High Availability Block Storage Design
Terms related to simplyblock
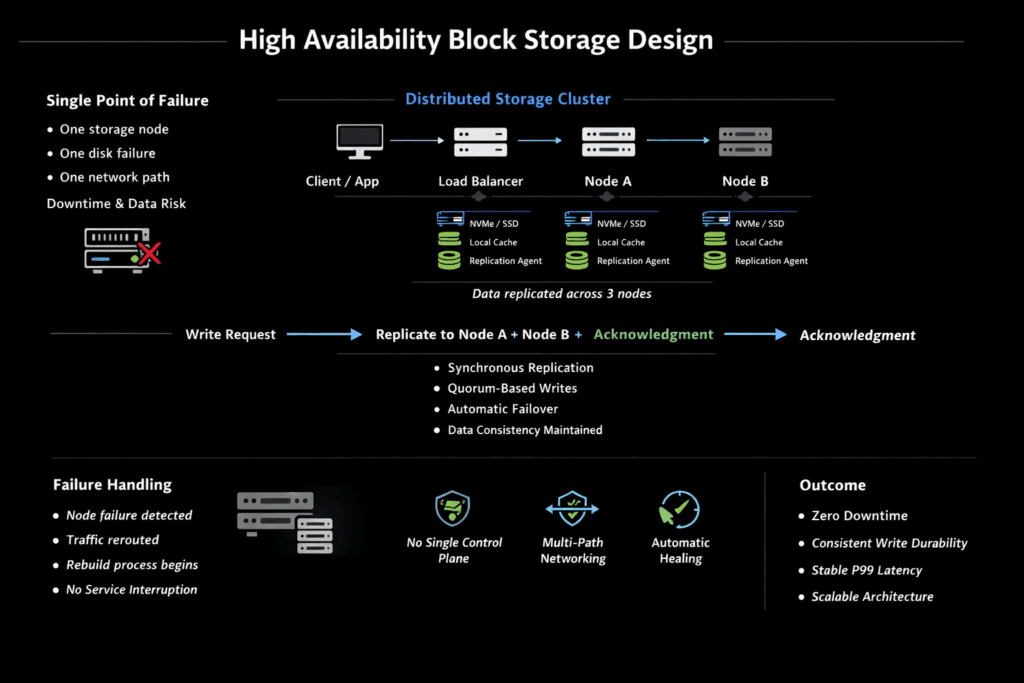
High Availability Block Storage Design defines how a block storage layer keeps applications online during failures while protecting data consistency and meeting recovery targets. The design ties together redundancy, failure-domain awareness (node, rack, zone), and automated recovery so storage stays available during node loss, link loss, upgrades, and rebuild events.
Executive stakeholders usually evaluate HA through business outcomes: service uptime, blast radius, RTO, RPO, and the impact of recovery operations on customer-facing latency. Platform teams translate those outcomes into storage mechanics such as replica or fragment placement, quorum rules, fast failover, safe reattachment, and guardrails that prevent one workload from starving another. In Kubernetes Storage environments, that last point matters because scheduling events and noisy-neighbor behavior happen every day, not once a quarter.
Resilience-first choices for modern block platforms
Design starts with the durability model, then the datapath. Replication supports direct failover because a full copy can serve I/O when a peer fails. Erasure coding reduces capacity overhead at scale, but rebuild work can raise tail latency if the cluster runs without headroom. Many SAN alternative designs also struggle under failure because the storage stack burns too much CPU per I/O and loses consistency during recovery.
A modern Software-defined Block Storage platform improves HA results when it keeps the I/O path efficient. SPDK-style user-space I/O, polling, and zero-copy techniques reduce kernel overhead, which helps sustain performance during failover, rebalancing, and repair operations.
🚀 Design High-Availability Block Storage, Natively in Kubernetes
Use Simplyblock to streamline failover paths and keep latency steady during rebuilds.
👉 Use Simplyblock for High-Availability Block Storage →
High Availability Block Storage Design in Kubernetes Storage
Kubernetes Storage changes HA assumptions because workloads move constantly. Pods reschedule, nodes drain, and cluster autoscaling cause frequent topology shifts. HA storage must reattach volumes safely and quickly, and it must respect topology constraints so replicas or erasure-coded fragments do not share the same failure domain.
Architecture choice also affects availability. Hyper-converged deployments can keep I/O local and reduce network hops, while disaggregated deployments isolate storage nodes and scale them without forcing compute growth. Many teams run both models in one cluster by mapping storage classes to workload intent, which reduces operational risk and supports different RTO and latency goals across application tiers.
