NVMe Partitioning
Terms related to simplyblock
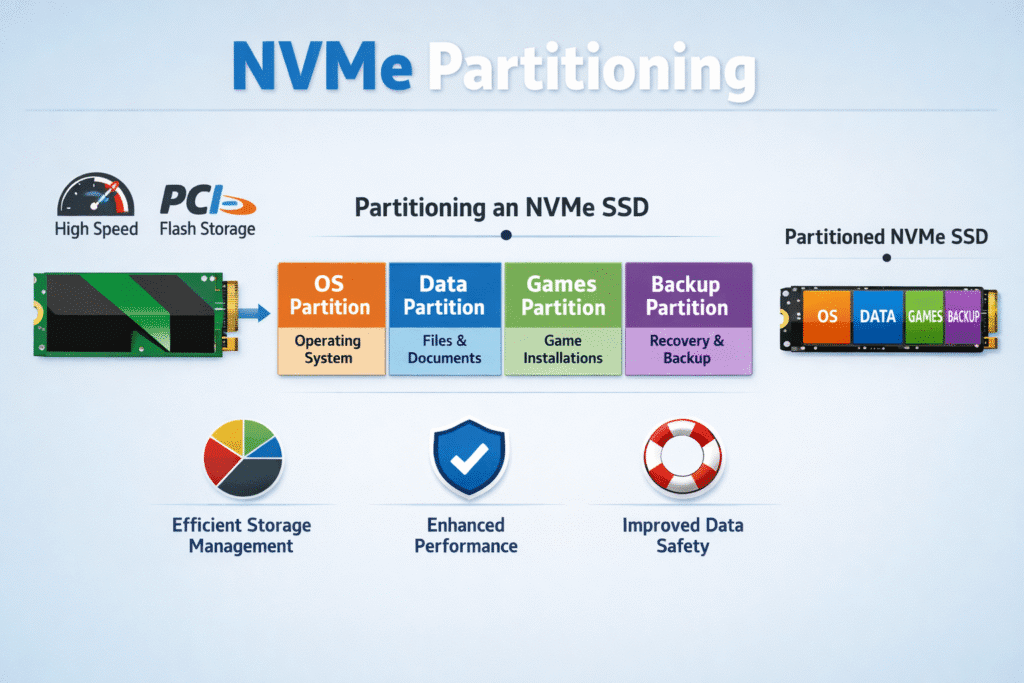
NVMe Partitioning usually means splitting an NVMe SSD into multiple slices so different workloads do not fight for the same space or queue. Most teams do this in two ways: they create OS-level disk partitions, or they carve the drive into NVMe namespaces at the controller level. Disk partitioning creates regions that the operating system manages through a partition table. NVMe namespaces create separate logical block address ranges that the controller presents to the host as separate devices, which often fits multi-tenant designs better.
In Kubernetes Storage, the “right” split depends on how you provision volumes, how you isolate tenants, and how you plan for failures. A partition scheme that looks clean on paper can still produce noisy-neighbor latency if you lack QoS controls at the volume level. That is why executives often evaluate partitioning alongside Software-defined Block Storage policy, not as a standalone task.
When NVMe Partitioning Helps and When It Hurts
NVMe Partitioning helps when you need clear boundaries for ownership, chargeback, or blast-radius control. It also helps when one host must run several tenants, and each tenant needs a separate block device.
Problems start when teams treat partitioning as performance isolation. A Linux partition does not automatically give you consistent tail latency, and a small partition can still generate heavy write bursts. The storage layer must shape I/O to keep p95 and p99 stable, especially during rebuilds and snapshot activity.
If you want a controller-native boundary, NVMe namespaces give you a stronger unit of control than classic partitions in many NVMe designs. A namespace maps to a defined range of logical blocks, and the controller exposes it to the host as addressable space.
🚀 Standardize NVMe Partitioning with Namespaces for Kubernetes Storage
Use simplyblock to manage NVMe namespaces and map volumes cleanly to NVMe/TCP-backed Software-defined Block Storage.
👉 Configure NVMe Namespaces with simplyblock →
NVMe Partitioning in Kubernetes Storage Node Designs
In Kubernetes, partition choices impact scheduling, provisioning, and recoverability. Local NVMe can boost performance, but Pods may lose that data when Kubernetes moves them, so teams often reserve local layouts for cache, scratch, or workloads that tolerate relocation. Networked block storage usually reduces that risk, because volumes move independently of a single node and still show up as standard Persistent Volumes.
Many platform teams still partition NVMe on worker nodes to support multiple local volumes, but that approach adds operational work during node replacement and upgrades. A Software-defined Block Storage layer can simplify the model by pooling devices and presenting consistent volumes through CSI, which aligns better with dynamic provisioning workflows.
