In-network computing
Terms related to simplyblock
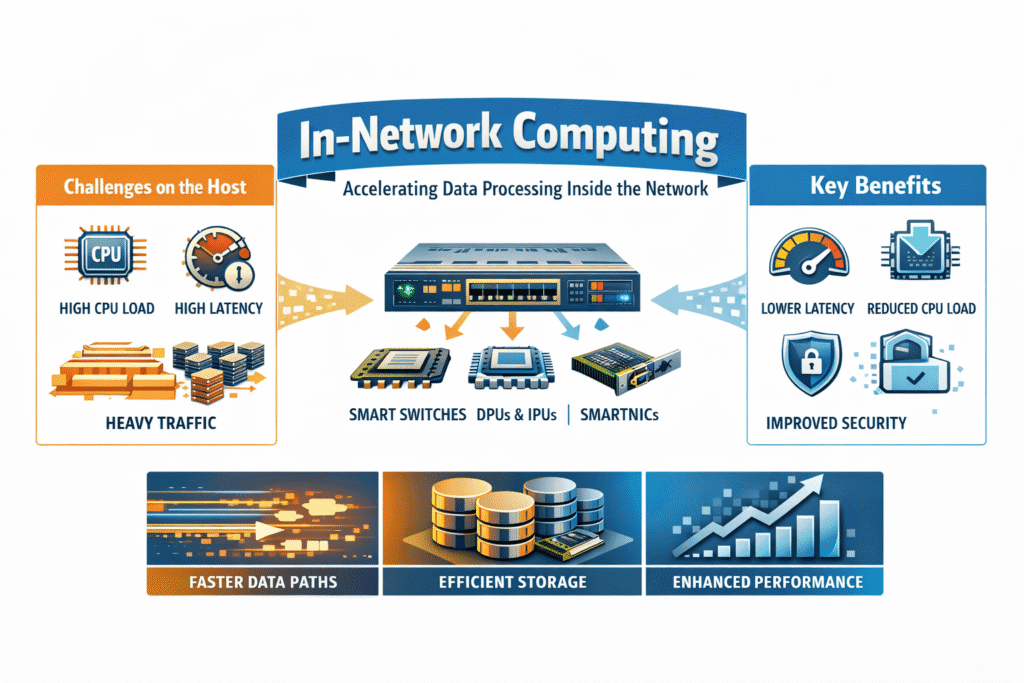
In-network computing runs selected logic inside the network data path instead of pushing every decision to the host CPU. Teams use programmable switches and network-attached accelerators such as SmartNICs, DPUs, and IPUs to apply focused processing at very high packet rates.
Storage and platform leaders care about one outcome: less infrastructure overhead on the host during heavy traffic. That matters most when clusters rely on NVMe/TCP, serve Kubernetes Storage at scale, and need Software-defined Block Storage to keep latency steady for multiple tenants.
Why in-network computing becomes a priority in enterprise clusters
Platform teams hit a wall when platform work starts to dominate the CPU budget. East-west traffic grows, encryption becomes the default, microsegmentation expands, and observability increases the volume of metrics and traces. Those tasks compete with databases, streaming jobs, and storage services on the same nodes.
In-network computing helps by shifting selected enforcement and measurement into the data path. Teams usually see the biggest gains in p95 and p99 latency because fewer shared bottlenecks remain on the host during bursts.
🚀 Apply In-network Computing to NVMe/TCP Storage in Kubernetes
Use Simplyblock™ to run Software-defined Block Storage with multi-tenancy and QoS on standard Ethernet.
👉 See NVMe/TCP Kubernetes Storage with Simplyblock →
How in-network computing is implemented in real deployments
Most in-network computing deployments combine a programmable data plane with a control plane that configures it. Many teams use P4 to define packet behavior, then compile it for a target such as a programmable switch ASIC or an accelerated NIC pipeline.
The best results come from keeping the logic tight and predictable. Data-plane code fits tasks like classification, counters, metering, filtering, and fast-path checks. Complex state, large memory needs, or frequent rule changes usually belong on hosts or in dedicated services.
