SAN vs NVMe over TCP
Terms related to simplyblock
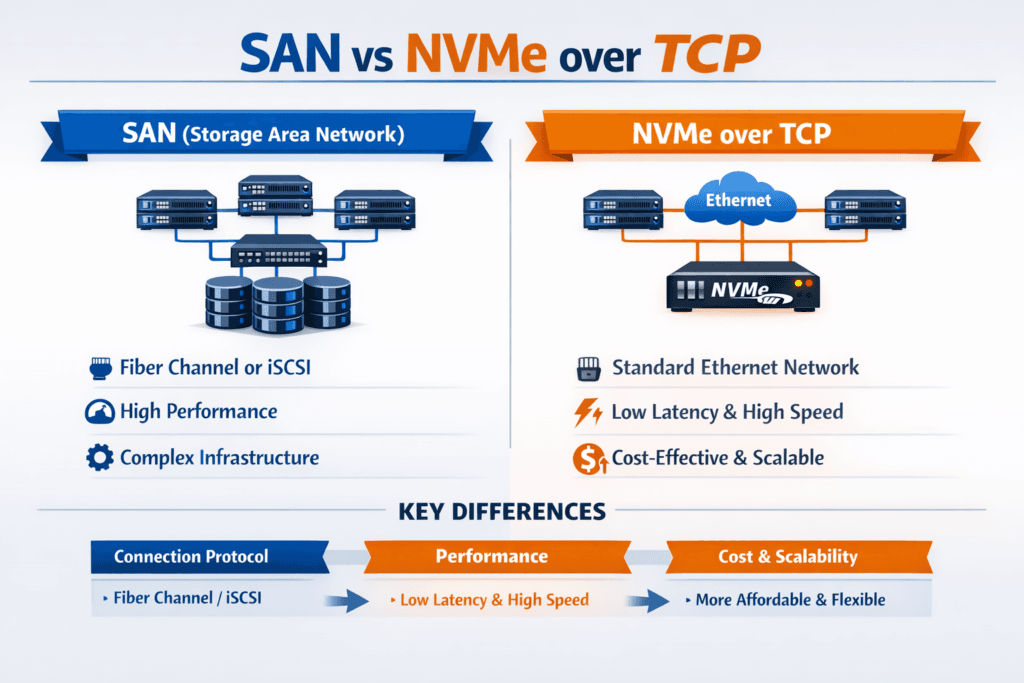
A SAN (Storage Area Network) gives servers block storage over a dedicated fabric, most often Fibre Channel or iSCSI. NVMe/TCP extends NVMe semantics across standard Ethernet using TCP/IP, which supports disaggregated designs without a specialized FC network.
Executives usually care about three outcomes: predictable latency for core apps, steady throughput for batch jobs, and an operating model that does not grow headcount with every rack. DevOps and IT Ops teams focus on day-2 work: upgrades, zoning or ACLs, multipathing, and failure handling. That’s why the comparison often lands on whether a SAN stays the best fit or whether NVMe/TCP plus Software-defined Block Storage gives the same reliability with faster scale and simpler automation.
SAN vs NVMe over TCP – What Changes in the Data Path
Traditional SANs centralize storage behind arrays and present LUNs to hosts. That model can work well, but it concentrates performance and change control in fewer systems. NVMe/TCP shifts the design toward a scale-out fabric where you can grow storage capacity and performance by adding nodes, then present volumes to hosts across Ethernet.
The protocol difference matters, too. Fibre Channel runs on a dedicated stack and tooling, while NVMe/TCP rides on IP networks; many teams already run at scale. When you pair NVMe/TCP with Software-defined Block Storage, policy and automation can replace many manual SAN workflows, especially for provisioning, isolation, and predictable QoS.
🚀 Replace Legacy SAN Friction with NVMe/TCP, Natively in Kubernetes
Use simplyblock to run Software-defined Block Storage over NVMe/TCP and standardize Kubernetes Storage at scale.
👉 Optimize Kubernetes Storage with NVMe/TCP →
SAN vs NVMe over TCP for Kubernetes Storage Teams
Kubernetes Storage changes the decision because platform teams need fast provisioning, repeatable policies, and clear multi-tenant boundaries. A classic SAN can serve Kubernetes, but many teams end up building a translation layer around it for StorageClasses, access modes, and consistent naming. NVMe/TCP can align more naturally with Kubernetes patterns when the stack ships with a CSI driver and supports fast lifecycle actions such as cloning and expansion.
If you want the comparison to reflect production, benchmark inside the cluster using real PVs and your CSI path, not a host-only test. Kubernetes scheduling, CPU limits, and noisy neighbors can move p99 latency even when the array looks “healthy.” For persistent volumes and PV concepts, Kubernetes documents the model clearly.
Simplyblock’s documentation also positions NVMe/TCP as the default transport in its NVMe-oF approach, which fits Kubernetes-first deployments that want standard networking.