High Availability Block Storage Design with NVMe/TCP transport
NVMe/TCP works well for HA because it runs over standard Ethernet, integrates into Kubernetes Storage stacks without specialized fabrics, and supports disaggregation without forcing forklift network upgrades. A solid design uses multiple paths, fast reconnection behavior, and capacity headroom so failover does not turn into a congestion event.
NVMe/TCP also fits tiered storage strategies. Teams can standardize on NVMe/TCP for broad compatibility and operations, then reserve RDMA-based transports for the narrow set of workloads that require the tightest latency bands. This approach keeps the default path simple while still enabling high-end performance tiers.
Measuring and Benchmarking High Availability Block Storage Design Performance
Benchmarking HA storage requires more than peak IOPS. Measure steady-state behavior first, then inject failures while the workload continues. Track p50, p95, p99, and p999 latency, and measure time-to-recover so you can compare designs under real stress.
A practical method uses fio with controlled job counts, block sizes, and queue depth, then repeats the same profile during (1) storage-node failure, (2) network-path failure, and (3) rebuild or rebalancing. Focus on tail latency and error rates during recovery, because that is where customer-visible incidents start. Simplyblock performance testing, for example, uses fio with fixed job and I/O depth settings and reports scaling behavior across cluster sizes, which helps operators plan headroom for failure scenarios.
Practical techniques to improve HA behavior under load
The quickest gains usually come from policies and headroom, not from aggressive micro-tuning. Keep the system stable during recovery by prioritizing placement, rebuild limits, and multi-tenant controls.
- Enforce failure-domain separation so replicas or fragments avoid shared nodes, racks, or zones.
- Reserve rebuild headroom, so repair traffic cannot starve foreground I/O.
- Apply QoS per tenant or workload class to prevent noisy-neighbor spikes during failover.
- Reduce CPU overhead in the datapath with SPDK-based design patterns, including user-space and zero-copy I/O.
- Validate network behavior under stress, including retransmits, congestion, and multipath failover timing for NVMe/TCP.
A quick comparison of common HA design patterns
The table below summarizes typical choices teams make when balancing availability, cost, and operational simplicity.
| Pattern | Primary benefit | Common trade-off |
|---|---|---|
| 2-way / 3-way replication | Straightforward failover | Higher capacity overhead and rebuild traffic |
| Erasure coding | Better storage efficiency | Repair work can raise tail latency without headroom |
| Cross-zone active-active | Zone-level resilience | Harder consistency, networking, and testing discipline |
Minimizing Downtime with Simplyblock™ Storage Architecture
Simplyblock™ provides Software-defined Block Storage built for Kubernetes Storage and NVMe/TCP. It supports hyper-converged, disaggregated, and hybrid deployments, so teams can align storage layout with failure domains and workload tiers.
The platform targets stability during recovery by combining an efficient SPDK-style datapath with multi-tenancy and QoS controls. That combination helps reduce latency spikes when background repair work ramps up, and it keeps critical volumes insulated from noisy neighbors. Simplyblock also positions as a modern SAN alternative by running on off-the-shelf hardware and scaling out without storage silos.
Where HA block storage is headed
HA design is moving toward policy-driven storage classes that encode durability level, failure-domain intent, and performance envelope. This gives platform teams a safer self-service model for application owners, and it reduces drift caused by ad hoc tuning.
Another direction is dataplane offload to DPUs and IPUs. Offload can isolate storage and networking work from application CPU usage, which improves consistency during noisy periods and recovery events. In parallel, expect deeper integration between Kubernetes scheduling signals and storage placement so clusters avoid risky colocation automatically.
Related Terms
These terms support High Availability Block Storage Design by improving failover speed, recovery, and tail latency.
Questions and Answers
A high availability (HA) block storage design includes synchronous replication, distributed data placement, quorum-based consistency, and automatic failover. Modern platforms use a distributed block storage architecture to eliminate single points of failure and maintain uptime during node outages.
Replication ensures that data is written to multiple nodes simultaneously, allowing workloads to continue if one node fails. Simplyblock implements replication within its scale-out storage architecture to maintain continuous access and data integrity.
Yes. NVMe over TCP enables distributed NVMe-backed volumes across standard Ethernet networks. When combined with replication and automated failover, it delivers both high performance and enterprise-grade availability.
In Kubernetes, HA storage relies on replicated persistent volumes and automatic pod rescheduling. Simplyblock integrates via CSI to provide resilient volumes for stateful Kubernetes workloads, minimizing downtime during infrastructure failures.
Simplyblock delivers HA through distributed NVMe nodes, synchronous replication, and dynamic volume provisioning. Its software-defined storage platform ensures workloads continue operating even during node or network failures.