NVMe/TCP data paths and Ethernet fabrics
NVMe/TCP runs NVMe over standard TCP/IP on Ethernet. Teams use it for routable fabrics and SAN alternative designs without locking into an RDMA-only network. This lines up with in-network computing because many costs sit in the network and security layers around the storage flow, not in the NVMe media itself.
At high IOPS, hosts burn CPU on TCP processing, encryption, policy checks, and telemetry. When the network enforces parts of policy and collects parts of telemetry closer to the wire, hosts keep more headroom during bursts, and shared clusters hold steadier tail latency.
Kubernetes Storage architectures that benefit from data-path offload
In-network computing does not replace storage services. In Kubernetes Storage, you still need Software-defined Block Storage to deliver volumes, snapshots, resiliency, multi-tenancy, and QoS. Kubernetes also still relies on CSI workflows for provisioning and lifecycle control.
Hyper-converged layouts run apps and storage on the same nodes, so CPU pressure shows up fast during spikes. Disaggregated layouts split storage nodes from app nodes, which makes the network path and isolation boundaries more important. Offload helps in both models when it cuts the host-side platform tax that would otherwise compete with scheduling and storage I/O.
Where computation runs in storage-heavy Kubernetes clusters
The table below compares common placements for enforcement and measurement functions that impact NVMe/TCP flows, and how each tends to affect Kubernetes Storage consistency when Software-defined Block Storage is serving multiple tenants.
| Placement choice | Typical functions that fit | Typical impact on storage-heavy clusters |
| Programmable switch pipeline | Classification, counters, basic filtering, metering | Reduces noisy traffic patterns early, limits hotspot amplification |
| Accelerated NIC, DPU, or IPU | Per-host shaping, inline policy hooks, telemetry, crypto assist | Preserves host CPU for apps and storage services, steadier p99 under load |
| Host CPU and kernel | Full flexibility, broad feature coverage | Higher contention during bursts, more tail-latency risk |
Performance and CPU efficiency in Software-defined Block Storage
Data-path offload works best when the storage layer also minimizes overhead. Storage teams aim for fewer copies, fewer context switches, and stable CPU use at high queue depth because those factors directly shape tail latency.
Shared clusters raise the bar further. In-network computing can reduce host contention by moving selected policy and telemetry into the data path, but multi-tenancy and QoS still need firm controls when Software-defined Block Storage serves multiple tenants over NVMe/TCP.
Simplyblock™ and in-network computing for NVMe/TCP Kubernetes Storage
Simplyblock™ fits the in-network computing model because the offload layer and the storage layer solve different problems. In-network controls can handle traffic policy, telemetry, and enforcement closer to the wire, which reduces host pressure during storage-heavy periods. Simplyblock then delivers Software-defined Block Storage for Kubernetes Storage over NVMe/TCP, with multi-tenancy and QoS to limit noisy-neighbor impact.
Teams get the best outcomes when they pair in-network data-path controls with storage-side QoS. That mix protects CPU headroom and keeps performance boundaries enforceable.
Related Technologies
These glossary terms are commonly reviewed alongside In-network computing when planning offload-heavy networking and storage data paths in Kubernetes Storage.
Tail Latency
Storage Latency
NVMe Latency
NVMe over RoCE
Questions and Answers
In-network computing processes data directly within the network hardware, reducing latency and offloading tasks from CPUs. When combined with DPUs, it enables faster storage access, secure isolation, and efficient traffic handling at scale.
By executing tasks like encryption, filtering, and NVMe-oF offload inside the network, in-network computing reduces pod-to-storage latency and network congestion. This results in better performance and improved scalability for stateful workloads.
Yes, offloading I/O operations into the network reduces CPU bottlenecks and enables parallel data movement. This is particularly useful for software-defined storage where high throughput and low latency are critical.
Technologies like DPUs, IPUs, and programmable switches from vendors like NVIDIA (BlueField) and Intel (E2200 IPU) enable in-network computing. These devices execute functions such as storage translation, firewalls, and telemetry directly in the data path.
In-network computing allows hardware-enforced isolation and processing of security policies, reducing risks of data leakage. This enhances multi-tenant security while maintaining performance for distributed applications across tenants.