Database Branching
Terms related to simplyblock
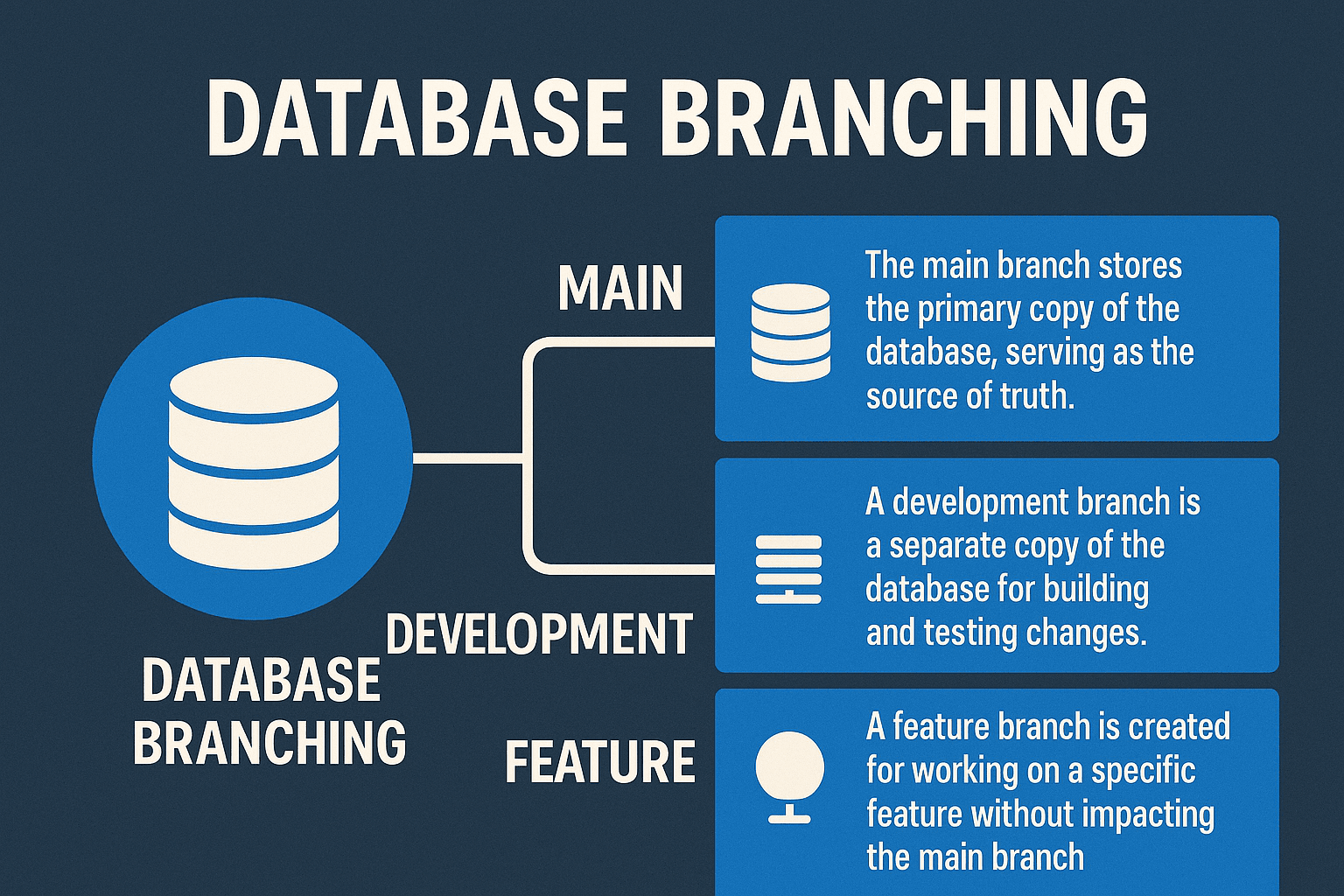
Database branching is a version control method applied to databases. It allows developers and DevOps teams to create isolated environments—called branches—for schema changes, data transformations, and testing workflows. Each branch functions like a Git branch: it’s a logical clone of a database schema and, optionally, data. By separating changes into branches, production environments remain stable while developers iterate safely.
This approach is central to CI/CD workflows. Instead of deploying changes directly to staging or production, teams can validate and test everything inside isolated database branches. Platforms like simplyblock for PostgreSQL make this possible by supporting instant volume cloning. This concept is rooted in branching in version control, where isolated development environments are created for safe experimentation.
How Database Branching Works
Database branching uses snapshot and copy-on-write techniques to create fast, storage-efficient replicas. These clones operate as full environments but are built without duplicating all data, minimizing overhead.
When a developer creates a branch, it includes the current schema and optionally real or masked data. Changes can then be made independently. Once validated, branches can be merged, discarded, or compared using version control principles.
