NVMe over TCP Architecture
Terms related to simplyblock
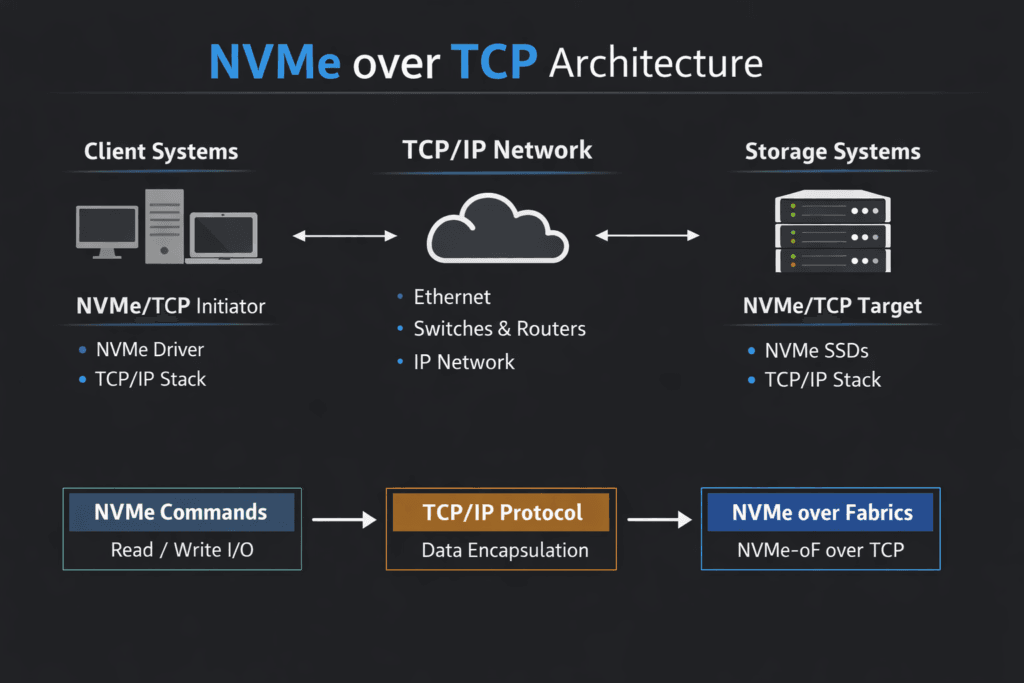
NVMe over TCP Architecture describes how NVMe-over-Fabrics maps NVMe commands and data onto standard TCP/IP networks. Hosts act as initiators, targets expose namespaces, and each queue pair maps to TCP connections for parallel I/O. This design keeps deployment practical because it uses Ethernet, familiar routing, and common ops tooling.
In enterprise platforms, the architecture matters less as a diagram and more as a set of outcomes: stable latency, predictable scale, and simple failure handling. Teams often adopt NVMe/TCP when they need fast block access without the fabric demands of RDMA or Fibre Channel.
Designing NVMe/TCP fabrics for real-world clusters
A clean NVMe/TCP setup starts with the network because the network becomes the backplane. Keep MTU consistent, size east-west bandwidth for peak load, and avoid oversubscription where storage traffic competes with service mesh or replication bursts. You also want clear boundaries between storage and tenant traffic so you can troubleshoot fast when latency moves.
On the storage side, plan your target layout and namespace strategy early. A consistent mapping model helps automation, reduces drift, and makes access rules easier to audit. Strong subsystem design also improves multi-tenant behavior in Software-defined Block Storage, especially in Kubernetes Storage, where workloads move often.
🚀 Standardize Networked NVMe Storage Across Your Cluster
Use Simplyblock to run Software-defined Block Storage with tenant-safe QoS for Kubernetes Storage.
👉 Talk to Simplyblock about NVMe/TCP at Scale →
NVMe over TCP Architecture in Kubernetes Storage
Kubernetes Storage adds two constraints: dynamic lifecycle and shared tenancy. Pods restart, nodes drain, and volumes must attach and mount without human steps. NVMe/TCP fits well when the storage layer integrates through CSI and keeps volume operations fast and repeatable.
A solid pattern uses StorageClasses to express intent, such as performance tier, replication, or snapshot behavior. The control plane then maps that intent to volumes, namespaces, and connectivity rules. That mapping stays stable even when the scheduler moves pods, which protects application SLOs.
This is where Software-defined Block Storage matters. It lets platform teams apply policy at the volume level, so one noisy namespace does not push p99 latency over budget for the rest of the cluster.
NVMe over TCP Architecture and NVMe/TCP data paths
NVMe/TCP carries NVMe command and data capsules over TCP, which makes it broadly deployable on standard Ethernet. The spec also defines optional features like digests and TLS to support integrity and security needs.
