CSI Topology Awareness
Terms related to simplyblock
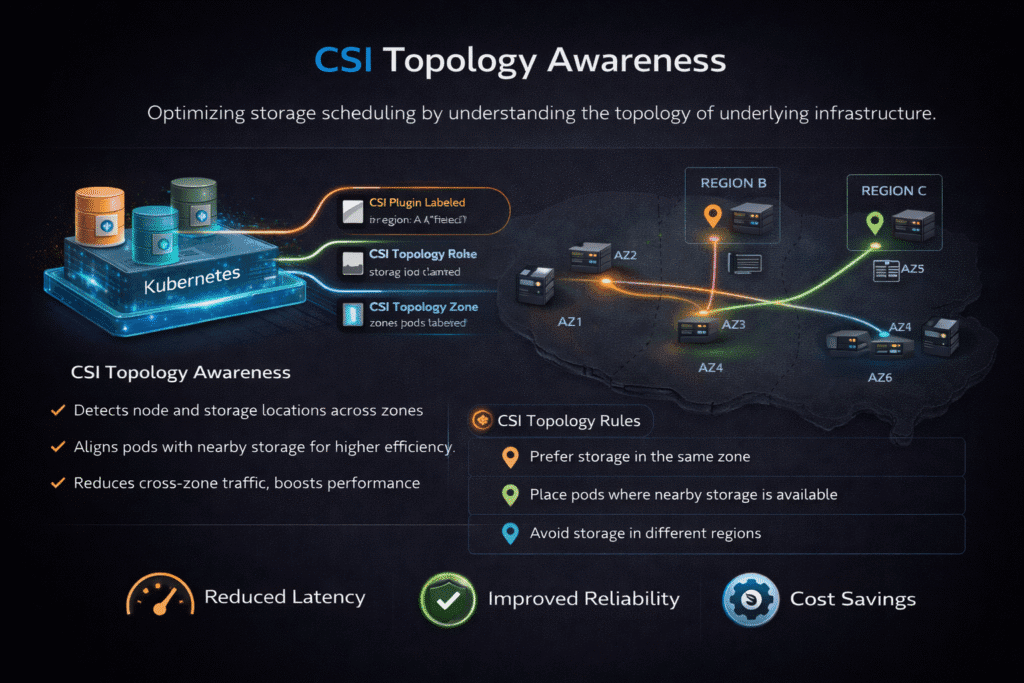
CSI Topology Awareness is the Kubernetes and Container Storage Interface pattern that keeps volume provisioning and attachment aligned with real infrastructure boundaries like zones, racks, or node pools. It helps the scheduler and the storage driver agree on where a PersistentVolume should live so a Pod does not land in one zone while its volume lands in another.
In practice, CSI Topology Awareness shows up when you use a StorageClass with topology rules and a binding mode that waits for the scheduler’s placement choice. Teams rely on it to reduce cross-zone traffic, lower tail latency, and avoid costly reschedules when stateful Pods move.
For organizations standardizing Software-defined Block Storage for Kubernetes Storage, topology awareness becomes a control point because it shapes cost, availability, and p99 I/O behavior.
Turning Topology Signals into Reliable Outcomes
Topology-aware storage fails most often due to simple mismatches. Node labels drift. Zones differ between node pools. The storage driver reports topology keys that do not match cluster conventions. These issues can leave Pods Pending, cause mount failures, or create volumes in the wrong fault domain.
Daily outcomes depend on two objects: the StorageClass and the PVC/PV lifecycle. When those two align with cluster topology, the scheduler can place a Pod and the driver can provision the right volume on the first try. When they do not align, teams lose time in retries and manual cleanup.
🚀 Put CSI Topology Awareness Into Production with a Helm-Deployed CSI Driver
Use Simplyblock to install the CSI driver, align StorageClass behavior to topology, and keep NVMe/TCP volumes in-zone.
👉 Install Simplyblock CSI for Topology-Aware Provisioning →
CSI Topology Awareness in Kubernetes Storage
CSI Topology Awareness depends on a clean handshake between scheduler intent and storage placement. Kubernetes can delay binding until it knows where the Pod will run, and then it can request a volume that matches that topology.
Teams often pair topology settings with policies that steer Pods, such as node labels, affinity rules, and failure-domain spread. This is where scheduling concepts connect directly to storage. If the cluster spreads replicas across zones but the storage layer stays “blind,” you can still end up with cross-zone I/O and poor recovery behavior.
A practical goal is simple: a stateful Pod should start quickly, attach the volume on the first attempt, and keep stable latency after reschedules and rollouts.
CSI Topology Awareness and NVMe/TCP Fabrics
Topology rules matter more as performance increases. When you run NVMe/TCP over standard Ethernet, you often gain flexibility through disaggregated node pools and multi-zone growth while keeping a fast I/O path. That same flexibility raises the risk of wrong placement, because a topology miss can push traffic across zones and crush p99 latency.
