Persistent Volume Attachment Flow
Terms related to simplyblock
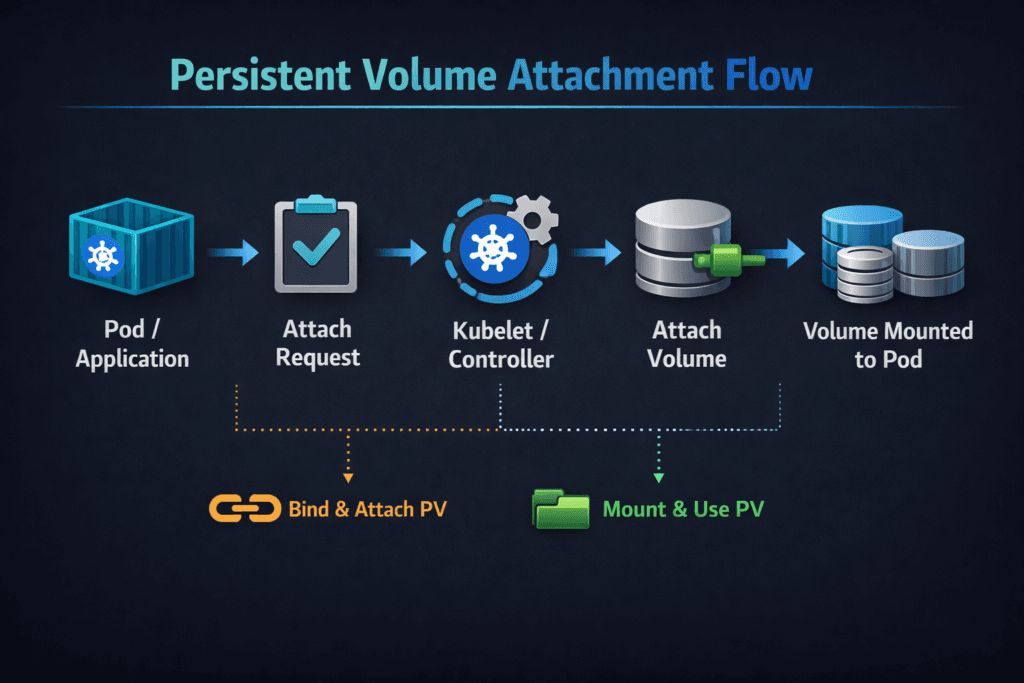
Persistent Volume Attachment Flow is the sequence Kubernetes follows to make a PersistentVolume available on the node where a pod runs. The flow starts when the scheduler places a pod. Next, Kubernetes records “attach intent” for the target node. After that, the storage driver and node components complete the publish and mount steps so the container can read and write data.
This flow gates pod readiness for stateful apps. A slow attach path stretches deploys, failovers, and rollbacks. A noisy attach path adds jitter during rolling updates and node drains. Both outcomes hit the same targets executives care about: release timing, recovery time, and service stability. Platform teams care because attached issues often look like “Kubernetes is stuck,” even when the real issue sits in the storage control loop or node path for Kubernetes Storage.
Optimizing Persistent Volume Attachment Flow with Current Tooling
Start by treating attachment as a lifecycle you can measure and tune. You want short control-loop time and stable node execution time. When those times swing, pods start late, and operators lose confidence in runbooks.
Good optimization also depends on the storage backend design. Software-defined Block Storage can reduce friction when it handles concurrency well and keeps metadata operations fast under churn. It also helps when the backend keeps CPU overhead low, because kubelet and the CSI node plugin compete for the same cores as the workload.
Aim for clean separation between orchestration and I/O. The attach and mount steps should complete quickly, even during bursts of reschedules, scaling events, or rolling upgrades.
🚀 Speed Up Persistent Volume Attachment Flow, Natively in Kubernetes
Use Simplyblock to reduce VolumeAttachment delays and keep attach and mount steps fast at scale.
👉 Use Simplyblock for Kubernetes Storage →
Persistent Volume Attachment Flow in Kubernetes Storage
Kubernetes drives attachment through control loops that reconcile the desired state with the actual state. When a pod lands on a node, Kubernetes and the CSI components coordinate to ensure the volume becomes usable on that node.
Most clusters follow a pattern like this:
- The scheduler assigns the pod to a node, and the kubelet starts volume preparation.
- Kubernetes creates or updates a VolumeAttachment record when the driver uses an attach step.
- The CSI controller side completes attaching or publishing work against the backend.
- The CSI node side stages the volume and publishes it into the pod, then the kubelet completes the mount.
Some backends skip a distinct attach phase and rely on node publish behavior. Others enforce attachment to prevent unsafe multi-attach and to keep fencing behavior tight during failover. Either way, the flow still has two time budgets: control-loop time and node execution time.
Persistent Volume Attachment Flow and NVMe/TCP
NVMe/TCP carries NVMe semantics over standard Ethernet. It can improve attach outcomes by keeping the connect path consistent and by lowering protocol overhead compared with older network block patterns.
The main benefit shows up during concurrency. When many pods mount at once, CPU time becomes scarce. A datapath that uses fewer CPU cycles per I/O helps kubelet and the node plugin stay responsive, which helps the attach and publish steps finish faster. This matters in disaggregated setups, SAN-alternative designs, and bare-metal clusters, where stateful services restart under load.
