NVMe Subsystem
Terms related to simplyblock
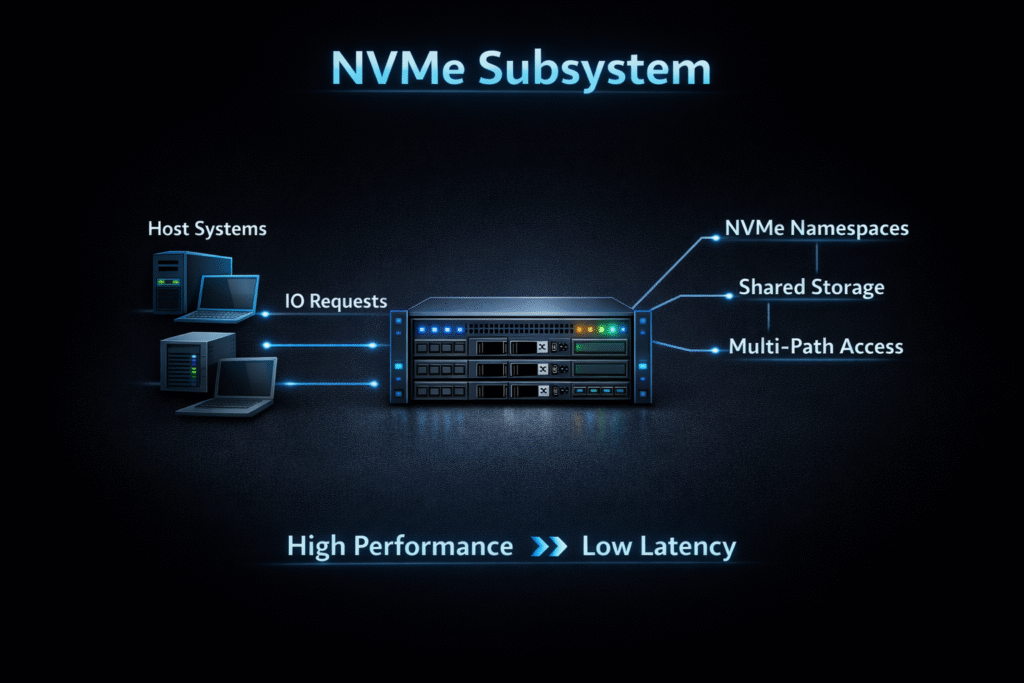
An NVMe Subsystem groups one or more controllers and one or more namespaces under a single NVMe identity so hosts can connect through a consistent NVMe interface. In NVMe-oF setups, teams usually identify the subsystem with an NQN (NVMe Qualified Name), then expose namespaces through one or more controllers across the fabric.
Executives care because the subsystem boundary often becomes the control point for access, tenancy, and performance policy in Software-defined Block Storage, especially when you replace a traditional SAN with a software-driven design.
Designing NVMe Subsystem Architecture for Scale-Out Storage
Start with a clear mapping model: define which hosts can connect, which controllers they see, and which namespaces each controller exposes. That clarity reduces operational drift when you scale from a few nodes to many racks.
Next, minimize per-I/O overhead so the subsystem keeps latency stable at high queue depths. SPDK-style user-space I/O paths cut kernel work and boost IOPS per core, which helps on baremetal nodes that run dense storage and network traffic.
Finally, treat the NVMe Subsystem as the unit you standardize. When you lock down naming, access rules, and namespace layout, you simplify automation across clusters and environments.
🚀 Run NVMe Subsystems over NVMe/TCP for Kubernetes Storage
Use simplyblock to standardize subsystem design, reduce CPU overhead, and keep p99 latency stable at scale.
👉 Use simplyblock for NVMe/TCP Storage on Kubernetes →
Aligning Controllers and Namespaces with Kubernetes Storage
In Kubernetes Storage, applications request capacity and behavior through StorageClasses and PersistentVolumeClaims, while the platform maps those requests to actual block volumes. Your storage layer can map each Kubernetes volume to an NVMe namespace while keeping controller access rules consistent as pods move.
Kubernetes scheduling also changes performance behavior. The system can place a workload on a different node in minutes, so the storage path needs to stay predictable across reschedules. Strong namespace design and clean subsystem access rules support that goal.
This model fits multiple layouts. You can run hyper-converged storage for locality, disaggregated storage for independent scaling, or a hybrid mix when different workloads demand different failure domains.
Transport Choices over NVMe/TCP Fabrics
NVMe/TCP sends NVMe commands over standard TCP/IP networks, so teams can deploy NVMe-oF on common Ethernet without RDMA-only fabrics. That deployability matters in large Kubernetes fleets where network simplicity often beats exotic tuning.
RDMA transports can push latency lower, but they also raise fabric requirements and tighten operational guardrails. Many teams standardize on NVMe/TCP first, then use RDMA only where the latency budget forces the choice.
