Network offload on DPUs
Terms related to simplyblock
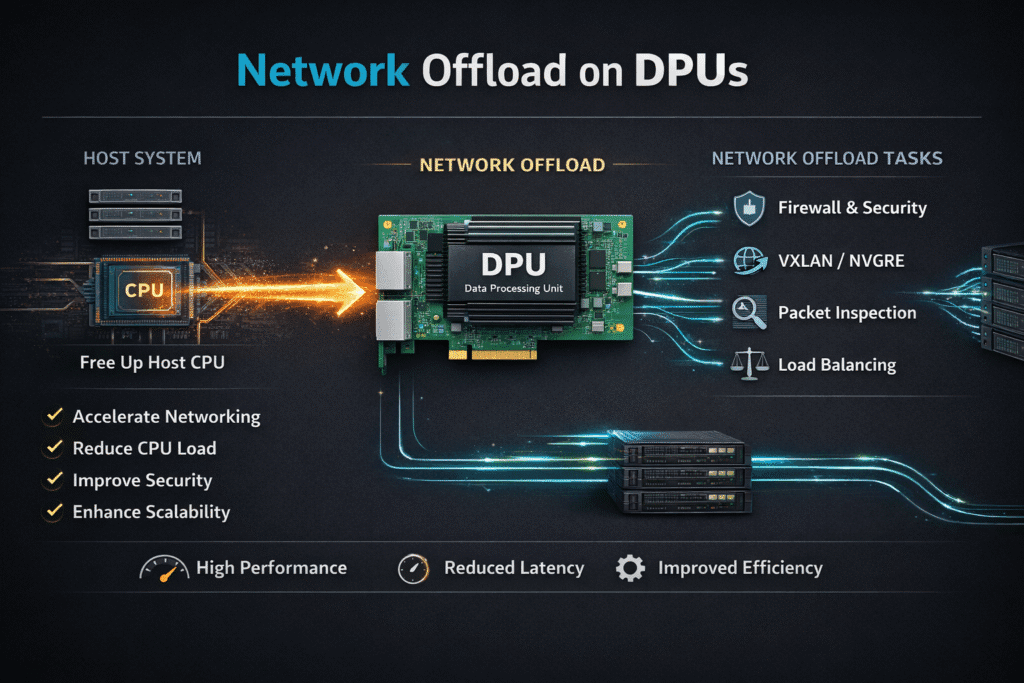
Network offload on DPUs is the practice of moving infrastructure networking work, such as packet processing, encryption, overlay handling, and storage networking, from the host CPU onto a Data Processing Unit (DPU).
A DPU typically combines NIC capabilities with programmable compute, so it can run data-plane services close to the wire and reduce CPU cycles spent on infrastructure tax.
Why Network Offload on DPUs Matters to Executives
When servers spend significant CPU time on networking, application density drops, and performance becomes less predictable. Network offload on DPUs is usually adopted for three reasons: higher workload consolidation, stronger isolation in multi-tenant platforms, and more stable tail latency under contention.
In environments running Kubernetes Storage and high-IO workloads, predictability often matters as much as peak throughput because noisy neighbors and mixed traffic patterns can drive p99 latency.
🚀 Apply Network Offload on DPUs for High-Throughput Data Planes
Use Simplyblock to keep the data path efficient under multi-tenant pressure and heavy I/O.
👉 Use Simplyblock for PCIe-Based DPU Designs →
Why Network Offload on DPUs Matters in NVMe/TCP and Kubernetes Storage
Storage traffic is still network traffic. If you rely on NVMe/TCP for block storage fabrics, packet handling, TCP processing, and security work compete with application threads unless the platform reduces overhead.
A DPU can take on parts of that work so the host focuses on application compute, and the storage path sees fewer interruptions. This becomes more visible when Software-defined Block Storage is shared across teams and clusters and when QoS, rate limiting, and tenant isolation need enforcement without overprovisioning.
What typically gets offloaded
DPU network offload is not one feature. It is a set of data-plane capabilities that can be deployed incrementally, depending on hardware and operational maturity.
- Packet processing and flow steering for high-rate east-west traffic.