Queue tuning also matters. Shallow queues may cap throughput. Deep queues may inflate tail latency. The best setting depends on the app profile and the node’s CPU headroom.
Measuring Attach, Publish, and Mount Performance
Measure attachment as a timeline, not as a single event. Track the time from pod scheduled to volume mounted, then split the timeline into phases to pinpoint delays.
A practical measurement set includes:
- Pod scheduled to attach the intent created
- Attach intent to backend, attach complete
- Backend attach complete to node publish complete
- Node publish complete to pod ready
Run the same test during normal cluster activity, not only in an idle window. Attach pain often appears during rolling updates, node drains, and bursty restarts. Pair lifecycle timing with steady-state I/O tests, because a “fast attach” does not help if p99 latency spikes once the workload starts.
Approaches for Improving Attachment Performance
Use one plan that ties each change to a metric you already track, and keep it repeatable across clusters.
- Reserve CPU headroom for kubelet and CSI node components on storage-heavy workers, then validate mount time during rolling updates.
- Rate-limit disruption so large deploys do not create an attach storm that overwhelms nodes or the controller path.
- Align topology rules with the storage layout so pods land where the storage path stays short.
- Standardize mount options and filesystem choices so nodes behave the same across pools.
- Enforce multi-tenancy controls and QoS so one namespace cannot starve another in shared Software-defined Block Storage tiers.
Attachment Timeline Comparison by Architecture
This quick comparison helps teams set expectations for where time usually accumulates.
| Architecture pattern | Where time often accumulates | Typical symptom | Most effective lever |
|---|---|---|---|
| Hyper-converged | Node contention during publish | Pods wait on mount during deploys | CPU headroom, lower churn |
| Disaggregated | Network connect and discovery | Attach completes late under bursts | Transport tuning, stable paths |
| Mixed pools | Scheduling and topology mismatch | Slow restarts on specific nodes | Topology rules, pool separation |
| Multi-tenant | Noisy neighbor CPU pressure | p99 spikes during attaches | QoS, rate limits, isolation |
Simplyblock™ for Consistent Attach and Mount Timing
Simplyblock™ supports Kubernetes Storage with Software-defined Block Storage aimed at stable lifecycle behavior and efficient runtime I/O. Attachment depends on both orchestration speed and node responsiveness. When nodes stay responsive, publish and mount steps finish faster during churn.
For Ethernet NVMe deployments, simplyblock supports NVMe/TCP and uses an SPDK-based, user-space design to reduce hot-path overhead. Lower overhead helps keep CPU available for kubelet and volume operations during bursts. That matters when clusters run many stateful services, multiple tenants, and frequent reschedules.
Where Kubernetes Volume Attachment Is Heading Next
Kubernetes continues to improve volume readiness signals, topology handling, and the failure reporting around attach and mount workflows. Expect clearer phase timing and better tooling signals that point operators to the right control loop faster.
Hardware offload will also play a bigger role. DPUs and IPUs can take storage processing off host CPUs, which helps reduce jitter on busy nodes. As NVMe-oF adoption grows, NVMe/TCP should remain a common fit in Ethernet-first environments.
Related Terms
Teams often review these glossary pages alongside Persistent Volume Attachment Flow.
- Kubernetes Volume Attachment
- Kubelet Volume Manager
- CSI Controller Plugin
- Kubernetes NodeUnpublishVolume
Questions and Answers
After a PVC binds to a PV, the control plane schedules the pod, then the attach flow is driven by controller logic (and CSI sidecars, if used). Kubernetes creates/updates VolumeAttachment , and the attacher calls the storage driver to attach the volume to the selected node. Only when the driver reports success does the VolumeAttachment status flip to attached, allowing node-side mount/publish to proceed.
VolumeAttachment represents the control-plane “attach” decision and completion, not the pod’s mount readiness. Attach makes the volume reachable from the node (or validates access), while mount/publish is performed later on the node by the kubelet and the node plugin. This is why you can see attached=true the pod still stuck in ContainerCreating due to a staging/mount error.
The controller plugin handles ControllerPublish/Unpublish (attach/detach) while Kubernetes uses sidecars (like the attacher) to watch API objects and call CSI RPCs. The node plugin is not responsible for attaching, but it depends on attaching being complete, so the device path exists when it runs staging/publish. In debugging, attach failures are almost always controller/attacher/backend issues, not node mount logic.
Failures typically come from detached latency (backend still thinks the old node owns it), stale node references, or multi-attach restrictions when the volume is ReadWriteOnce. During churn, Kubernetes may try to attach to the new node before detach is finalized, causing “already attached” or “multi-attach” errors. The fix is usually to resolve stuck detach, confirm access mode semantics, and ensure the driver reports the correct attachment state quickly.
Start with pod events to confirm it’s an attach issue (not mount), then inspect VolumeAttachment status and the controller/attacher logs for the exact CSI error. If VolumeAttachment it doesn’t appear, scheduling/topology may be blocking attach creation. If it appears but never flips to attached, focus on backend connectivity/credentials, node identity mismatches, or multi-attach conflicts rather than kubelet mount steps.