Disaggregated Storage for Kubernetes
Terms related to simplyblock
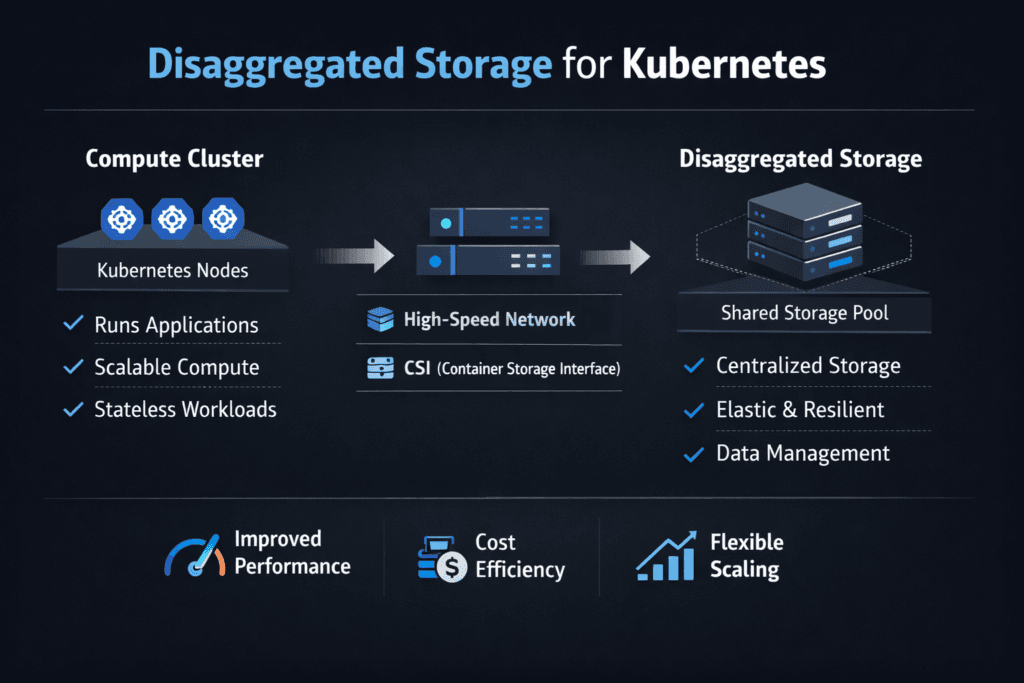
Disaggregated Storage for Kubernetes separates compute nodes from storage nodes, then serves block volumes over the network. App pods still run on worker nodes, while dedicated storage nodes host the drives, manage protection, and present volumes through CSI. This layout helps when storage growth does not match compute growth, when multiple teams share the same cluster, or when you want cleaner failure isolation.
A good design keeps the network path inside the latency budget, keeps failure domains clear, and keeps provisioning rules consistent. This is where Kubernetes Storage, NVMe/TCP, and Software-defined Block Storage work together: Kubernetes expresses intent, NVMe/TCP delivers fast shared block access, and software-defined policy controls placement, protection, and QoS.
Getting more out of disaggregated design with practical platform patterns
Teams improve results when they standardize a few core patterns. A dedicated storage node pool reduces blast radius during worker churn. A small set of StorageClasses prevents drift between teams. Clear QoS rules protect latency-sensitive services from noisy neighbors.
A disaggregated setup also benefits from efficient I/O paths. User-space, zero-copy designs reduce CPU overhead per I/O and help keep p99 latency tighter under concurrency. That matters in real clusters where background load never disappears.
🚀 Keep Multi-tenant Platforms Stable With Storage QoS
Use simplyblock to protect critical workloads from noisy-neighbor I/O.
👉 Use simplyblock for Kubernetes persistent storage →
Disaggregated Storage for Kubernetes inside Kubernetes Storage workflows
In Kubernetes Storage, the platform drives provisioning, attaching, mounting, expansion, and snapshot tasks. The CSI layer defines how Kubernetes talks to storage backends, but the backend controls how fast those steps run and how well they behave during rollouts and node drains. When storage services run on dedicated nodes, Kubernetes can reschedule pods without dragging storage processes across workers.
Disaggregated Storage for Kubernetes also changes capacity planning. You can grow storage nodes without adding compute. You can refresh compute nodes without moving the data layer. That separation simplifies budgeting and reduces forced coupling between hardware cycles.