- Cryptography at line rate, such as TLS termination or IPsec.
- Virtual switching, overlay networks, and service insertion for network functions.
- Telemetry, filtering, and policy enforcement closer to the network boundary.
- Storage-adjacent networking tasks that accelerate the data path used by NVMe/TCP fabrics.
Where the DPU sits in the I/O path
A DPU commonly sits on the NIC, inline with traffic entering and leaving the host. That placement enables it to perform work before packets hit the host kernel. In practical terms, that can mean fewer interrupts, less context switching, and tighter control of prioritization under load.
In multi-tenant designs, it also provides a clear separation boundary: infrastructure functions run on the DPU, and applications run on the host
Network Offload on DPUs Trade-offs by Architecture
This table compares where the networking data plane runs when you keep everything on the host, accelerate on the CPU, or offload onto a DPU. Use it to map architecture choices to CPU efficiency, isolation, and tail-latency risk. It is a fast way to align platform, security, and operations teams before you commit to hardware, or to a fabric design.
A simple way to frame the design choice is to compare no offload, software acceleration on the CPU, and DPU offload. The right answer depends on your latency targets, operator skillset, and how much isolation you need.
| Approach | Where networking work runs | Strengths | Typical trade-offs | Best fit |
| Host networking (no offload) | Host kernel and CPU | Lowest complexity, standard tooling | Higher CPU overhead, less predictable tail latency | Smaller clusters, non-latency-critical apps |
| Kernel-bypass on CPU (DPDK-style) | Host CPU in user space | Higher packet rate, lower kernel overhead | Still consumes host cores, needs tuning and pinning | Dedicated network appliances, performance labs |
| DPU network offload | DPU inline on the NIC | Better host CPU efficiency, stronger isolation, stable performance under contention | Requires DPU lifecycle ops, hardware qualification | Multi-tenant platforms, strict SLOs, dense clusters |
Simplyblock™ and DPU network offload
Simplyblock aligns with DPU-centric architectures by emphasizing CPU-efficient data paths and predictable performance for shared storage environments. For teams standardizing on Kubernetes Storage with Software-defined Block Storage, the operational goal is consistent provisioning, isolation, and QoS while scaling without storage silos.
In NVMe/TCP deployments, DPU network offload complements this direction by reducing infrastructure overhead and helping keep latency stable as clusters grow, especially in mixed hyper-converged and disaggregated designs.
Where DPU Offload Shows Up First
DPU offload is often introduced in phases. In a hyper-converged cluster, it is used to protect application CPU and reduce the impact of noisy networking on storage I/O. In a disaggregated design, it can provide policy enforcement and isolation at the fabric edge, which is useful when many hosts share the same block storage back end.
In baremetal Kubernetes deployments, it can also help keep node-level performance more deterministic as clusters scale and as traffic patterns shift.
Related Technologies
These glossary terms are commonly reviewed alongside network offload on DPUs in NVMe/TCP and Kubernetes Storage environments.
Streamline Data Handling with SmartNICs
Infrastructure Processing Unit (IPU)
RDMA (Remote Direct Memory Access)
Improve Efficiency with Zero-copy I/O
Questions and Answers
By offloading network stack operations like TCP/IP processing, DPUs free up CPU cycles for core workloads. This results in lower latency, higher IOPS, and better throughput—especially when combined with NVMe over TCP for distributed storage.
DPUs can offload functions like packet processing, encryption, compression, firewalling, and NVMe-oF target handling. This enables secure, high-speed storage and networking in environments like Kubernetes without burdening the host CPU.
Yes, DPUs go beyond SR-IOV and SmartNICs by running full user-space applications on embedded cores. This allows full control over network, security, and storage offloads in software-defined infrastructure, such as software-defined storage.
In cloud-native stacks, DPUs improve performance isolation, reduce noisy neighbor issues, and enable secure multi-tenancy. When combined with storage offloads like NVMe-oF targets, they help scale containerized workloads with minimal overhead.
Yes, DPUs accelerate NVMe over Fabrics by handling the network and storage protocol entirely in hardware. This ensures high-throughput, low-latency storage access over standard Ethernet without relying on the host system’s CPU.