In Kubernetes environments, this is often managed through Kubernetes Storage integrations for dynamic volume provisioning. With simplyblock’s CSI driver, these database volumes can be instantly cloned using copy-on-write, enabling sub-second branch creation while maintaining storage efficiency.
🧪 Need faster test environments without provisioning delays?
Deliver instant database branching across virtualized Kubernetes clusters using simplyblock’s ultra-fast storage backend.
Get started with KubeVirt Storage → 🚀
Benefits of Database Branching
Database branching introduces new development agility. Here are some tangible benefits:
- Parallel Development: Isolated environments for every developer or feature.
- Risk-Free Testing: Validate migrations or data logic safely before production.
- CI/CD Compatibility: Every build or PR can trigger a unique test branch.
- Efficient Storage: With thin provisioning, multiple branches use minimal physical storage.
- Version Control for Data: Schema and data changes are easily tracked, compared, and merged.
These benefits align with use cases such as database branching and Databases-as-a-Service.
Database Branching vs Traditional Environments
Traditional database testing requires duplicating databases or maintaining long-lived staging systems. These processes are resource-heavy, slow, and often out of sync with production.
In contrast, database branching provides exact, real-time replicas. Developers work with up-to-date environments without waiting on infrastructure. Combined with NVMe-over-TCP, such as in Cloud Cost Optimization, these branches are both fast and scalable.
| Feature | Traditional Environment | Database Branching |
|---|---|---|
| Provisioning Time | Hours or days | Seconds |
| Storage Cost | High (full duplication) | Low (copy-on-write, snapshots) |
| Test Data Fidelity | Often outdated | Fresh production snapshot |
| Parallel Dev Support | Limited | Strong |
| DevOps Integration | Minimal | Native to modern pipelines |
Use Cases for Database Branching
- CI/CD Pipelines: Every commit can auto-provision a database branch for test execution.
- Schema Migration Testing: Run destructive schema changes on real-world structures.
- Data Privacy Compliance: Masked branches for GDPR or HIPAA validation.
- Debugging Production Bugs: Branch from a snapshot to recreate the failure environment.
- Data Science and ML: Experiment with data without impacting transactional stores.
These workflows are supported in scenarios such as a database on Kubernetes and hybrid cloud deployments.
Infrastructure Considerations for Branching
Database branching is only as effective as the infrastructure underneath it. Systems must support instant snapshotting and fast cloning to allow frequent, dynamic branch creation. Efficient storage is critical, which can be achieved using thin provisioning or erasure coding. Additionally, low-latency I/O, such as through NVMe-over-TCP, ensures that these branches operate with production-grade performance. Kubernetes-native provisioning using CSI drivers is key for automation, and simplyblock™ provides all of these capabilities at the storage layer, ensuring infrastructure never becomes a bottleneck.
How Simplyblock Enables Instant Branching
Simplyblock™ powers database branching through its high-performance, software-defined storage platform. With thin provisioning, snapshotting, and copy-on-write volume cloning, it supports multiple concurrent branches with minimal overhead. When combined with Kubernetes, it dynamically provisions persistent volumes using CSI, allowing instant creation of branch environments.
Teams using databases like PostgreSQL can spin up a branch in seconds with near-zero delay, enabling CI/CD pipelines, migration previews, and production debugging—all without manual provisioning or replication delays. This is especially powerful in multi-availability zone scenarios like Disaster Recovery.
Related Terms
Teams often review these glossary pages alongside Database Branching when they set up isolated dev-test environments, accelerate schema changes, and reduce the operational cost of copy-based database workflows.
Kubernetes Block Storage
Zero-Copy I/O
OpenShift Container Storage
Storage High Availability
External and Internal Resources
Optimizing Kubernetes Costs
Wikipedia: Snapshot (computer storage)
Azure SQL Database Snapshots
Questions and Answers
Database branching refers to creating isolated, on-demand copies of a database that teams can use independently for testing, development, or analytics. It helps streamline CI/CD pipelines and supports faster iteration without impacting production, especially when combined with Kubernetes-based storage.
A branch typically uses copy-on-write mechanisms—similar to storage-level snapshot vs clone techniques—allowing fast writable copies with minimal storage overhead. It retains only the changed data, while remaining efficient and space-conscious.
Database branching enables feature teams to work independently on schema changes or data transformations without impacting production or other teams. Combined with Simplyblock’s approach to database performance optimization, it provides fast, storage-efficient isolation and easy cleanup.
It prevents data conflicts, reduces dependency bottlenecks, and accelerates testing. Branching creates lightweight, isolated environments that mirror production without full data duplication, improving agility and scalability.
Yes, it enables teams to spin up isolated copies for running analytical queries or generating reports, without loading production systems or risking performance degradation. It’s ideal for data science, QA, and performance testing environments.