Erasure Coding vs Replication
Terms related to simplyblock
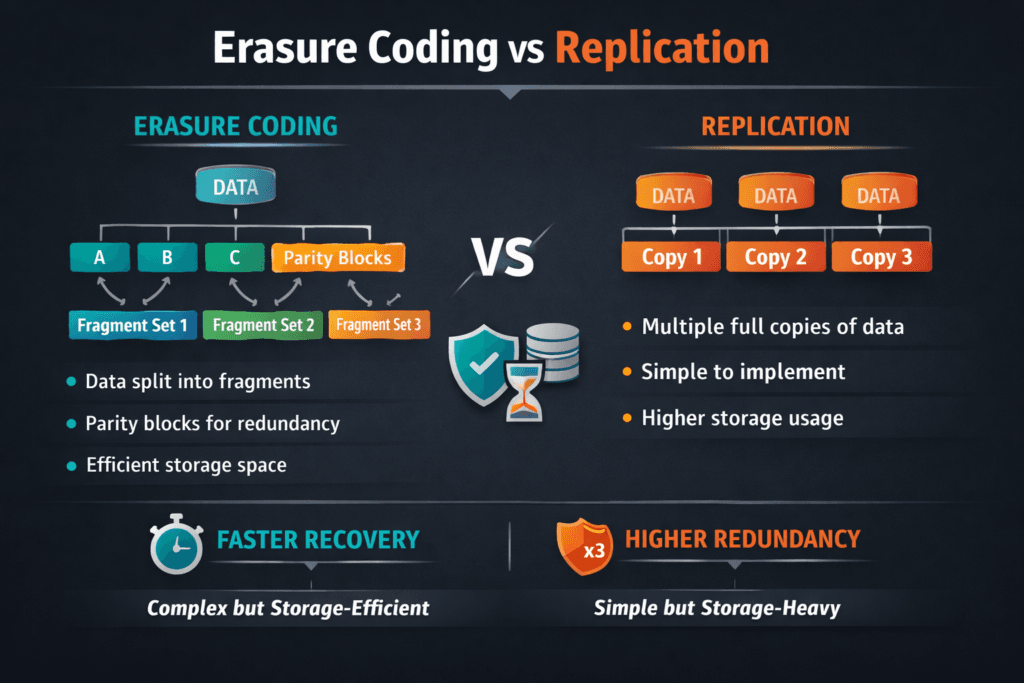
Erasure Coding vs Replication compares two fault-tolerance methods that keep data available when disks, nodes, or racks fail. Replication writes the same data to multiple locations, such as 2x or 3x copies. Erasure coding splits data into fragments, adds parity fragments, and distributes them across nodes so the system can rebuild missing pieces after a failure.
Executives usually evaluate this decision through cost, risk, and recovery. Operators evaluate it through write latency, rebuild behavior, and operational complexity. The same workload can look “fine” with replication in a small cluster and then become cost-heavy at scale. The same workload can look “fine” with erasure coding in read-heavy tests and then suffer during small-write bursts if the stack amplifies writes.
Kubernetes Storage makes the trade-off more visible because stateful Pods churn, volumes move, and background processes like rebalancing and rebuilds run alongside production traffic. Software-defined Block Storage platforms can enforce policy and isolate tenants, which matters because redundancy choices affect every workload sharing the storage pool.
How the two protection models behave under failure
Replication fails over by reading from a surviving copy, and it rebuilds by copying full data blocks to restore the target replica count. That model tends to keep recovery logic simple. It can also restore redundancy quickly when bandwidth remains available.
Erasure coding rebuilds by reading a set of data and parity fragments, then reconstructing the missing fragments. That rebuild can spread I/O across many nodes, which helps throughput in large clusters. It also adds compute overhead for encoding and decoding, and it can add extra I/O on small writes when the system must update parity.
In practice, replication often wins on simplicity and low-latency writes. Erasure coding often wins on usable capacity efficiency at scale. Mixed environments often use a tiered approach where “hot” data uses replication and “cold” data uses erasure coding, especially when cost per usable terabyte matters.
🚀 Compare erasure coding and replication for Kubernetes Storage performance and cost
Use Simplyblock to apply per-volume policies, enforce QoS, and run Software-defined Block Storage on NVMe/TCP.
👉 Use Simplyblock Advanced Erasure Coding →
Erasure Coding vs Replication in Kubernetes Storage
Kubernetes Storage adds scheduling and topology constraints to the decision. If your storage spans failure domains, replication can keep reads simple during a localized outage, but it can multiply capacity and network traffic. Erasure coding can reduce raw capacity needs, but it can increase CPU and I/O work during rebuilds and parity updates, which can show up as tail-latency spikes for busy stateful sets.
For multi-tenant clusters, the risk is not only a node failure. The bigger risk is a noisy neighbor triggering rebuild pressure that bleeds into unrelated namespaces. Software-defined Block Storage platforms that provide QoS and tenant isolation reduce that blast radius. Without isolation, both approaches can cause p99 drift during recovery, just in different ways. Replication tends to consume bandwidth and storage I/O for full copies. Erasure coding tends to consume distributed read bandwidth plus compute, and it can stress small-write workloads if parity updates collide with production traffic.
Operationally, the most stable outcome comes from matching the protection method to the workload tier. Latency-first databases often prefer replication for the hottest volumes. Capacity-first tiers often prefer erasure coding, especially when the cluster is large enough to amortize rebuild work across many nodes.
