, attachment, node publish, or teardown.
Pair lifecycle tests with steady-state I/O tests. fio can show throughput and latency, but churn tests show how storage behaves during drains, rolling updates, and autoscaling. When p99 mount time spikes during upgrades, the lifecycle path needs work, even if the data path looks fast.
Approaches for Improving CSI Volume Lifecycle Performance
Use the steps below to cut retries, shorten drains, and keep Kubernetes Storage predictable:
- Standardize StorageClass settings so provisioning follows one clear path across environments.
- Use topology-aware provisioning so zones, racks, and node pools match pod placement rules.
- Tune drain and rollout settings so the cluster avoids detach storms during upgrades.
- Instrument CSI RPC timings and correlate them with PVC and pod events to find the slow step.
- Apply multi-tenant QoS so one team’s churn does not delay another team’s attaches and mounts.
How Storage Designs Handle Lifecycle Churn
The table below shows where lifecycle behavior often differs across storage approaches that teams use as a SAN alternative.
| Operational area | Traditional SAN-style platform | Kubernetes-first software-defined design |
|---|---|---|
| Provisioning during deploy bursts | Often queues on central controllers | Scales out with cluster demand |
| Attach/detach during node churn | Higher risk of stale state | Faster reconciliation with CSI patterns |
| Reschedule reconnect time | Can run long during rollouts | Often recovers faster on pod moves |
| CPU cost under load | Higher overhead per I/O | Lower overhead with user-space options |
| Fit for NVMe/TCP | Possible, not always tuned | Common transport choice |
Consistent CSI Volume Operations with Simplyblock™
Simplyblock™ targets predictable Kubernetes Storage by combining NVMe/TCP transport with an SPDK-based, user-space, zero-copy style data path. That design can lower CPU cost per I/O and reduce latency swing when lifecycle events overlap with heavy traffic.
Simplyblock also supports topology-aware CSI behavior, plus multi-tenancy and QoS controls that help shared clusters stay fair under churn. When teams run mixed workloads, those controls keep volume operations consistent and protect critical services from noisy neighbors.
What’s Next for CSI Automation and Stateful Ops
Teams want faster recovery with fewer moving parts. Expect more policy-driven automation around cloning, snapshots, and resize flows, plus better observability that surfaces p95 and p99 lifecycle time by StorageClass.
More platforms will also lean on DPUs/IPUs to offload work from host CPUs, especially in dense clusters that run many stateful pods.
Related Terms
Teams often review these glossary pages alongside the CSI Volume Lifecycle.
- CSI NodePublishVolume Lifecycle
- Kubernetes NodeUnpublishVolume
- CSI Ephemeral Volumes
- Kubernetes Volume Plugin (in-tree vs CSI)
Questions and Answers
In Kubernetes, the CSI lifecycle typically flows through provision, attach, stage, publish, and finally unpublish/unmount during teardown. Provisioning is driven by the control plane and the CSI driver backend, while node-side steps handle device discovery, formatting, and mounting into the pod path. When something stalls, mapping the error to the phase tells you whether to inspect controller logs or kubelet/node plugin behavior.
ControllerPublish/Unpublish is the “make the volume available to this node” step, often involving attach semantics or access checks. NodeStage prepares the volume on the node (device setup, filesystem, global mount), and NodePublish bind-mounts it into the pod’s target path. If attach succeeds but pods still fail, the issue is usually in staging/publishing, such as filesystem errors, missing binaries, or permission constraints at the node level.
Most ContainerCreating volume stalls are Node-side and happen during publish/unpublish transitions, not during provisioning. Look for repeated mount attempts, timeouts, and “already mounted” or “device busy” patterns that point to cleanup drift. The fastest way to narrow it down is to align kubelet events with the CSI NodePublishVolume lifecycle so you can see whether the failure is staging, publishing, or teardown after a restart.
Snapshots and clones shift the “source of truth” earlier in the flow: the controller must create snapshot content or clone metadata before a new volume becomes available for attach and mount. Expansion adds coordination between controller-side resize and node-side filesystem growth, and failures can appear as a volume that is attached but not reflecting the new size in the pod. Always validate both the Kubernetes objects and backend state when advanced workflows are involved.
Topology-aware CSI influences where a pod can run because the volume may only be accessible in specific zones, racks, or failure domains. That means the scheduler’s placement decision becomes part of the lifecycle: a PVC can be bound, but a pod can still remain Pending if the chosen nodes can’t satisfy topology constraints. Understanding the CSI architecture helps here because it ties together scheduler hints, controller provisioning decisions, and the node-side mount path.