Overprovisioning in Storage
Terms related to simplyblock
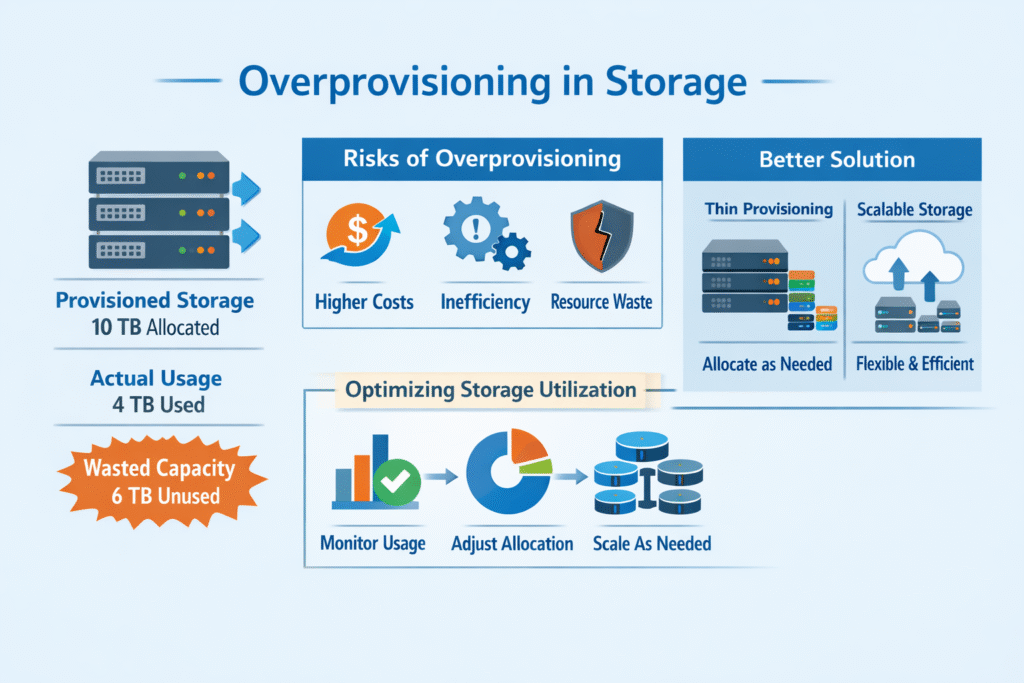
Overprovisioning in storage means you allocate or “promise” more capacity (or performance) than you physically hold, or you buy far more than you use. Teams do this to stay safe during growth, but it can inflate costs, increase operational risk, and hide performance debt.
Two common forms show up in real systems:
Logical over-allocation (often through thin provisioning), where apps see large volumes while the backend allocates blocks only when data lands.
Device spare area on SSDs, where you reserve free flash space to reduce garbage collection pressure and stabilize latency.
Making Overprovisioning Practical Without Wasting Budget
Executives usually care about predictability (cost and SLOs), while Ops teams care about guardrails (alerts, throttles, and safe growth). The best strategy combines policy, telemetry, and an architecture that keeps performance stable when utilization rises.
Software-defined Block Storage helps here because it can enforce allocation rules and track real consumption without tying you to a proprietary array.
What metrics define “safe” headroom?
Track allocated vs used capacity, oversubscription ratio, thin-pool free space, and peak daily growth. Pair those numbers with p95/p99 latency so you see risk before users feel it.
🚀 Cut Storage Overprovisioning with Thin Provisioning and Pooling
Use simplyblock to stop paying for unused capacity while keeping predictable performance.
👉 Use simplyblock to avoid storage over-provisioning →
Overprovisioning in Storage for Kubernetes Storage Teams
Kubernetes Storage often pushes teams into accidental overprovisioning. A PersistentVolumeClaim (PVC) sets an up-front size that many apps never fill, especially dev, staging, and tenant-per-customer patterns. StorageClasses and dynamic provisioning help, but you still need feedback loops that keep requests close to real use.
A simple pattern reduces waste: start smaller, monitor growth, then expand volumes when usage justifies it. Kubernetes supports volume expansion for many CSI backends, so teams can avoid “guess big” sizing.
If you run multi-tenant platforms, add Storage QoS so one noisy tenant cannot burn shared capacity and I/O queues. That’s a practical control point for Software-defined Block Storage in Kubernetes.
Overprovisioning in Storage and NVMe/TCP Fabrics
When you disaggregate storage, you also disaggregate risk. NVMe/TCP makes high-performance networked storage practical on standard Ethernet, which lets you pool capacity instead of stranding it on individual nodes. NVM Express maintains the NVMe/TCP transport specification, and it explicitly targets both software and future hardware acceleration.