Disaggregated Storage for Kubernetes over NVMe/TCP networks
NVMe/TCP carries NVMe commands over standard Ethernet, which makes it a strong fit for shared block storage in Kubernetes without specialized fabrics. In disaggregated layouts, the network becomes part of the storage path, so transport choice matters. NVMe/TCP often hits the right balance of performance and ops simplicity for many environments.
When you pair Disaggregated Storage for Kubernetes with Software-defined Block Storage, you also gain policy-driven provisioning, tenant isolation, and consistent rules across clusters. Teams that migrate from arrays often treat this as a SAN alternative with better automation and faster change control.
How to measure disaggregated Kubernetes storage performance
Start with the latency distribution, not only averages. Track p50, p95, and p99 for reads and writes at the block sizes your apps use. Then repeat tests during node drains, rolling deploys, and replica scaling, because those events reveal real contention and rebuild behavior.
Most teams watch four signals that map to day-2 reality: PVC-to-PV bind time, attach and mount time, rebuild time after a node loss, and p99 latency under mixed load. If any one of these drifts, application SLOs follow.
Ways to raise consistency for stateful apps on Kubernetes
These changes tend to deliver fast wins with low drama, especially for databases and queueing systems:
- Set a small number of StorageClasses with clear defaults for protection, snapshots, and expansion.
- Use QoS limits per tenant or namespace to prevent one workload from flooding the pool.
- Pin storage services to a dedicated node pool, and isolate them from bursty compute.
- Use topology-aware placement, so cross-zone hops do not surprise your p99.
- Test node drains and rolling upgrades under load, then tune before production.
Comparison of storage models for Kubernetes platforms
The table below compares common approaches, with an emphasis on scaling behavior and ops impact.
| Model | What scales well | Common pain point | Best fit |
|---|---|---|---|
| Local PV on worker NVMe | Low latency per node | Pod mobility and rebuild complexity | Pinned workloads and strict affinity |
| Hyper-converged storage | Simple footprint | Shared resource contention | Small to mid clusters, mixed apps |
| Disaggregated storage nodes | Independent scale of compute and storage | Network adds latency risk | Larger fleets and steady growth |
| External SAN | Central control | Cost and slow change cycles | Legacy estates and strict controls |
Disaggregated Storage for Kubernetes with simplyblock™ in production
Simplyblock™ delivers Kubernetes Storage through a CSI driver while supporting both disaggregated and hyper-converged layouts. In disaggregated mode, storage services run on dedicated nodes, and worker nodes consume volumes over NVMe/TCP. That separation lets teams scale storage without tying every storage upgrade to a compute refresh.
Simplyblock also focuses on Software-defined Block Storage controls that matter in shared clusters. Multi-tenancy and QoS help keep critical workloads stable when other teams burst. The SPDK-based, user-space approach targets lower overhead per I/O, which helps when the platform runs hot, and latency budgets stay tight.
What comes next for disaggregated Kubernetes storage
Expect more focus on CPU efficiency, tighter isolation, and more offload to DPUs and IPUs. In disaggregated layouts, these gains matter because the storage network and storage services sit on the critical path.
Kubernetes storage workflows should also keep improving around upgrades, snapshots, and failure handling, which reduces operational risk for large fleets.
Related Terms
Teams often pair Disaggregated Storage for Kubernetes with these glossary pages when they plan Kubernetes Storage and NVMe/TCP rollouts.
- What is Disaggregated Storage?
- Kubernetes Storage: Disaggregated or Hyper-converged?
- NVMe over TCP
- SPDK
Questions and Answers
Disaggregated storage separates compute and storage into independent layers while still providing persistent volumes to pods. This model improves flexibility and scalability compared to hyperconverged systems. Architectures based on distributed block storage allow Kubernetes clusters to scale storage independently from compute nodes.
Kubernetes workloads scale dynamically, and disaggregated storage allows independent expansion of capacity and performance. Instead of adding full nodes like in HCI, a scale-out storage architecture lets storage grow horizontally without overprovisioning compute resources.
NVMe over TCP delivers high-performance block storage across standard Ethernet, making it possible to separate storage from compute without sacrificing latency. This supports efficient, distributed storage access across Kubernetes clusters.
Yes. Databases and other stateful applications benefit from performance isolation and flexible scaling. Simplyblock provides optimized persistent volumes for stateful Kubernetes workloads, ensuring low latency and high IOPS in distributed environments.
Simplyblock delivers software-defined, NVMe-backed storage decoupled from compute nodes. Its Kubernetes-native storage platform integrates via CSI, enabling dynamic provisioning, replication, and encryption within a fully disaggregated architecture.