CSI Snapshot Architecture
Terms related to simplyblock
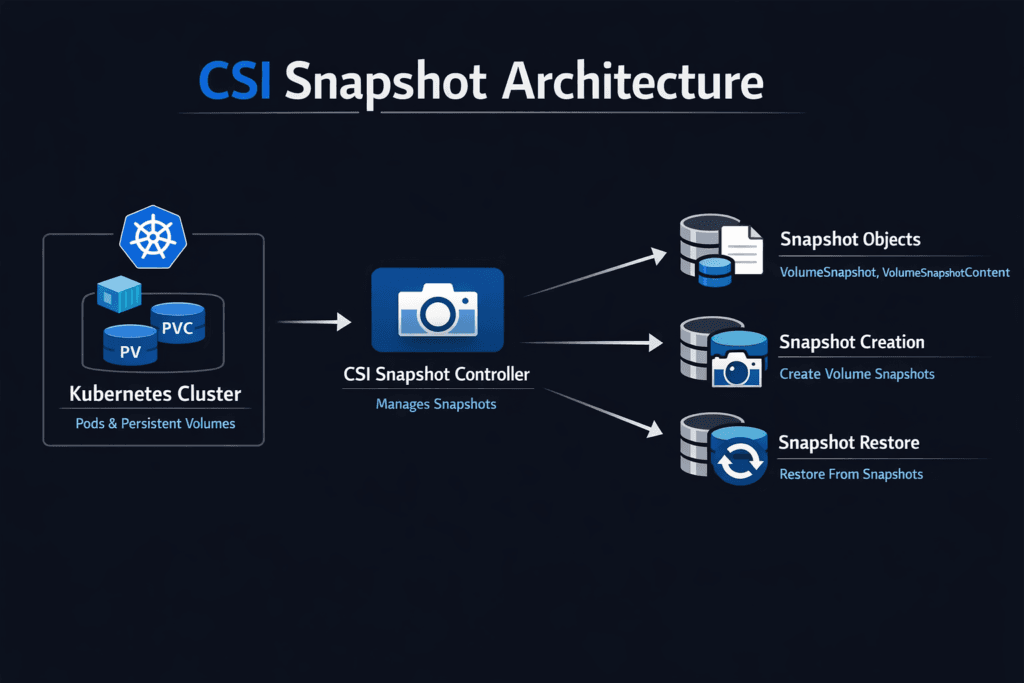
CSI Snapshot Architecture is the Kubernetes design that turns a “snapshot this PVC” request into a real snapshot in your storage backend. It connects Kubernetes snapshot objects (like VolumeSnapshot) to the snapshot controller and the CSI driver logic that creates, deletes, and restores snapshots.
This matters because snapshots power rollbacks, backups, cloning, and recovery drills. When the architecture is clean, teams restore faster and avoid “stuck snapshot” surprises during incidents.
Optimizing CSI Snapshot Architecture with Modern Solutions
In modern clusters, snapshot workflows work best when you keep them consistent and boring. That means stable versions of the snapshot CRDs, a healthy snapshot controller, and a CSI driver setup that matches your Kubernetes version.
Teams also win when they standardize snapshot classes. A small set of snapshot profiles (for example: “fast rollback” and “long retention”) reduces drift and makes restores easier to run across many teams.
🚀 Build Faster Rollback and Recovery with CSI Snapshot Workflows
Use Simplyblock to design repeatable snapshot-to-restore paths for stateful apps in Kubernetes.
👉 Use Simplyblock Snapshots & Clones Concepts →
CSI Snapshot Architecture in Kubernetes Storage
Kubernetes snapshots follow an API-driven flow. A user creates a snapshot object that points to a PVC and a snapshot class. The snapshot controller watches these objects, binds content, and manages lifecycle state. The CSI driver then performs the actual snapshot work in the backend.
When everything lines up, teams can build repeatable workflows: snapshot before a risky change, restore if needed, and move on. When the chain breaks, restores become slow and manual.
How snapshot workflows behave on NVMe/TCP
NVMe/TCP changes the transport path, not the snapshot API. Snapshot speed mostly depends on how the backend implements snapshots. Many modern backends use copy-on-write style behavior, which can make snapshot creation fast because the system avoids copying all blocks up front.
The practical goal is simple: fast snapshot creation and fast restore-to-PVC time, even when the cluster runs hot.
