NVMe-oF Discovery Controller
Terms related to simplyblock
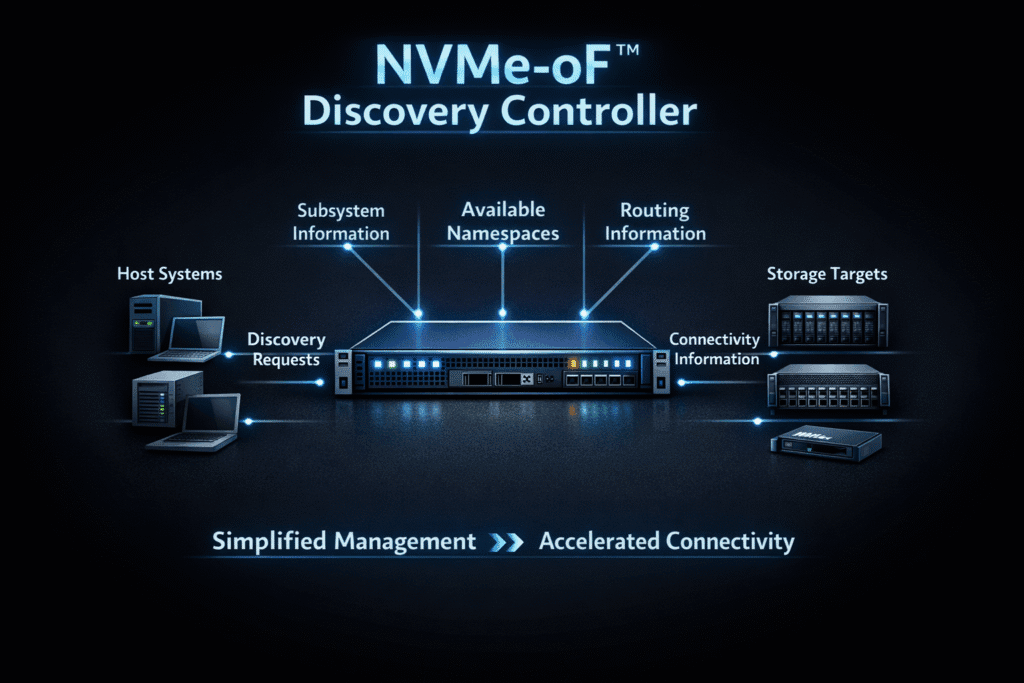
An NVMe-oF discovery controller helps a host find NVMe subsystems on a fabric without hardcoding every target address. A host connects to the discovery endpoint, requests the Discovery Log Page, and then uses the returned entries (like target address and subsystem NQN) to connect to the right I/O subsystem for data traffic.
Teams that run Kubernetes Storage across many nodes use this flow to reduce config drift and speed up node bring-up. It also supports steadier operations for Software-defined Block Storage, especially when platforms add, remove, or move NVMe/TCP targets during upgrades.
What the Discovery Controller Returns
The discovery controller returns Discovery Log Pages that list subsystem interfaces and the details a host needs for the next step. The nvme-cli documentation describes this behavior and calls out that the log includes items such as the network address and subsystem NQN.
This controller does not serve application reads and writes. It acts as a control-plane endpoint that points hosts to I/O subsystems. The NVM Express discovery automation material describes discovery as a “single location” that can report known subsystem interfaces and reduce admin work as the environment grows.
🚀 Automate NVMe/TCP Target Lookup for Kubernetes Storage
Use Simplyblock to simplify Kubernetes Storage and keep Software-defined Block Storage consistent at scale.
👉 Use Simplyblock for NVMe/TCP Kubernetes Storage →
How Hosts Use Discovery in Real NVMe/TCP Fabrics
Most hosts follow a short, repeatable sequence: connect to discovery, pull the discovery log, and then connect to the listed subsystems. Red Hat’s NVMe/TCP guidance shows this flow using nvme discover and nvme connect-all, along with options for persistent connections.
At scale, discovery reduces the number of moving parts you must track on every node. Instead of pushing static connect strings into bootstrap scripts, you keep one discovery endpoint stable and update the discovery records as storage changes. That pattern tends to lower “works on some nodes” failures during fleet rollouts.
Why NVMe-oF Discovery Controller Matters for Kubernetes Storage Operations
Kubernetes clusters change often. Nodes rotate, pools expand, and platform teams roll updates during business hours. Discovery helps because each node can learn current target endpoints at attach time, which cuts the risk of stale configuration causing volume attach delays.