This matters for overprovisioning because pooled storage plus fast fabrics lets you right-size volumes and still meet latency goals. Combine NVMe/TCP with SPDK-style user-space I/O paths, and you reduce CPU overhead per I/O, which helps you keep performance steadier as utilization climbs.
Proving the Impact – How to Benchmark Capacity Headroom and Performance
Measure both “space economics” and “I/O behavior,” or you will optimize the wrong thing.
Use a repeatable workload (fio, vdbench, or your app replay) and track latency percentiles, not just average latency. Add CPU per I/O and queue depth so you can spot bottlenecks in the stack.
For thin provisioning scenarios, simulate growth by ramping used space over time and watch when latency spikes. SSD spare area and write amplification often show the inflection point.
What should you report to leadership?
Show three numbers side-by-side: allocated TB, used TB, and cost per usable TB at your target p99 latency. That ties overprovisioning directly to business outcomes.
Steps That Improve Utilization Without Surprises
Use one playbook across baremetal and cloud so teams do not reinvent policy per cluster. Keep it short, and enforce it with automation.
- Start PVCs smaller, then expand using CSI-backed volume expansion when growth proves demand.
- Use thin provisioning for shared pools, and alert on thin-pool free space early.
- Segment workloads with StorageClasses and enforce QoS per class to reduce noisy-neighbor risk.
- Use tiering for cold blocks so expensive NVMe capacity serves hot data, not archives.
- Reserve SSD free space intentionally on performance tiers to reduce write amplification under sustained writes.
Overprovisioning Approaches Side-by-Side
The table below compares common approaches teams use to manage overprovisioning and the trade-offs that show up in Kubernetes Storage operations.
| Approach | Primary goal | Main upside | Main risk | Best fit |
|---|---|---|---|---|
| Thick provisioning | Zero oversubscription | Simple capacity math | High waste, slow right-sizing | Regulated workloads with fixed sizing |
| Thin provisioning (shared pool) | Reduce waste | Better utilization, faster growth | Needs monitoring to avoid pool exhaustion | Multi-tenant platforms, dev/test |
| SSD spare-area overprovisioning | Stabilize latency | Lower write amplification under load | Less usable capacity per drive | Write-heavy databases, logs, WAL |
| Tiering + pooling | Reduce premium capacity use | Hot data stays fast, cold data gets cheap | Policy mistakes can move data too early | Mixed workloads, cost control |
| QoS + SLO policy | Protect tail latency | Predictable p99 behavior | Needs tuning and governance | Shared clusters, DBaaS |
Predictable Overprovisioning in Storage with Simplyblock™
Simplyblock targets predictable utilization and latency by combining NVMe/TCP pooling with Software-defined Block Storage controls that fit Kubernetes Storage realities. You can consolidate capacity into shared pools, apply QoS per tenant, and avoid “buy big” sizing just to hit an SLO.
The architecture emphasis matters: SPDK-based, user-space I/O paths cut kernel overhead and keep CPU use steadier under load, which helps when you run dense clusters or plan DPU offload paths.
Where Overprovisioning Controls Are Going Next
Teams want tighter control loops: allocate closer to real use, detect growth early, and protect p99 latency automatically. Expect more policy to move into the data path through DPUs and infrastructure offload so storage networking and security stop competing with application cores.
On the protocol side, NVMe specs keep evolving across transports and management features, which helps operators add stronger guardrails around reliability and efficiency in NVMe/TCP environments.
Related Terms
Teams often review these glossary pages alongside Overprovisioning in Storage when they set guardrails for Kubernetes Storage and Software-defined Block Storage.
Write Amplification
Thin Cloning
CSI Topology Awareness
Storage Rebalancing
Questions and Answers
Overprovisioning is the practice of allocating more virtual storage than the actual physical capacity, assuming not all workloads use their full allocation. It’s a common technique in virtualized environments to optimize resource utilization and reduce wasted capacity without upfront overcommitment.
While it can improve efficiency, aggressive overprovisioning risks resource exhaustion and degraded performance. In latency-sensitive setups, monitoring and capacity planning are critical. Using features like replication and snapshots can help mitigate risk and recover from failures if limits are hit.
Yes, but it must be tightly managed. In multi-tenant storage deployments, overprovisioning should be paired with quota enforcement and observability to prevent one tenant’s usage from impacting others.
Absolutely. Modern SDS platforms provide thin provisioning, dynamic volume resizing, and better usage insights—enabling safe overprovisioning without compromising performance or availability.
Use predictive monitoring, enforce storage quotas, and regularly audit usage patterns. Also, plan for sudden spikes by maintaining buffer capacity. Solutions like Simplyblock offer flexible provisioning tools that help balance utilization and cost across cloud or hybrid environments.