Cross-Zone Replication
Terms related to simplyblock
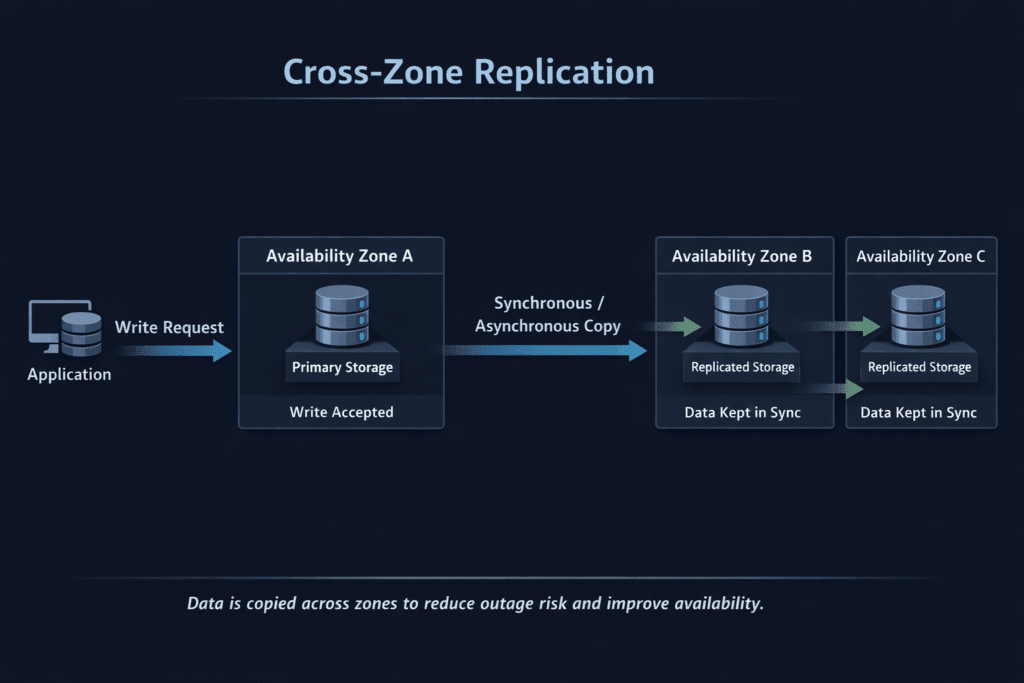
Cross-zone replication copies data to another availability zone in the same region, so a single-zone outage doesn’t automatically take your stateful service down. It sits between two extremes: zonal-only storage (simple, but fragile to zonal loss) and cross-region DR (strong separation, but slower and heavier).
The best choice depends on what you promise the business: how much data you can lose (RPO) and how fast you must recover (RTO).
Cross-Zone Replication vs Cross-Cluster Replication
Cross-zone replication focuses on zone failures inside one region. Cross-cluster replication usually means a bigger boundary: a second Kubernetes cluster, a second site, or a separate cloud footprint. That bigger boundary can help with wider disasters, but it adds more moving parts and longer runbooks.
If your main risk is “one AZ goes dark,” cross-zone designs often fit best. If your risk looks more like “the whole cluster is unusable,” cross-cluster planning becomes the safer bet.
🚀 Reduce Cross-Zone Replication Downtime, Natively in Kubernetes
Use Simplyblock to cut RPO and RTO with fast recovery workflows—so stateful apps stay recoverable across availability zones without slowing production writes.
👉 Use Simplyblock for RPO/RTO Reduction →
Kubernetes behavior that can make or break a failover
Kubernetes turns storage choices into scheduling constraints. With zonal volumes, the Pod must land in the same zone, or the attach fails. That mismatch often appears during drains, node churn, or capacity pressure.
Topology-aware volume provisioning helps by delaying provisioning until the scheduler picks a node (“wait for first consumer”), which reduces wrong-zone volume creation. CSI topology support adds another layer by letting drivers expose topology hints and constraints during provisioning.
Cross-Zone Replication Choices – Synchronous vs Asynchronous
Synchronous replication confirms writes across zones, which can drive data loss toward zero in the best case. It can also add write latency because the system waits for remote confirmation.
Asynchronous replication ships updates after the primary write completes. It usually keeps write latency lower, but it accepts lag, so your RPO becomes “how far behind the replica can get during peak write bursts.”
