Log-Structured Merge Tree (LSM Tree)
Terms related to simplyblock
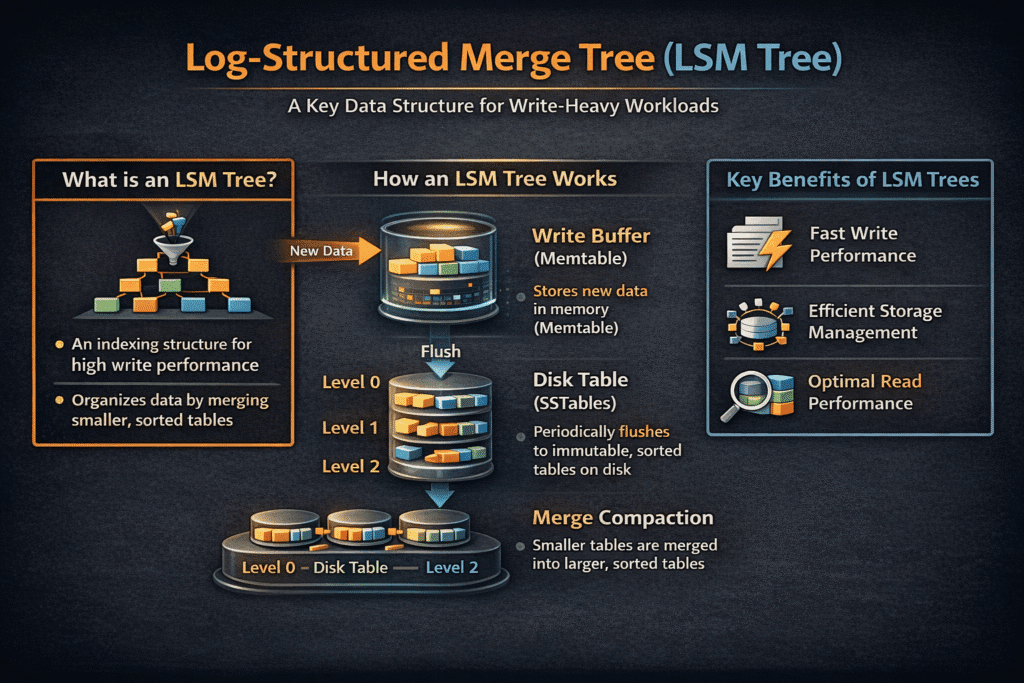
A Log-Structured Merge Tree (LSM tree) is a storage design that handles heavy writes by batching them. The engine accepts updates in memory, records them in an ordered structure, and then flushes sorted data to disk as immutable files. In the background, compaction merges files, removes old versions, and keeps lookups from slowing down.
This design gives strong write throughput, but it shifts work into the background. Reads may need to check more than one file, and compaction can create bursts of mixed I/O. When the storage layer cannot absorb that mix, p99 latency climbs and throughput drops during peak load.
Storage-Layer Tuning for Write-Heavy Engines
Database settings alone rarely fix stability issues under compaction pressure. The storage path shapes the real outcome because it carries three streams at once: foreground reads, foreground writes, and background merge traffic. If the platform shares device queues across many tenants without guardrails, compaction waves turn into cluster-wide jitter.
Software-defined Block Storage helps because it centralizes controls that teams otherwise scatter across nodes. It can enforce volume limits, place data with intent, and reduce noisy-neighbor impact. It also supports SAN alternative designs where you want to scale without locking into an array.
🚀 Keep LSM Compactions Smooth on NVMe/TCP Kubernetes Storage
Use Simplyblock to stabilize p99 latency during flush and compaction with Software-defined Block Storage.
👉 Scale Apache Cassandra on Kubernetes with Simplyblock →
LSM Tree Workloads in Kubernetes Storage
In Kubernetes Storage, these databases often run in StatefulSets with PersistentVolumes. That setup brings portability, but it also adds scheduling and shared infrastructure into the performance path. Pod moves, node drains, and rolling updates can increase compaction debt if the system cannot reconnect volumes quickly and keep read latency steady.
Multi-tenancy also changes the risk profile. One service can trigger large scans, flush storms, or merge backlogs that compete with other stateful apps. Platform teams avoid this by matching StorageClasses to workload types, setting per-volume limits, and isolating critical tenants with QoS.
LSM Tree Compaction over NVMe/TCP
NVMe/TCP supports disaggregated storage over standard Ethernet while preserving the NVMe command model. This matters when merge work ramps up because extra reads and large rewrite streams can saturate weaker protocols and burn CPU on the host.
