NVMe over Fabrics Transport Comparison
Terms related to simplyblock
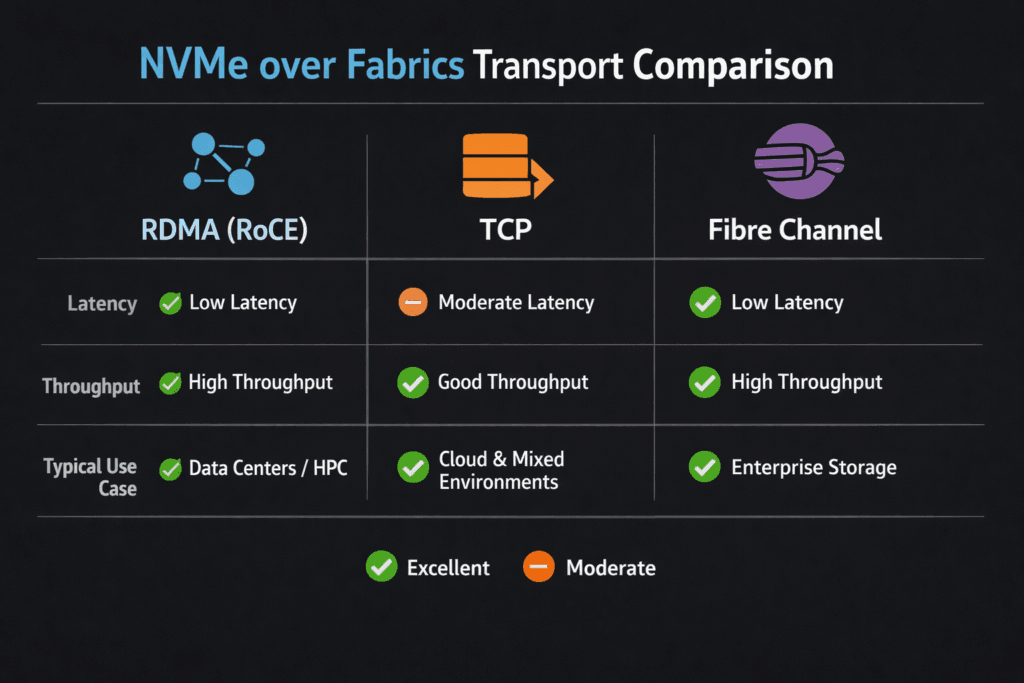
NVMe over Fabrics (NVMe-oF) extends NVMe block commands across a network, so compute and storage can scale on separate nodes. In an NVMe over Fabrics Transport Comparison, teams evaluate how each transport affects latency, CPU use, throughput, failure behavior, and day-2 operations. The common choices include NVMe/TCP, NVMe/RDMA over Ethernet (often via RoCEv2), and NVMe/FC on Fibre Channel.
NVMe-oF decisions also shape how you run Kubernetes Storage. A transport can look great in a lab and still struggle under multi-tenant cluster load if CPU headroom, network design, or retries drift. The best comparison focuses on repeatable outcomes, not only peak numbers.
Why an NVMe over Fabrics Transport Comparison Matters for Enterprise Storage
A transport choice sets the “cost per I/O” in real life. Some transports demand strict network tuning to hit low latency. Others trade a bit of latency for easier rollout on standard Ethernet. Most teams care about three checks: stable p99 latency for databases, enough throughput for batch lanes, and a path that scales without turning every change into a fabric project.
This is also where Software-defined Block Storage helps. It adds policy controls—QoS, tenant isolation, and failure-domain rules—so your chosen transport delivers predictable service levels across teams, not just best-case throughput.
🚀 Compare NVMe-oF Transports on NVMe/TCP, Natively in Kubernetes
Use simplyblock to run Kubernetes Storage on Software-defined Block Storage and validate transport impact with real workloads.
👉 Optimize Kubernetes Storage with NVMe/TCP →
NVMe over Fabrics Transport Comparison for Kubernetes Storage Operations
Kubernetes Storage changes the comparison because it adds scheduling and shared-node effects. Pod placement can add hops. CPU limits can throttle initiators. Network noise can increase tail latency even when the storage media stays idle. So, run the comparison inside the cluster, with the CSI driver path and the same node types you run in production.
Transport choice also affects operational routines. NVMe/TCP often fits existing Ethernet ops, while RDMA paths may require deeper tuning and strict fabric rules. Fibre Channel shops may prefer NVMe/FC because it keeps familiar FC tooling and change control.
NVMe over Fabrics Transport Comparison and NVMe/TCP Behavior at Scale
NVMe/TCP runs on standard TCP/IP networks, which makes adoption easier in many data centers. It also supports disaggregated designs without a specialized fabric. In most deployments, NVMe/TCP performance depends on CPU sizing, NIC behavior, and stable network queues. When the CPU saturates, p99 latency often climbs first.