NVMe/TCP fits this story because it runs over standard TCP/IP networks. Red Hat documents NVMe/TCP configuration steps and the discovery/connect workflow, which aligns with routable networks that many enterprises already operate. For CSI-focused setups, simplyblock’s Block Storage CSI glossary page frames CSI as the Kubernetes mechanism for provisioning and attaching block volumes through StorageClass, PV, and PVC workflows.
Direct vs Central Discovery – Two Common Patterns
Teams usually implement one of two patterns:
Direct discovery ties discovery to a given subsystem and reports interfaces for that subsystem. Central discovery aggregates interfaces across subsystems and can also provide referrals to other discovery controllers. The NVM Express discovery automation paper outlines these ideas, including the “referral” concept. Dell’s NVMe/TCP overview also discusses direct discovery and how the discovery log provides an inventory of subsystems and endpoints.
Choose direct discovery when you want fewer components. Choose Central Discovery when you want a single place to manage what hosts should see across a larger fabric.
Day-2 Signals You Should Track
Discovery problems often manifest as slow attachments, retries, and uneven node behavior. Track the outcomes that leaders and operators both care about: time-to-attach after node boot, connect error rate, and p95/p99 “storage ready” time during rolling updates.
You can also tighten your runbooks around the same commands you use in production. Red Hat shows how /etc/nvme/discovery.conf It can drive repeatable discovery and how nvme connect-all It completes the connection step.
Ops checklist (single listicle):
- Test discovery reachability (routing, ACLs, MTU, and the TCP port used in your design).
- Confirm the node sees the expected subsystem NQNs in the Discovery Log Page before bulk connects.
- Remove stale entries during decommissioning so nodes do not waste time on dead endpoints.
- Separate “discovery ok” from “I/O connect ok” in dashboards so teams can isolate failures fast.
- Re-test the attachment timing during upgrades because upgrades often change endpoints or policies.
Choosing an NVMe-oF Discovery Controller Approach
A quick way to think about the choice: discovery gives you a standards-based lookup step, while static connect strings trade long-term stability for short-term speed.
Here’s a simple decision table that aligns with Kubernetes Storage and Software-defined Block Storage operations:
| Option | What it optimizes | What you trade off | Typical fit |
|---|---|---|---|
| NVMe-oF discovery controller | Standard lookup and automation | You must operate a discovery endpoint | Most production NVMe/TCP fleets |
| Static connect strings | Fast initial setup | High drift and manual updates | POCs and short-lived tests |
| Vendor-specific discovery service | Added features | Portability and lock-in risk | Single-vendor estates |
Simplyblock™ and Discovery-Ready NVMe/TCP for Kubernetes Storage
Simplyblock™ delivers Software-defined Block Storage for Kubernetes Storage with NVMe/TCP as a primary transport, which helps platform teams standardize how nodes attach to remote NVMe targets at scale. Teams that operate multi-cluster or fast-changing environments often pair discovery-driven attach flows with consistent storage policies, so new nodes come online without brittle, host-by-host configuration.
For performance-sensitive workloads, simplyblock also emphasizes SPDK-based design principles that keep more of the I/O path in user space. That approach can reduce CPU overhead and help stabilize tail latency for NVMe and NVMe-oF workloads, especially when clusters run dense, mixed tenancy.
Where Discovery Goes Next
Teams now push discovery into automation instead of runbooks. The NVM Express discovery automation paper frames discovery as a way to centralize interface reporting and reduce manual admin, which maps cleanly to infrastructure-as-code practices.
As NVMe/TCP expands across more routable networks, discovery increasingly becomes the default control-plane step for attaching storage at scale.
Related Terms
Teams often review these simplyblock glossary pages alongside NVMe-oF Discovery Controller when they set targets for Kubernetes Storage and Software-defined Block Storage.
Block Storage CSI
Network Storage Performance
NVMe Latency
NVMe-oF Target on DPU
Questions and Answers
An NVMe-oF Discovery Controller simplifies host-side configuration by automatically providing connection details for available NVMe subsystems. It’s key to scalable NVMe over TCP deployments in Kubernetes and dynamic cloud environments.
In Kubernetes, the Discovery Controller allows CSI drivers to auto-discover and connect to NVMe targets without manual setup. This accelerates dynamic persistent volume provisioning and improves storage scalability across nodes.
In NVMe over TCP setups, the Discovery Controller automates the process of discovering available namespaces and paths. This enables faster failover, better resiliency, and simplifies host configuration at scale.
Yes, it helps isolate and advertise only the appropriate namespaces to authorized clients, improving security in multi-tenant storage environments while keeping discovery automated and efficient.
By eliminating manual host configuration, the Discovery Controller allows dynamic scaling of storage backends, which is critical in software-defined storage architectures and Kubernetes-native infrastructure.