One practical constraint in some platforms: they want clean, dedicated NVMe devices and do not rely on OS partitions for data devices. This matters when teams arrive with a “partition everything” baseline and then want deterministic storage behavior.
NVMe Partitioning and NVMe/TCP Volume Access
NVMe/TCP extends NVMe semantics over standard Ethernet, which makes it attractive for disaggregated designs and SAN alternative builds. When you export storage over NVMe/TCP, namespaces become a natural control unit. You can map volumes to namespaces, apply policies per volume, and avoid mixing unrelated workloads inside one block device.
This is also where queue behavior and CPU cost show up. A clean user-space data path can reduce overhead and help keep latency tight under load. That approach supports high-performance Software-defined Block Storage in Kubernetes.
For environments that use many targets and many namespaces, discovery workflows also matter. Discovery services reduce manual host configuration and help keep fleet operations consistent as deployments grow.
Measuring and Benchmarking NVMe Partitioning Performance
Benchmark partition choices the same way production will hit them. Measure steady-state load, burst load, and mixed read/write. Report average latency, plus p95 and p99. Also report CPU per I/O, because overhead often decides how many Pods you can run per node.
If you use NVMe namespaces, validate behavior at the namespace level, not only at the raw drive level. In Kubernetes, review how your Persistent Volumes bind and attach, because the control plane behavior influences time to ready as much as device speed.
Operational Practices That Keep Performance Stable
These steps usually reduce incidents while keeping the design simple. They apply to both local layouts and NVMe/TCP-backed volumes, and they pair well with volume-level QoS.
- Keep OS partitions minimal, and avoid mixing storage system devices with host filesystems.
- Prefer NVMe namespaces when you need clean boundaries on the same drive, and keep naming consistent.
- Track tail latency during maintenance work, not only during quiet windows.
- Use volume or tenant QoS controls so one workload cannot saturate the device.
- In Kubernetes, align provisioning to the PV/PVC lifecycle and verify attach behavior during drains.
Storage Model Trade-Offs for Local Slices and Controller-Level Isolation
The table below summarizes common ways teams split NVMe capacity and what each method buys you in day-to-day operations.
| Method | Where the split happens | What you gain | Common downside |
|---|---|---|---|
| OS disk partitions | OS partition table | Simple local separation | Weak performance isolation by itself |
| NVMe namespaces | NVMe controller | Clear logical devices, better fit for per-volume control | Needs namespace-aware tooling and workflow |
| Pooled volumes via SDS | Storage layer | Central policy, QoS, portability across nodes | Requires a storage platform and ops discipline |
Policy-Driven NVMe Isolation with Simplyblock™
Simplyblock™ focuses on predictable Kubernetes Storage by using a Software-defined Block Storage control plane and an NVMe-first design that supports NVMe/TCP. Instead of treating OS partitions as the primary split, simplyblock uses NVMe-centric constructs and exposes volumes that Kubernetes can consume through CSI.
This model fits governance and cost control goals while giving platform teams a cleaner unit for QoS and multi-tenancy. It also reduces the temptation to “solve” performance isolation with host slicing.
Future Directions for Partitioning – Namespaces, Offload, and Policy
NVMe keeps adding features that make namespace-level control more useful over time. In parallel, more teams push storage protocol work closer to the network edge with DPU-based targets, which can reduce host CPU load and tighten latency in dense clusters.
The long-term trend favors policy-driven control over ad hoc host slicing, especially in Kubernetes estates that need consistent behavior across fleets.
Related Terms
Teams often review these glossary pages alongside NVMe Partitioning when they plan Kubernetes Storage on NVMe/TCP and enforce Software-defined Block Storage controls.
NVMe Namespace
NVMe-oF Discovery Controller
Persistent Volume
Storage Quality of Service (QoS)
Questions and Answers
NVMe partitioning allows you to segment high-performance drives for dedicated tasks like databases, caches, or logs. In environments like Database-as-a-Service, isolating workloads on separate partitions helps reduce contention, maintain consistent IOPS, and improve tenant-level performance.
When using NVMe in Kubernetes, partitions should align with pod and volume claims for optimal performance. Combine this with a CSI driver that supports node-level scheduling to ensure local access, minimize latency, and maximize utilization of each partition.
Yes. By right-sizing NVMe partitions per workload, you avoid overprovisioning and reduce wasted space. This is especially valuable in cloud cost optimization strategies, where granular control over volume allocation helps cut expenses without compromising performance.
Absolutely. Modern software-defined storage solutions support logical partitioning and volume mapping, allowing you to carve out high-performance sections of an NVMe drive and assign them dynamically—ideal for cloud-native, scalable environments.
Admins commonly use tools like fdisk, parted, or nvme-cli for low-level partitioning. In cloud-native platforms, automated provisioning through CSI and orchestration tools enables dynamic NVMe volume creation. Simplyblock handles NVMe partitioning seamlessly through Kubernetes-native interfaces.