How NVMe/TCP Behaves on Ethernet
NVMe/TCP performance depends on network design and CPU headroom. Jumbo frames, sane IRQ affinity, and consistent NIC queues help keep tail latency stable at higher IOPS. For many enterprises, this feels more familiar than managing an FC fabric, because it uses the same operational muscle they already apply to Ethernet networks.
When you compare against iSCSI-backed SAN designs, simplyblock’s analysis highlights meaningful gains for NVMe/TCP on the same network fabric, which supports the “SAN alternative” argument in mixed environments.
How to Compare Performance Fairly
A good comparison uses the same workload shape and the same guardrails on both sides. Keep block size, read/write mix, and queue depth consistent. Capture p95 and p99 latency, not just averages, and watch CPU use on initiators and targets.
Use this short checklist as your one listicle for the page:
- Pick two real workload profiles: one latency-first (small random I/O) and one throughput-first (large sequential I/O).
- Run tests long enough to hit steady state, then repeat at least once to confirm stability.
- Record p95 and p99 latency, IOPS, throughput, CPU, and network saturation in the same window.
- Re-test after changes such as firmware updates, CSI updates, topology shifts, or QoS policy changes.
For tooling, many teams rely on Fio because it models queue depth, block size, and mixed patterns.
SAN vs NVMe over TCP – Cost, Scale, and Risk
SAN environments often deliver strong reliability, but they can add cost and process overhead when teams expand fabrics, add ports, or refresh arrays. NVMe/TCP shifts spend toward standard Ethernet and commodity servers, which can lower barriers to scale, especially when you already run high-speed networks for east-west traffic.
Risk looks different in each model. Big arrays reduce the number of moving parts, yet they can also concentrate the blast radius. Scale-out NVMe/TCP spreads risk across nodes, and Software-defined Block Storage can add guardrails such as replication policies, failure domains, and workload isolation so one tenant does not steal another tenant’s latency budget.
Side-by-Side Decision Guide for SAN and NVMe/TCP
The table below summarizes where each approach tends to fit. Use it to frame requirements before vendor selection.
| Dimension | Traditional SAN (FC/iSCSI) | NVMe/TCP + Software-defined Block Storage |
|---|---|---|
| Network | Dedicated FC or IP storage network | Standard Ethernet TCP/IP |
| Scale model | Scale-up arrays, controlled expansion | Work often needs an extra process |
| Kubernetes fit | Work often needs extra process | Aligns well with Kubernetes Storage + CSI workflows |
| Performance focus | Strong, often array-bound | Strong, often CPU and network-tuned |
| Ops model | Zoning/LUN management, array tooling | Policy-driven automation, per-volume QoS, tenant isolation |
Why Simplyblock™ Fits the NVMe/TCP Model
Simplyblock™ focuses on Kubernetes Storage with NVMe/TCP and a Software-defined Block Storage control plane that supports multi-tenancy and QoS. The platform also leans on SPDK-style user-space acceleration to reduce datapath overhead and improve CPU efficiency, which helps keep latency steadier under concurrency.
Simplyblock™ also supports NVMe-oF concepts and networking guidance in its docs, which helps teams standardize deployments across bare metal and cloud setups without inventing new runbooks for every cluster.
What’s Next in Enterprise Block Storage Transports
More enterprises now treat NVMe/TCP as the default “high-performance Ethernet storage” transport, then reserve RDMA for the narrow slice of workloads that demand the lowest possible tail latency. NVMe/FC also remains relevant for shops that already run FC and want NVMe semantics without changing the fabric.
Over time, the decision will rely less on raw protocol speed and more on automation, isolation, and day-2 reliability under change. That pushes many teams toward Kubernetes-native control planes and policy-driven storage operations.
Related Terms
Teams often review these alongside SAN vs NVMe over TCP when they set targets for Kubernetes Storage and Software-defined Block Storage.
Questions and Answers
Traditional SANs typically rely on Fibre Channel or iSCSI with centralized architecture, while NVMe over TCP runs over standard Ethernet, enabling distributed, high-performance storage. NVMe/TCP offers lower latency and higher IOPS using commodity hardware and no need for specialized switches.
Yes, NVMe over TCP consistently delivers better performance than legacy SAN protocols like iSCSI. Benchmarks show up to 35% higher IOPS and 25% lower latency. Its ability to run on standard TCP/IP makes it ideal for scalable, modern workloads like Kubernetes storage.
For most modern workloads, NVMe over TCP is a cost-effective and high-performance alternative to Fibre Channel SANs. It removes the need for proprietary networking gear while still delivering ultra-low latency and high throughput for enterprise environments.
NVMe over TCP is better suited for Kubernetes due to its flexibility, CSI compatibility, and ability to scale with container-native workloads. SANs often require complex integration and are less dynamic compared to NVMe/TCP’s plug-and-play performance model.
Migrating from SAN to NVMe/TCP simplifies your architecture and reduces hardware dependencies. You gain higher IOPS, lower latency, and better scaling using Ethernet networks. With platforms like Simplyblock, switching is seamless and supports hybrid environments during transition.