A clean NVMe/TCP design lets teams pool flash across nodes and scale as a SAN alternative. It also fits mixed fleets where some nodes run hyper-converged, and others run disaggregated. The storage layer still needs to keep background work in check, or compaction will steal headroom from foreground reads.
Benchmarking What Matters Under Compaction Pressure
Measure two tracks at the same time – foreground service quality and background cost. Foreground metrics include p95 and p99 latency for reads, writes, and range scans. Background metrics include merge throughput, merge backlog, file counts, and cache hit rates.
Run tests long enough to reach steady state. Short tests look great, then production pays the bill later. Add controlled disruption into the plan, such as a node drain or a rolling update, because those events often reveal the worst-case behavior in Kubernetes environments.
Practical Controls That Improve Stability
Most gains come from reducing merge collisions and protecting the read path:
- Set clear limits for merge threads and merge bandwidth so background work cannot starve reads.
- Size the cache for the working set and watch miss rates, since misses multiply file probes.
- Tune file and block sizes to reduce tiny I/O that burns CPU per request.
- Cap rebuild, rebalance, and scrub rates so recovery work does not stack on the merge load.
- Apply QoS and tenant isolation so one dataset cannot dominate shared queues.
- Use tiering when available so hot data stays on faster media and cold tables move down.
Compaction Behavior Across Common Storage Options
Different storage approaches react very differently when the merge load increases. The table below compares what teams usually see under sustained write ingestion and periodic merge peaks.
| Storage approach | Merge throughput under load | Read latency stability during merge peaks | Operational fit |
|---|---|---|---|
| Local NVMe per node | High until hotspots form | Medium, depends on placement | Simple clusters, single-tenant nodes |
| Legacy SAN-style network block | Medium | Medium to low under mixed I/O | Conservative environments |
| Disaggregated block over NVMe/TCP | High | High when limits exist | Scale-out pools, SAN alternative designs |
| Software-defined Block Storage on NVMe/TCP | High | Highest with QoS and policy controls | Multi-tenant Kubernetes Storage platforms |
Predictable Database I/O with Simplyblock™
Simplyblock™ helps compaction-heavy databases by keeping the I/O path efficient and by shaping background work so it does not overwhelm foreground reads. In Kubernetes Storage, CSI-based integration supports standardized provisioning while still allowing volume-level policies for isolation and QoS.
When you run disaggregated designs, NVMe/TCP support helps you pool flash and scale without dragging legacy protocol overhead into the hot path. That combination matters most during merge peaks, because the system must handle sustained reads, sustained writes, and metadata work without letting p99 drift.
Where LSM-Based Systems Are Headed Next
Engines keep moving toward lower merge churn and steadier reads. Many teams now favor adaptive merge policies that react to hot keys, TTL-heavy data, and shifting access patterns. Better visibility into merge debt also helps, since it gives early signals before p99 latency moves.
On the infrastructure side, teams keep tightening the datapath to lower CPU cost per I/O and to stabilize queues at high concurrency. NVMe/TCP makes disaggregation simpler to operate, and Software-defined Block Storage gives teams the control layer needed to keep merge peaks from turning into user-facing incidents.
Related Terms
Teams often review these glossary pages alongside this topic when they tune compaction behavior and latency targets.
Questions and Answers
LSM Trees batch and sequence writes in memory before flushing them to disk, drastically reducing random I/O and improving throughput. This makes them highly efficient for write-intensive workloads, especially when used with fast backends like NVMe storage.
While B-Trees modify data in-place and are optimized for read-heavy workloads, LSM Trees write data sequentially and compact it over time. LSM Trees excel in environments where write performance and storage efficiency are critical, such as distributed or cloud-native databases.
LSM Trees offer high write throughput and predictable performance, making them suitable for dynamic, ephemeral storage often used in Kubernetes environments. Their structure handles frequent writes and compactions without degrading performance over time.
Yes, LSM-based systems benefit greatly from the low latency and high IOPS offered by NVMe over TCP. Sequential writes and compaction tasks in LSM Trees align well with the capabilities of NVMe, unlocking faster data ingestion and better throughput.
Although efficient for writes, LSM Trees can suffer from read amplification and increased storage costs due to frequent compactions. Solutions include tuning compaction strategies or pairing with high-performance storage, such as software-defined storage to balance speed and cost.