Measuring and Benchmarking CSI Snapshot Architecture Performance
Benchmark snapshots like a recovery feature, not a marketing number. Track the end-to-end time from “I applied the snapshot object” to “the snapshot is ready,” then measure restore time to a new PVC that a pod can mount.
Also, track what happens during pressure. Heavy writes, pod reschedules, or node churn often expose weak snapshot paths. p95 and p99 timing tells you more than averages.
Approaches for Improving CSI Snapshot Architecture Performance
- Keep your snapshot classes limited and consistent so teams don’t create one-off policies that drift over time.
- Test restore speed under real load, not only in quiet windows.
- Use tight retention rules so you don’t pile up snapshots and slow down cleanup later.
- Choose a storage backend that supports fast snapshot mechanics for frequent rollback and clone use cases.
- Run a scheduled restore drill that mounts a restored PVC and checks app health signals.
Snapshot designs compared at a glance
Use this table to match snapshot behavior to your restore goals. It helps you choose the best tradeoff between speed, safety, and ops effort.
| Snapshot style | What you get | Best for | Watch-outs |
|---|---|---|---|
| Full copy | Simple mental model | Small volumes, rare snapshots | Slow create, high space use |
| Copy-on-write | Fast create and rollback | Frequent snapshots, quick restore | Needs good retention hygiene |
| App-consistent | Cleaner DB recovery | Databases with strict consistency | Needs coordination/hooks |
| Policy-based classes | Repeatable behavior | Shared clusters | Needs governance and naming discipline |
Simplyblock snapshot workflows for Kubernetes teams
Simplyblock supports Kubernetes snapshot workflows through its CSI-based storage model and documents snapshotting as part of day-2 operations. The key value for platform teams is repeatability: snapshots that reach “ready” quickly and restores that come up the same way during node churn and busy write load.
When you align snapshot classes, retention rules, and restore drills, you turn snapshots into a routine platform feature instead of a last-minute rescue tool.
Future Directions and Advancements in CSI Snapshot Architecture
Snapshots are moving beyond single-volume workflows. Multi-volume snapshot ideas (group snapshots) aim to capture consistent points across several PVCs for apps that split data and logs. Teams also push for clearer status signals and safer cleanup so snapshots behave well during upgrades.
As these features mature, platform teams will spend less time debugging controllers and more time improving recovery outcomes.
Related Terms
Teams review these pages when setting targets for CSI Snapshot Architecture in Kubernetes.
Questions and Answers
CSI snapshot architecture connects Kubernetes VolumeSnapshot, VolumeSnapshotClass, and VolumeSnapshotContent objects to the driver’s snapshot RPCs and backend snapshot primitives. The controller watches the CRDs, resolves the source PVC/PV, then triggers snapshot create/delete and updates status fields so restores and clones can be automated. This is the control-plane path behind volume snapshotting.
The snapshot-controller coordinates Kubernetes snapshot objects and enforces the lifecycle/state machine, while the external-snapshotter sidecar is typically deployed with the CSI driver to call the driver’s snapshot RPC endpoint. One controller can serve many drivers, but each driver needs its sidecar to translate CRD events into CSI calls and to report ready-to-use status back to Kubernetes.
Snapshot requests start in the control plane, but the actual point-in-time capture happens in the storage data plane. By default, most CSI snapshots are crash-consistent (good for many apps), while app-consistent snapshots require coordinating filesystem flush and application quiesce hooks. If you see “ReadyToUse=false” delays, it’s usually backend snapshot creation time or controller reconciliation, not pod I/O blocking.
Restores typically provision a new PVC from an existing VolumeSnapshot, which binds to a VolumeSnapshotContent Referencing the backend snapshot handle. Clones may reuse the same snapshot handle and then diverge via copy-on-write, depending on the driver. Debugging tip: if restore PVCs hang, check whether the snapshot content is bound, has a valid handle, and the driver advertises snapshot support.
Treat snapshots as a chain: snapshot-controller reconciliation, external-snapshotter CSI RPC, then backend snapshot execution. If CRDs don’t progress, it’s usually controller permissions or class parameters; if RPC errors appear, it’s driver endpoint or credentials; if backend times out, it’s storage health. This separation is easiest to reason about using the CSI driver vs sidecar as the mental model.