Local Node Affinity
Terms related to simplyblock
Local node affinity is a Kubernetes scheduling constraint that ties a workload to a specific subset of nodes, based on node labels. It is commonly used to keep a Pod close to a hardware dependency such as local NVMe drives, a GPU, a DPU/IPU, or an availability zone–scoped storage volume.
In Kubernetes Storage designs, local node affinity shows up in two places: the Pod’s nodeAffinity rules and the PersistentVolume’s nodeAffinity rules. When those rules do not align, the scheduler can block placement because the volume can only be attached from certain nodes or topologies.
Why Local Node Affinity Matters for Kubernetes Storage
Executives typically feel affinity as an availability and performance issue, not a YAML issue.
Local node affinity can:
Reduce p99 latency by keeping I/O on the same host or rack when using baremetal NVMe, or when a workload is sensitive to cross-rack congestion.
Increase scheduling fragility when a volume is bound to a single node, because node drain, maintenance, and failure become storage events, not just compute events.
Create multi-zone deadlocks when an application requires volumes that are pinned to different zones, or when the Pod affinity rules disagree with a volume’s topology rules.
If your goal is predictable performance with fewer placement constraints, a networked, NVMe-oF approach often reduces the need to pin workloads to individual nodes while still keeping latency low.
🚀 Reduce Local Node Affinity Without Losing NVMe Performance
Run Kubernetes Storage on Software-defined Block Storage over NVMe/TCP so stateful Pods can reschedule cleanly during drains and failures.
👉 See NVMe/TCP Kubernetes Storage →
Pod affinity vs volume node affinity
Pod node affinity influences where Kubernetes wants to run the Pod.
PersistentVolume node affinity describes where the volume can be used. This is especially visible with local persistent volumes and with zonal cloud volumes.
Kubernetes also supports topology-aware provisioning, which helps align volume creation with the scheduler’s placement decisions, especially when the StorageClass uses wait for first consumer semantics.
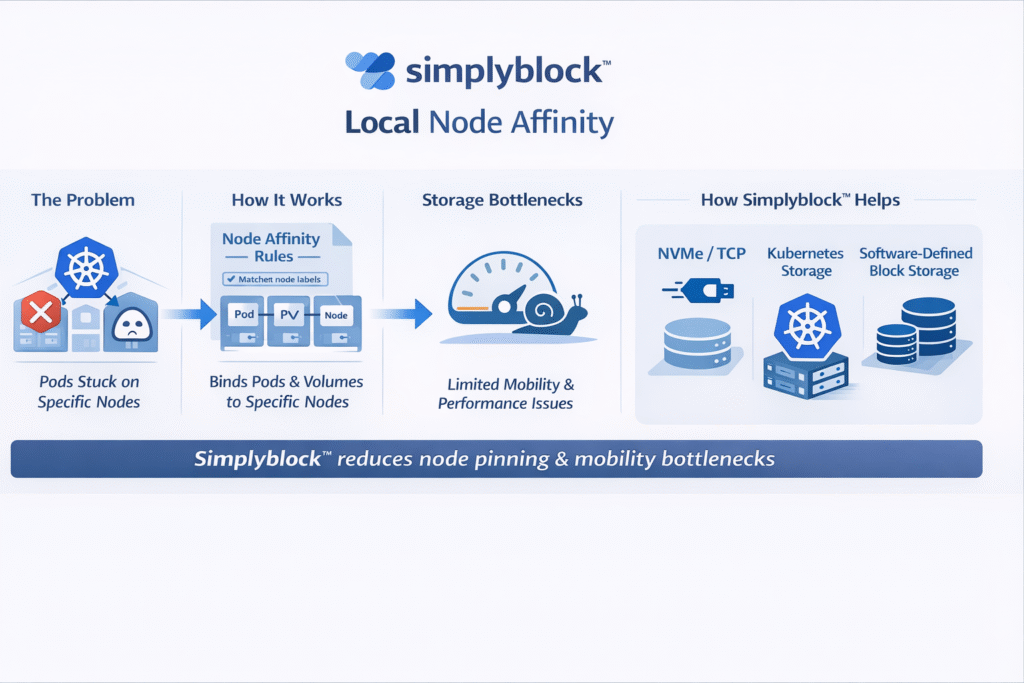
Local PVs, baremetal NVMe, and operational trade-offs
Local persistent volumes are a direct example of local node affinity. They are fast because they use storage on the node itself, but they also bind the workload’s data to that node’s lifecycle.