Performance depends on how well you handle parallelism. Multiple queue pairs and multiple TCP flows can raise throughput when you align them with CPU cores and NIC queues. Multipathing adds resilience and can improve utilization when you configure path policies carefully.
CPU cost still matters. Packet work can limit throughput before SSDs hit their ceiling, so teams should measure CPU per I/O and tune interrupt and NUMA placement. That is why many modern stacks lean on user-space I/O paths, such as SPDK-style designs, to reduce overhead and keep latency steady under load.
Benchmarking NVMe over TCP Architecture performance in production-like tests
Avoid “one-number” testing. Use repeatable profiles that match your apps, then track both throughput and tail latency. p95 and p99 latency usually drive user impact, especially for databases and queues. Run tests through the same path your apps use, including Kubernetes, CSI, and the network, because each layer adds variance.
Add failure scenarios. Pull a node, break a path, and trigger recovery. Watch how long the system takes to heal and how latency behaves during rebuild. That view tells you more than a clean lab run.
Tuning levers that improve throughput without hurting latency
Most improvements come from tightening the end-to-end path and controlling contention:
- Align NIC queues, CPU pinning, and NUMA locality so packet work stays predictable at high concurrency.
- Use multipathing with clear policies to balance traffic and handle path loss cleanly.
- Separate workload tiers with QoS so batch scans do not choke log writes in shared clusters.
- Standardize MTU and congestion behavior across racks to reduce jitter during bursts.
- Validate p99 latency under mixed read/write load, not only pure reads.
Transport and architecture comparison for networked NVMe block storage
The table below compares common approaches teams consider when they design a SAN alternative for Software-defined Block Storage.
| Option | Network needs | Ops effort | Typical latency pattern | Fit for Kubernetes Storage |
|---|---|---|---|---|
| iSCSI | Standard Ethernet | Medium | Higher, less parallel | Works, but not NVMe-native |
| NVMe/FC | Fibre Channel fabric | Higher | Low, consistent | Works, depends on FC ops |
| NVMe/RDMA (RoCE) | RDMA-capable Ethernet | Higher | Lowest, tight tail | Strong for strict budgets |
| NVMe/TCP | Standard Ethernet | Medium | Low when tuned | Strong balance of speed and deployability |
Predictable outcomes with simplyblock™ for NVMe/TCP deployments
Simplyblock™ focuses on predictable behavior for NVMe/TCP in Kubernetes Storage and baremetal clusters. It uses an SPDK-based, user-space, zero-copy data path to reduce overhead and improve CPU efficiency under concurrency.
Teams deploy simplyblock as Software-defined Block Storage, then choose hyper-converged, disaggregated, or hybrid layouts based on cost and risk targets. The platform also supports multi-tenancy and QoS controls, which help keep one workload from reshaping the latency profile of the whole cluster.
Where NVMe/TCP architectures are heading next
Expect more automation around discovery, connection lifecycle, and fleet policy, especially as Kubernetes clusters grow. Offload will also expand. DPUs and SmartNICs can take on more packet and storage work, which lowers CPU cost per I/O and improves consolidation.
Research and vendor tooling continue to improve visibility into NVMe/TCP behavior, which helps teams tune faster and avoid blind spots.
Related Terms
Teams reference these terms when planning NVMe over TCP Architecture for Kubernetes Storage and Software-defined Block Storage.
Questions and Answers
NVMe over TCP extends the NVMe protocol over standard Ethernet using TCP/IP. It enables remote access to high-performance NVMe drives without needing Fibre Channel or RDMA. The architecture consists of initiators, target nodes, and a TCP/IP transport layer that maintains low latency and high throughput.
The architecture includes NVMe-enabled storage targets, TCP-compatible network interfaces, and initiators (clients) with kernel support. Platforms like Simplyblock abstract this complexity and provide CSI-integrated NVMe storage for Kubernetes, VMs, and bare metal servers.
Unlike NVMe/FC or NVMe/RDMA, NVMe over TCP uses standard Ethernet and doesn’t require specialized network hardware. While slightly higher in latency than RDMA, it balances performance with cost-efficiency, making it the most accessible NVMe-oF implementation.
NVMe over TCP achieves microsecond-level latency and high IOPS comparable to direct-attached NVMe. When combined with multi-queue support and optimized tuning, it can outperform traditional iSCSI-based SANs, even over shared networks.
Simplyblock uses NVMe over TCP to provide distributed, software-defined block storage. It delivers encrypted, high-performance volumes over Ethernet with features like replication, snapshots, and CSI integration—ideal for multi-tenant Kubernetes environments and modern infrastructure.