Benchmarking Subsystem Behavior – IOPS, Latency, and CPU
Benchmark the NVMe Subsystem end-to-end, including host, network, target, and media. Track IOPS and throughput, then pay close attention to tail latency because p95 and p99 often drive user impact.
CPU cost per I/O also matters, especially for NVMe/TCP. Packet processing can become the limiter long before the SSDs run out of headroom, so measure host CPU and interrupt pressure during tests.
Most teams use fio to run repeatable workloads. Use a small set of standard profiles that mirror real applications, and run them through the same CSI path your apps use inside Kubernetes Storage. That approach catches scheduling, networking, and multi-tenant effects early.
Practical Tuning Levers for Higher Performance
Use one tuning playbook and apply it consistently across clusters, tenants, and upgrades:
- Pin storage dataplane threads and NIC interrupts to the right NUMA node, and keep traffic local when possible.
- Enforce QoS at the volume or tenant level to protect tail latency and stop noisy neighbors in Kubernetes Storage.
- Standardize fio job files for your key applications, then treat those profiles as release gates.
- Align MTU, RSS, and congestion settings across the fabric when you run NVMe/TCP at scale.
- Validate p99 latency under mixed read/write load before you commit to an SLA.
Transport and Deployment Options Compared
Subsystem semantics stay consistent, but transport and placement choices change day-two operations and performance variance. The table below summarizes common options for Software-defined Block Storage and Kubernetes Storage.
| Option | Typical latency profile | Network requirements | Ops complexity | Fit for Kubernetes Storage | Notes |
|---|---|---|---|---|---|
| Local PCIe NVMe | Lowest | None | Low | Medium | Fast, but ties storage to compute locality |
| NVMe-oF over TCP (NVMe/TCP) | Low when tuned | Standard Ethernet | Medium | High | Strong balance of speed and deployability |
| NVMe-oF over RDMA | Lowest over fabric | RDMA-capable network | Higher | Medium–High | Great for tight latency budgets, with more fabric work |
| iSCSI (non-NVMe baseline) | Higher | Standard Ethernet | Medium | Medium | Uses SCSI LUNs, not NVMe namespaces/subsystems |
Making NVMe Subsystem SLAs Real with Simplyblock™
Simplyblock™ helps teams standardize NVMe Subsystem design for Software-defined Block Storage by combining an SPDK-based, user-space dataplane with Kubernetes-native control. Operators can enforce performance intent per volume while keeping clean subsystem boundaries across multi-tenant clusters. Teams deploy simplyblock in hyper-converged, disaggregated, or mixed modes, then run NVMe Subsystem connectivity over NVMe/TCP with a clear path to RDMA where it fits.
Simplyblock also applies multi-tenancy and QoS controls at the volume layer that map cleanly to NVMe Subsystem exposure patterns, which reduces noisy-neighbor impact and stabilizes p99 latency during cluster growth. The platform keeps baremetal efficiency while fitting day-two Kubernetes workflows like rolling upgrades, node drains, and reschedules.
Roadmap – DPUs, Offload, and Next-Gen NVMe Subsystem at Scale
DPUs and SmartNICs will offload more packet and storage work from host CPUs, which lowers CPU cost per I/O and improves consolidation for each NVMe Subsystem presented to applications. That shift also strengthens NVMe/TCP for Kubernetes Storage because teams can keep Ethernet operations straightforward while still driving demanding performance targets per subsystem.
NVMe-oF tooling will keep improving around discovery, connection lifecycle, and fleet automation, which helps teams manage NVMe Subsystem identities (such as NQNs), rotate infrastructure safely, and keep subsystem access consistent across upgrades and expansions.
Related Terms
Teams often review these glossary pages alongside NVMe Subsystem when they define subsystem boundaries, validate transport choices, and set measurable targets for Kubernetes Storage and Software-defined Block Storage.
Kubernetes Block Storage
NVMe over RoCE
Storage Area Network (SAN)
Zero-Copy I/O
Questions and Answers
An NVMe Subsystem is a logical unit that contains one or more NVMe namespaces along with controllers, allowing hosts to connect and access data. It’s a core part of NVMe over Fabrics and enables scalable, high-performance storage infrastructure.
In Kubernetes, NVMe Subsystems are exposed via CSI drivers to enable dynamic persistent volume provisioning. This ensures low-latency, high-throughput access for stateful applications like databases or analytics engines.
Yes, a single NVMe Subsystem can include multiple namespaces, each acting as an independent block device. This supports multi-tenant software-defined storage and allows for better resource isolation and flexibility.
Each NVMe Subsystem includes controllers that manage the communication between hosts and namespaces. These controllers handle I/O commands and path management—especially critical in NVMe multipathing scenarios for performance and resilience.
In NVMe over Fabrics, hosts can discover available subsystems using the NVMe-oF Discovery Controller. This enables automated connection to appropriate storage targets in large-scale cloud-native deployments.