This pattern is common for ultra-low-latency databases, streaming buffers, and scratch space on baremetal, but it tends to push teams into manual capacity planning and more careful failure-domain thinking. Kubernetes itself calls out that local volumes require PersistentVolume node affinity, and that the scheduler uses that affinity when placing Pods.
When the objective is local NVMe performance without local NVMe fragility, teams often adopt Software-defined Block Storage that can pool NVMe across multiple hosts, then present it back over NVMe-oF transports.
How Software-defined Block Storage changes affinity decisions
With Software-defined Block Storage, the storage layer can be made topology-aware while remaining decoupled from the application’s node placement rules. That helps when you want:
A SAN alternative that avoids hard pinning to a single node.
Disaggregated storage so compute and storage can scale independently.
Centralized QoS and multi-tenancy so noisy-neighbor effects are controlled without forcing workload isolation by node.
Simplyblock is built around NVMe/TCP for Kubernetes Storage, and leverages SPDK concepts (user-space, polled-mode, zero-copy I/O) to reduce CPU overhead and latency in the storage dataplane.
Common reasons teams set local node affinity
- They need deterministic access to node-attached hardware such as NVMe drives, GPUs, or DPUs.
- They run local persistent volumes and must follow the volume’s node constraints.
- They want fault-domain control (rack, zone, compliance boundary) beyond what spread scheduling provides.
- They need predictable tail latency for a workload tier, and they are reserving a node pool for it.
Storage Models and Their Affinity Impact
Local node affinity is not good or bad, but it changes who owns reliability: the scheduler, the storage layer, or both.
The below table below shows how the source of affinity affects operations.
| Storage pattern | Where the affinity is enforced | What it does to scheduling | Typical executive-level impact |
| Local PV on baremetal NVMe | PersistentVolume node affinity | Pod must land on the node that has the disk | Lowest latency, highest coupling to node health |
| Zonal cloud block volume | Zone topology constraints | Pod must land in the same zone as the volume | Easy scaling, but multi-zone designs need discipline |
| Software-defined Block Storage over NVMe/TCP | Storage control plane + CSI topology awareness | Fewer hard node pins, placement can stay flexible | Better resilience and utilization, SAN-like behavior on standard Ethernet |
Simplyblock™ and Local Node Affinity in Kubernetes Storage
Simplyblock™ is designed to let you choose the affinity model instead of inheriting it from a storage appliance. In hyper-converged mode, it keeps storage close to compute while pooling NVMe resources. This reduces the need for strict local node affinity rules while maintaining multi-tenant QoS.
In disaggregated mode, simplyblock separates storage nodes from application nodes, so workloads are less dependent on node-local volumes. That lowers the risk of scheduler deadlocks caused by PersistentVolume node constraints during drains and failures. It provides Kubernetes Storage with Software-defined Block Storage over NVMe/TCP as a SAN alternative.
Related Technologies
These glossary terms are commonly reviewed alongside Local Node Affinity when tuning Pod placement, volume behavior, and storage performance in Kubernetes Storage.
Kubernetes StatefulSet
Storage Quality of Service (QoS)
Tail Latency
Storage Latency
Questions and Answers
Local node affinity ensures that workloads are scheduled close to required resources, such as persistent volumes. This improves performance by reducing network latency and is especially useful in storage-heavy environments like stateful applications on Kubernetes.
Local node affinity is a scheduling rule that prefers or requires a pod to run on specific nodes with matching labels. It’s often used to ensure data locality, which boosts performance for distributed storage and high-IOPS workloads.
For high-performance NVMe over TCP setups, local node affinity ensures that compute and storage stay close. This reduces protocol overhead, minimizes latency, and helps maximize throughput in I/O-bound Kubernetes clusters.
Yes. By ensuring that pods are scheduled on the same node or zone as their persistent volumes, local node affinity eliminates unnecessary network hops. This results in faster disk access and lower latency—ideal for databases on Kubernetes.
Simplyblock’s CSI driver supports topology-aware scheduling with local node affinity, ensuring volumes are provisioned close to pods. This improves both performance and resource efficiency in Kubernetes-native environments without manual intervention.