NVMe/TCP considerations for multi-zone protection
NVMe/TCP can deliver strong latency over standard Ethernet, yet replication traffic can still push p99 up when it shares the same links and queues as production I/O. Keep the hot path stable by reserving bandwidth for foreground writes and capping background flows like resync and restore.
Topology-aware placement still matters here. When a workload doesn’t need multi-zone protection, avoid cross-zone hops and keep the I/O path short. Validate the design with p95/p99 measurements during steady load and during a drill that forces a reschedule and reattach.
What to measure so the comparison stays honest
A clean benchmark hides the hard parts. Real systems fail during peak load, not quiet hours.
Track replication lag (or sync commit time), p95/p99 write latency while protection runs, time to reschedule and reattach during drains, and restore time for your largest realistic dataset. RPO and RTO keep the project grounded because they define what “acceptable” means during a real outage.
Decision framework for picking the right model
- Pick synchronous replication when you must minimize data loss, and you can accept higher write latency under load.
- Pick asynchronous replication when you want stable writes,s and you can tolerate a small, monitored lag window.
- Use snapshot + restore when rollback and clean recovery points matter more than instant failover.
- Move to cross-cluster patterns when you must survive a full cluster outage or need a larger blast radius than one region.
- Prove the choice with drills, then tune until tail latency stays stable during protection and recovery.
Replication Options Compared Across Availability Zones
Compare the options by what you must guarantee in a real outage: data loss window, recovery speed, and the day-2 work needed to keep it reliable. Also account for the hidden cost—some designs add write latency, while others add operational overhead.
| Approach | Typical goal | Data-loss window | Latency impact | Ops load | Best fit |
|---|---|---|---|---|---|
| Zonal only | Lowest cost/complexity | High during zonal outage | Low | Low | Non-critical tiers |
| Cross-zone synchronous | Stay available with near-zero loss | Near-zero possible | Higher under writes | Medium | Strict RPO in one region |
| Cross-zone asynchronous | Protect without slowing writes | Low to medium (lag) | Lower | Medium | Write-heavy apps with clear RPO |
| Snapshot + restore | Rollback and recovery points | Medium | Low steady-state | Medium | Rollbacks, corruption recovery |
| Cross-cluster replication | Separate blast radius | Varies | Varies | Higher | Full-cluster failure planning |
Cross-Zone Replication with Simplyblock for Low RPO and Fast Recovery
Simplyblock positions multi-zone protection around recovery outcomes: reduce RPO and cut RTO with fast recovery workflows that rebuild quickly after major failures. Its backup/DR use case also focuses on faster restores and lower downtime, which fits the “recover cleanly from a zonal event” goal.
If your priority is steady performance, validate that replication and restore activity won’t steal the hot path. Then lock in a drill cadence that proves your RTO in practice.
What’s Next – Policy-Driven Replication and Faster Drills
Policy-driven controls are becoming the default: set an RPO/RTO target, then let the platform manage snapshot cadence, replication rate, and retention. Cleaner consistency across multiple volumes also matters more each year, since most real apps span more than one disk.
Safer automation for failover testing is rising in priority, because frequent drills catch gaps early without risking production data. Expect more app-aware consistency groups and orchestration hooks that restore services in the right order and keep recovery predictable.
Related Terms
These glossary pages pair well with Cross-Zone Replication when you compare replication modes, recovery targets, and rollback workflows:
- Storage High Availability
- RPO (Recovery Point Objective)
- CSI Snapshot Controller
- Data Replication
- Region vs Availability Zone
Questions and Answers
Cross-zone replication keeps storage volumes synchronized across availability zones, ensuring high availability and fault tolerance. It’s essential for stateful workloads that require resiliency against zone failures.
Yes, NVMe over TCP works well in multi-zone environments. It enables fast, remote block storage replication across zones using standard Ethernet without requiring specialized hardware.
It protects against zone outages, seamless failover, and improved uptime. When paired with software-defined storage, it simplifies data redundancy across fault domains without vendor lock-in.
There may be slight latency due to inter-zone traffic, but smart caching and fast protocols like NVMe/TCP help reduce its impact. Most applications benefit from the increased reliability.
Yes, by enabling active-active setups and avoiding idle standby resources, it supports cloud cost optimization. It also reduces the risk of downtime penalties tied to SLA breaches.