A strong approach combines NVMe/TCP with a storage platform that treats topology as a first-class policy input and still keeps throughput high. It also helps to reduce CPU overhead in the data path, because storage traffic can compete with application cores under heavy load.
User-space I/O design and zero-copy behavior can improve CPU efficiency and reduce jitter, especially when many workloads share the same cluster.
Measuring CSI Topology Awareness at Cluster Scale
You can measure CSI Topology Awareness without complex tooling if you define clear signals and track them consistently.
A well-behaved cluster shows these outcomes:
Pod startup time stays consistent for stateful workloads.
Provisioning time stays stable from PVC creation to PV bound.
Attach and mount time stays predictable after reschedules and drains.
Tail latency stays under control at p95 and p99, even during maintenance.
When problems appear, they often show up first as stuck PVCs, repeated attach failures, or sudden increases in cross-zone network traffic. Those signals usually point to label drift, a mismatch in topology keys, or a StorageClass that binds volumes too early.
Practical Steps That Improve Placement Consistency
Use the checklist below when topology issues show up in incident reviews. It focuses on actions that reduce reschedules and keep storage costs predictable.
- Validate node labels for zone and failure domain, and lock them with an admission policy.
- Use a StorageClass that delays binding until scheduling chooses a node when topology constraints matter.
- Set allowed topologies only when labels remain stable across upgrades and node pool changes.
- Watch for stuck PVCs and attach failures, then correlate them with recent label changes or node pool edits.
- Track cross-zone traffic as a cost and latency signal, not as background noise.
Topology Models and Scheduling Trade-Offs
The table below summarizes common deployment patterns and the trade-offs that matter when you care about predictable Kubernetes Storage behavior.
| Deployment pattern | Placement signal | Typical failure mode | Best fit |
|---|---|---|---|
| Immediate binding with no topology hints | Storage chooses first, scheduler reacts later | Pod lands where volume cannot attach | Small single-zone clusters |
| Scheduler-aligned topology-aware binding | Scheduler and CSI cooperate on zone or rack | Label drift breaks constraints | Multi-zone stateful services |
| App-only scheduling rules with no CSI topology | Pod rules exist, storage remains blind | Cross-zone I/O increases quietly | Stateless-first clusters |
Predictable Topology-Aware Storage with Simplyblock™
Simplyblock™ targets predictable behavior by combining a Kubernetes-native control plane with Software-defined Block Storage that runs on baremetal or cloud instances. It supports NVMe/TCP for broad Ethernet compatibility and aligns data placement with failure domains so teams can scale without turning every storage issue into a scheduling fire drill.
That matters for multi-tenant platforms and internal developer platforms, because topology mistakes show up as both cost spikes and SLO misses. When you pair topology-aware placement with QoS, you also reduce noisy-neighbor damage and keep the storage path steady under load.
CSI Topology Awareness – What Comes Next
Topology awareness keeps evolving toward stronger policy control and better automation. Many teams now treat topology as code, validate labels continuously, and tie placement rules to storage-side QoS. Offload via DPUs and IPUs also becomes more common because it can protect the host CPU and reduce latency jitter as cluster density grows.
The direction stays consistent: keep volumes in the right fault domain, keep the data path efficient, and keep reschedules predictable.
Related Terms
Teams often review these glossary pages alongside CSI Topology Awareness when they standardize Kubernetes Storage and Software-defined Block Storage on NVMe/TCP.
Block Storage CSI
Dynamic Provisioning in Kubernetes
Storage Affinity in Kubernetes
Cross-Zone Replication
Questions and Answers
In distributed Kubernetes clusters, CSI topology awareness ensures persistent volumes are scheduled within the same failure domain as the pods that use them. This minimizes cross-zone latency, improves fault tolerance, and is key to maintaining RTO and RPO targets in modern stateful applications.
By honoring zone or region constraints, CSI topology-aware provisioning ensures volumes are accessible and resilient—even during partial infrastructure failures. This design helps maintain data availability for services like databases on Kubernetes or multi-AZ deployments.
Absolutely. With topology-aware scheduling, Kubernetes can co-locate workloads with NVMe-backed volumes using NVMe over TCP. This reduces access latency, avoids unnecessary traffic between zones, and helps applications achieve peak IOPS.
Yes. Combining CSI topology awareness with multi-tenant encryption allows teams to securely isolate volumes by zone or workload. It also enables infrastructure operators to enforce tenancy boundaries and optimize resource placement across shared clusters.
Simplyblock supports topology-aware volume provisioning natively. By defining topology keys in your StorageClass, Kubernetes can align pods and persistent volumes correctly. For implementation steps, refer to the Simplyblock CSI driver documentation and deployment guides.