For teams that compare NVMe/TCP to iSCSI on the same network, simplyblock reports higher IOPS and lower latency for NVMe/TCP in its published comparison, which is a useful reference point for “baseline Ethernet storage” expectations.
Measuring NVMe-oF Transports Without Skewing the Result
A fair test uses the same workload shape and the same reporting across transports. Keep block size, read/write mix, job count, and queue depth consistent. Track p95 and p99 latency, not only averages, and record CPU and network use in the same time window. Use tools such as fio to model queue depth and mixed workloads.
- Define two profiles: one latency-first (small random I/O) and one throughput-first (large sequential I/O).
- Sweep queue depth in small steps, and capture the knee where latency rises faster than throughput.
- Run long enough to hit steady state, then repeat to confirm stability.
- Re-test after kernel, NIC, or CSI changes, and compare deltas instead of single-run peaks.
Transport Choice Levers That Move Latency, CPU, and Risk
RDMA-based transports can deliver lower latency and lower host CPU overhead, but they often demand stricter network conditions. RoCEv2 design choices, such as congestion control and loss handling, can decide whether results stay stable under load.
NVMe/FC can be a strong fit when you already run Fibre Channel and want NVMe semantics while keeping the FC operational model. It typically avoids many Ethernet tuning questions, but it keeps FC-specific hardware and processes in the stack.
Transport Comparison Matrix for NVMe-oF Deployments
The table below summarizes tradeoffs that matter in day-2 operations and Kubernetes Storage rollouts.
| NVMe-oF transport | Typical strengths | Common tradeoffs | Best-fit environments |
|---|---|---|---|
| NVMe/TCP | Works on standard Ethernet, broad compatibility, strong scale-out story | Kubernetes fleets, mixed workloads, and fast rollout needs | Works on standard Ethernet, broad compatibility, and strong scale-out story |
| NVMe/RDMA (RoCEv2) | Very low latency, lower CPU overhead | Requires stricter fabric tuning and congestion control | Latency-critical lanes, tightly managed networks |
| NVMe/FC | Leverages FC tooling, consistent behavior in FC shops | Specialized FC hardware and workflows remain | Existing FC estates, strict change control |
Using Simplyblock™ to Standardize NVMe-oF Transport Choices
Simplyblock™ supports NVMe-oF with a focus on NVMe/TCP, plus NVMe/RoCE options, and it pairs the transport with Software-defined Block Storage controls such as multi-tenancy and QoS. Its NVMe-oF and SPDK feature page highlights SPDK-based, user-space design for efficient I/O paths, which helps reduce overhead and improve consistency under concurrency.
For Kubernetes Storage, the CSI driver integration lets platform teams apply consistent policies while they compare transports across clusters and workloads.
Where NVMe-oF Transport Decisions Are Heading
Many teams standardize on NVMe/TCP for broad Ethernet-based deployment, then introduce RDMA where tail latency targets demand it. Fibre Channel environments often evaluate NVMe/FC as an evolution path that keeps existing fabric practices.
Over time, continuous testing in-cluster will matter more than vendor peak charts, especially as multi-tenant platforms tighten p99 targets.
Related Terms
Teams often review these alongside NVMe over Fabrics Transport Comparison when they set targets for Kubernetes Storage and Software-defined Block Storage.
Questions and Answers
NVMe over Fabrics (NVMe-oF) supports multiple transport protocols, including TCP, RDMA (RoCE/Infiniband), and Fibre Channel. Each differs in performance, hardware requirements, and deployment complexity. TCP is the most flexible; RDMA offers ultra-low latency; Fibre Channel supports legacy SAN upgrades.
NVMe over TCP runs on standard Ethernet and requires no special hardware, making it easier to deploy at scale. NVMe over RDMA offers lower latency but depends on lossless networks and RDMA-capable NICs. TCP is ideal for Kubernetes and cloud-native platforms.
NVMe over Fibre Channel (NVMe/FC) allows reuse of existing Fibre Channel infrastructure, but it involves high costs and vendor lock-in. It delivers good performance but lacks the openness and flexibility of NVMe/TCP, which is better suited for modern software-defined storage environments.
For Kubernetes environments, NVMe over TCP is preferred due to its simplicity, native kernel support, and ability to run over standard Ethernet. It balances performance and manageability, unlike RDMA or Fibre Channel, which require more complex networking and tuning.
Simplyblock is built on NVMe over TCP, offering high-performance, encrypted, and scalable storage over commodity networks. Its CSI integration makes it ideal for Kubernetes, VMs, and distributed applications—without requiring RDMA or Fibre Channel hardware.