Erasure Coding vs Replication with NVMe/TCP backends
NVMe/TCP changes the cost of both models because the fabric and CPU become first-class resources. High-performance storage over NVMe/TCP can move a lot of I/O, but encoding, decoding, and rebuild fan-out can still consume CPU on initiators or targets if the data path wastes cycles.
Replication over NVMe/TCP often shows straightforward behavior: predictable reads from a copy, and heavy sequential writes during rebuild when the system restores missing replicas. Erasure coding over NVMe/TCP can reduce the amount of raw data written at steady state, but it may increase read amplification during rebuilds because it must read multiple fragments to reconstruct missing ones.
The practical tuning goal is to keep recovery traffic from starving production traffic. That usually means prioritizing tenant fairness, reserving headroom, and keeping the I/O path efficient per core. A stack that uses user-space NVMe-oF components can reduce kernel overhead and improve CPU efficiency, which helps both replication and erasure coding during recovery windows.
Measuring overhead, rebuild impact, and tail latency
A meaningful comparison separates steady-state performance from recovery performance. In steady state, measure p50, p95, and p99 latency, plus sustained throughput under the workload’s real block sizes and read/write mix. In recovery, measure how quickly redundancy returns, how much extra I/O the cluster produces, and how much latency shifts during rebuild.
Key signals to track include tail latency during background repair, node CPU utilization under load, network utilization on the storage fabric, and the duration of degraded mode. If p99 rises sharply during rebuild, your system likely lacks isolation, lacks headroom, or schedules rebuild work too aggressively for the workload tier.
In Kubernetes Storage, also test the impact of rescheduling and rolling updates, because churn can overlap with recovery work and expose control-plane delays plus data-plane congestion at the same time.
Practical ways to improve outcomes without overbuilding
Use this single checklist to reduce operational risk and keep performance stable across both approaches:
- Align redundancy policy with workload tier, and keep latency-first and capacity-first volumes separate.
- Keep failure domains explicit so the platform places replicas or fragments across the right boundaries.
- Cap rebuild aggressiveness during peak hours, and schedule heavier repair windows off-peak.
- Enforce QoS and tenant isolation so recovery work does not rewrite every namespace’s p99 latency profile.
- Favor efficient data paths so CPU stays available for production I/O when rebuild traffic ramps up.
Cost, performance, and recovery trade-offs
This table summarizes what teams typically see when they compare these approaches in production environments.
| Dimension | Replication | Erasure Coding |
|---|---|---|
| Usable capacity efficiency | Lower, due to multiple full copies | Higher, due to parity-based protection |
| Small-write latency | Often lower and simpler | Can rise due to parity updates |
| Rebuild behavior | Full copy rebuilds, bandwidth-heavy | Fragment rebuilds, distributed reads plus compute |
| Operational simplicity | Usually simpler | Requires more tuning and planning |
| Best fit | Hot data, latency-first services | Capacity-focused tiers, large clusters |
Simplyblock™ for both protection strategies
Simplyblock™ supports Kubernetes Storage deployments where teams want to choose the right protection method per workload tier while keeping operations consistent. Simplyblock’s Software-defined Block Storage approach enables policy-driven behavior, multi-tenancy, and QoS so rebuild work does not punish unrelated workloads.
For performance-sensitive environments, simplyblock supports NVMe/TCP and uses an SPDK-based, user-space data path designed to reduce overhead in the hot path. That CPU efficiency matters during recovery windows because both replication and erasure coding can drive background work that competes with production traffic. When the data path wastes fewer cycles, the platform keeps more headroom for real workloads.
Where the trade-off is heading
More teams are adopting tiered protection, using replication for hot volumes and erasure coding for colder data, because cost and performance pressures rarely point to a single answer. Expect more automation that shifts protection levels based on access patterns, plus tighter controls that schedule repair work based on SLO impact rather than fixed timers.
As NVMe/TCP becomes a common transport for disaggregated storage, the winning designs will pair efficient per-core processing with isolation controls, so redundancy does not become a tail-latency tax in shared Kubernetes Storage environments.
Related Terms
Often reviewed with Erasure Coding vs Replication.
Questions and Answers
Erasure coding reduces raw-capacity overhead by splitting data into data+parity fragments, so you typically get much higher usable capacity than 2x/3x replication at the same fault tolerance. The tradeoff is more compute and cross-node reads during degraded mode or rebuilds, which can lift tail latency. Use it when cost/GB matters and workloads tolerate rebuild dynamics.
Replication is usually the safer option when you need consistent p99 latency for databases and sync-heavy workloads, because it avoids parity reconstruction on every stripe update. With replication, degraded reads often come from a surviving full copy, while erasure coding may require gathering shards across nodes. If you can’t afford latency variability during rebuild, replication tends to win.
If your failure domain is “one node,” both approaches can work well, but whole-zone failure pushes you to think about placement and rebuild traffic. Replication is operationally simple because any intact copy can serve reads immediately after a failure. Erasure coding is more capacity-efficient, but degraded reads and recovery may pull shards across domains and amplify latency if the network is hot.
Replication usually restores service predictably: the system promotes an existing copy and rebuilds another copy in the background. Erasure coding can require reconstruction from multiple fragments, which may increase recovery I/O and CPU, and make performance during rebuild more variable. If your priority is steady performance under failure, replication is often preferred; if capacity efficiency is top priority, erasure coding can be worth it.
Yes—many systems use replication for “hot” data (low latency, fast failover) and erasure coding for “warm/cold” data (capacity efficiency). This tiered approach keeps strict SLAs where they matter while lowering cost/GB for less sensitive datasets. Hybrid schemes can also reduce hotspots during failures by changing how parity is placed and rebuilt.